
11868 LLM系统:分布式训练与DDP
Lec13 分布式训练
这一讲关注大规模训练中的通信问题:为什么现代 LLM 训练必须走向分布式执行、NCCL 提供了哪些关键的 collective communication primitive,以及为什么基于 AllReduce 的数据并行成为今天最主流的设计。
为什么必须做分布式训练
现代 LLM 的训练规模已经远远超出单卡能力:
- DeepSeek-V3 (671B):使用 2,048 张 H800 训练约 2 个月,总计 2.664 million H800 GPU hours
- LLaMA 3.1 (405B):使用 16,000 张 H100,总计 30.84 million GPU hours
真正推动分布式训练的,有两个同时存在的扩张趋势:
- 模型规模持续增长
- 训练数据规模持续增长
可扩展训练的主要策略
从高层看,大规模训练系统通常会组合以下一种或多种策略:
- 数据并行(Data Parallelism):复制模型,切分数据
- 参数服务器(Parameter Server):集中式维护参数更新
- 模型并行 / 张量并行(Model / Tensor Parallelism):把模型本身切开
- 流水线并行(Pipeline Parallelism):把不同层放到不同设备上
Lec13 主要讨论这样一种场景:单份模型依然能放进单张 GPU,但为了提升吞吐和缩短训练时间,需要让多张 GPU 协同训练,因此重点是数据并行。
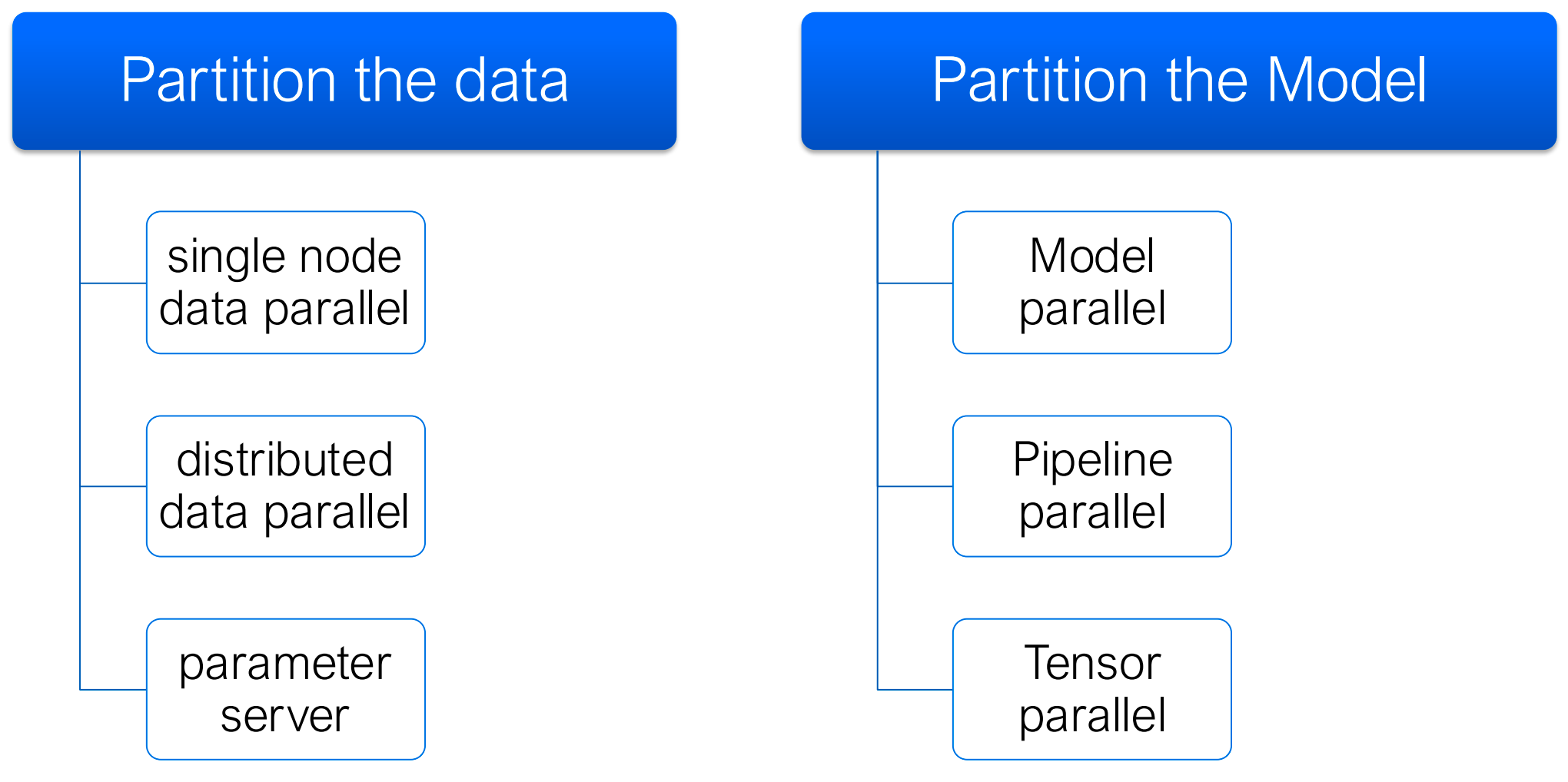
图:可扩展训练中的几类典型策略,包括数据并行、参数服务器、模型并行、流水线并行和张量并行。
经典分布式训练:参数服务器
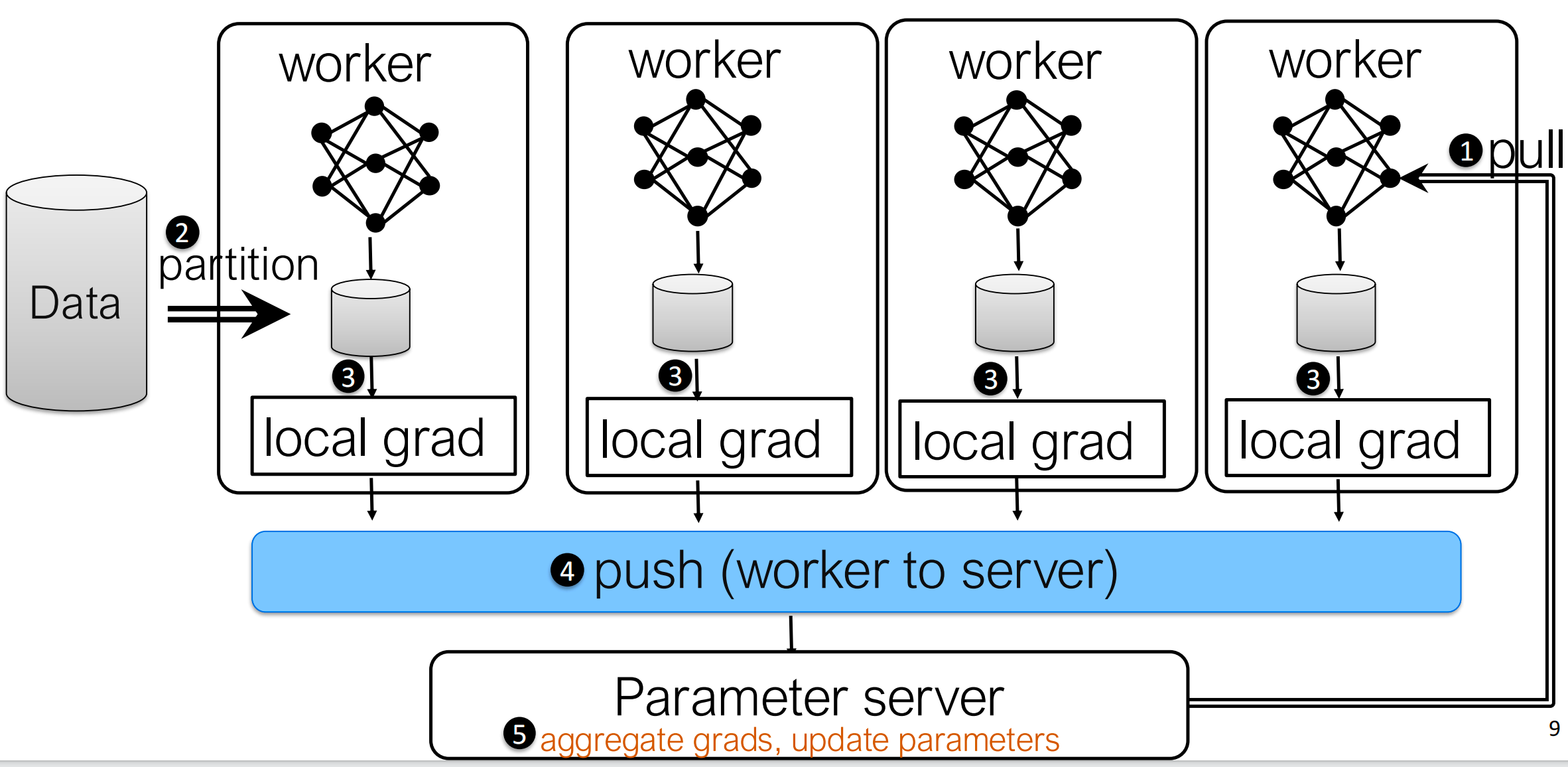
图:经典 Parameter Server 架构。工作节点负责本地前向和反向,中心服务器负责聚合梯度并更新参数。
经典的 Parameter Server 训练流程如下:
- 把 mini-batch 划分到多个 worker 上
- 每个 worker 本地执行 forward 和 backward
- worker 将本地梯度 push 到中心服务器
- 服务器聚合梯度并更新参数
- worker 再把更新后的参数 pull 回来
这个设计的概念很直接,但有两个明显问题:
- 会形成中心化瓶颈
- 每轮迭代都需要两个方向的同步:
- 梯度从 worker 发往服务器
- 参数从服务器广播回 worker
在讲义里,这套设计也可以很自然地映射到 NCCL 原语:
- 拉取参数:
Broadcast - 推送梯度:
Reduce
问题在于,worker 越多,服务器每轮需要收发的数据就越多,最终很容易成为整个系统的热点。
使用 NCCL 的多 GPU 通信
NCCL(NVIDIA Collective Communication Library)是现代多 GPU 训练系统里最核心的通信层之一。它提供:
- collective communication 原语
- point-to-point 的发送与接收
- 对多种互联方式的支持:
- PCIe
- NVLink
- InfiniBand
- IP sockets
一个很重要的系统细节是:NCCL 操作会绑定到 CUDA stream 上,因此通信可以和 GPU 上的计算协同调度,甚至做到部分重叠。
NCCL 基本原语
这一讲中出现的核心原语如下:
| 原语 | 含义 |
|---|---|
Broadcast |
从一个 root rank 把数据复制到所有 rank |
Reduce |
对所有 rank 的数据做聚合,并把结果写到一个 root rank |
AllReduce |
对所有 rank 的数据做聚合,并把结果写回每一个 rank |
ReduceScatter |
先做 reduce,再把结果分片散到各个 rank |
AllGather |
把各 rank 的分片聚合起来,并复制给所有 rank |
讲义里有一个非常关键的等式:
\[ \text{AllReduce} = \text{ReduceScatter} + \text{AllGather} \]
这不只是一个概念上的拆解,它本身就是高效 Ring AllReduce 的实现基础。
为什么 Ring 很重要
NCCL 大量使用 ring-based communication,核心原因是 ring 结构既避免了中心节点瓶颈,也能尽可能让各条链路都保持忙碌。
讲义先用 Broadcast 说明这个思想。假设有 K 个
rank,每条链路带宽为 B,消息大小为 N。
如果按单向 ring 朴素地广播:
\[ T_{\text{ring-broadcast}} = (K-1)\frac{N}{B} \]
这个代价看起来并不理想,因为完整消息必须一跳一跳传过去。
但如果把消息切成 S 个 chunk,并在 ring
中做流水化(pipeline)传输,总时间就会变成:
\[ T_{\text{pipelined}} = (K-2+S)\frac{N}{SB} \]
当 S 足够大时,它会逼近:
\[ T_{\text{pipelined}} \approx \frac{N}{B} \]
这背后的核心思想是:通过分块和流水化,把高延迟的 collective 操作转化成更接近带宽上限的传输过程。
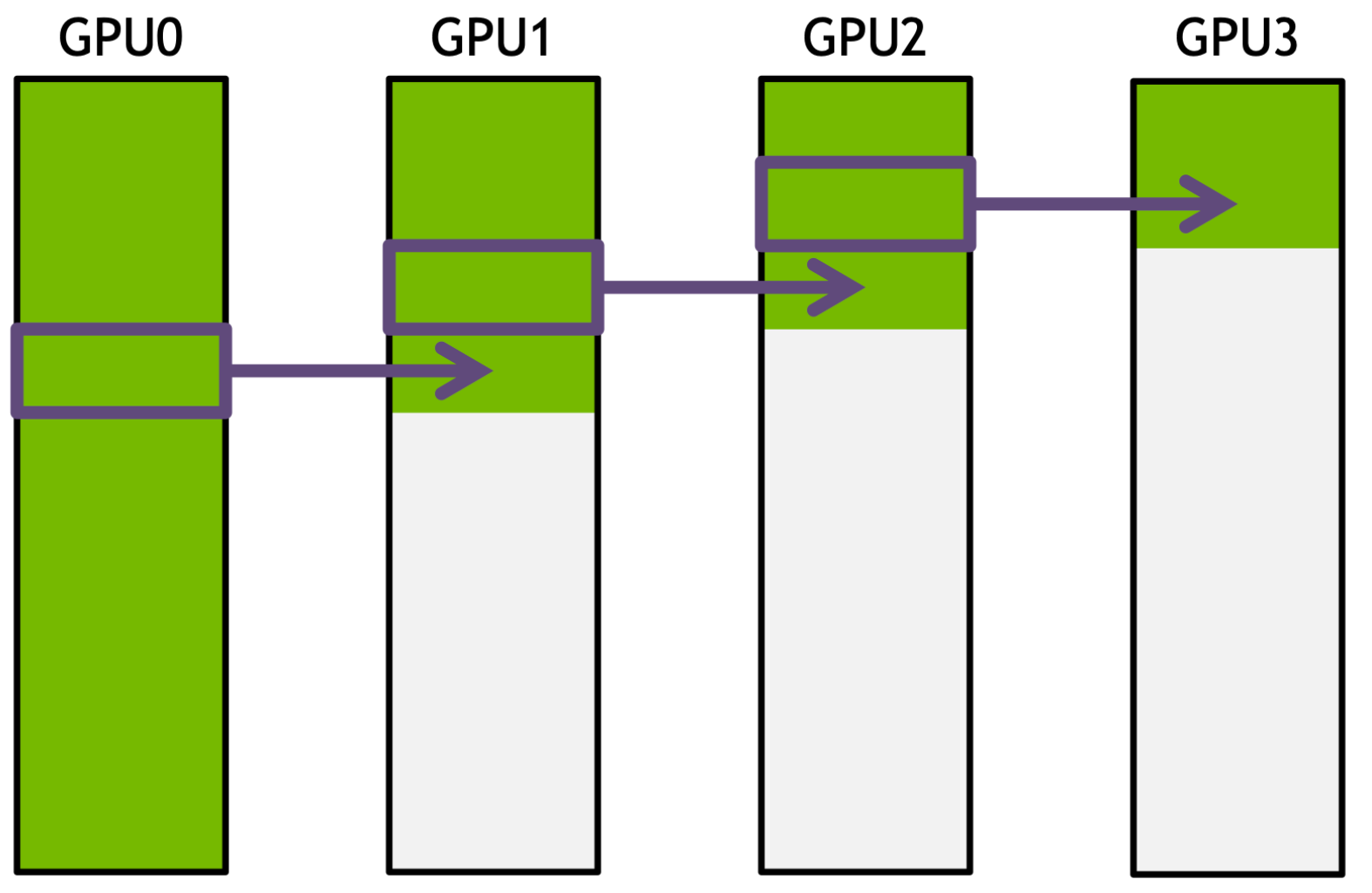
图:Ring Broadcast 在分块之后可以流水化执行,从而显著降低总耗时并更接近链路带宽上限。
分组通信
当一个进程需要同时管理多张 GPU 时,NCCL 常用如下接口:
1 | ncclGroupStart(); |
这样做的目的是把一组相关通信操作打包交给运行时统一调度。讲义中的例子同时展示了它在
communicator 初始化,以及在多设备场景下启动多个
ncclAllReduce 调用时的使用方式。
基于 AllReduce 的数据并行训练
数据并行训练的主流程非常简单:
- 把 mini-batch 分给多个 worker
- 每个 worker 在自己的数据分片上执行 forward + backward
- 多个 worker 同步梯度
- 每个 worker 都执行相同的 optimizer step
这和参数服务器最大的区别在于:这里没有一个专门负责更新参数的中心节点。每个 worker 都持有一份完整模型副本;在梯度同步之后,它们再各自执行一次完全相同的参数更新,因此所有副本依然保持一致。
为什么每张 GPU 本地更新参数是合理的
表面上看,让每张 GPU 都各自更新一次参数似乎很冗余:为什么不只更新一次,然后把新的参数再传给其他设备?
讲义给出的答案很实际:
- 本地参数更新很便宜
- 跨 GPU 传输数据很贵
因此,通常更划算的做法是:先同步梯度,再让每个 worker 在本地应用同一个更新。
Ring AllReduce
这一讲的重点是 Ring AllReduce。它是 NCCL、Horovod、PyTorch DDP 等系统中最常见的数据并行梯度同步模式。
假设现在有 K 个 worker,总梯度张量大小为
M。
阶段一:Reduce-Scatter
- 先把完整梯度切成
K个 chunk - 把所有 worker 在逻辑上连成一个 ring
- 在接下来的
K-1个 step 中:- 每个 worker 向右邻居发送一个 chunk
- 同时从左邻居接收一个 chunk
- 把收到的 chunk 累加到本地的部分结果中
完成 K-1 步之后,每个 worker 都会持有一个已经
fully reduced 的 chunk。
阶段二:AllGather
- 从 Reduce-Scatter 结束时的这些已聚合分片出发
- 再沿 ring 通信
K-1步 - 每一步转发一个已经完成聚合的 chunk
最终,每个 worker 都重新拿到完整的梯度张量。
通信代价
每一步每个 worker 只需要发送 M / K 的数据,总共会执行
2(K-1) 步,因此:
\[ \text{communication per worker} = 2(K-1)\frac{M}{K} \approx 2M \]
这也是 Ring AllReduce 的核心扩展性结论:从单个 worker
的视角看,通信量基本不随 K 增长而线性恶化,同时
ring 还能把链路负载分布得更均衡。
简化伪代码
讲义还给出了 MPI 风格的两个阶段实现。
Reduce-Scatter
1 | for i in 0 .. K-2: |
AllGather
1 | for i in 0 .. K-2: |
这些底层代码细节不是最重要的。真正值得记住的是:先让 chunk 在 ring 中一边流动一边被 reduce,再让已经完成的 chunk 在 ring 中继续传播。
参数服务器 vs AllReduce
两种方法都能完成同步,但方式不同:
| 方法 | 通信模式 | 主要限制 |
|---|---|---|
| 参数服务器 | worker 推梯度到中心节点,中心节点更新后再广播参数 | 中心化瓶颈明显 |
| AllReduce 数据并行 | worker 之间协同聚合梯度 | 每个 worker 仍需保留完整模型副本 |
这一讲的结论很明确:
- 参数服务器实现简单,但负载不均衡
- AllReduce 数据并行消除了中心热点,因此成为同步 GPU 训练中更常见的方案
Lec13 小结
- 大规模 LLM 训练无法在单卡上完成,因为模型规模和数据规模都在持续膨胀。
- NCCL 提供了现代多 GPU 训练中最核心的 collective communication primitive。
- Ring 结构之所以重要,是因为分块与流水化能更高效地利用带宽。
- 在同步训练里,数据并行通常更偏向使用 AllReduce 而不是参数服务器,因为前者避免了中心瓶颈。
Lec14 分布式数据并行训练
Lec14 从通信原语进一步走到框架实现层面。核心问题是:框架如何在尽量少改用户代码的前提下,把分布式数据并行训练做得足够高效,并尽可能把通信隐藏在反向传播过程中?
从数据并行到 DDP
当数据并行的通信模式已经明确之后,下一个问题自然就是:框架层应该怎样把它暴露给用户?
PyTorch 给出的答案是 Distributed Data Parallel(DDP)。
从概念上看,DDP 仍然属于数据并行:
- 每个进程持有一份模型副本
- 每个进程执行自己的本地 forward/backward
- 梯度会在所有进程之间同步
- optimizer 在各个进程本地执行,但结果保持一致
真正的区别在于:DDP 是对这套思路的高效工程化实现,它支持多节点、多 GPU环境,并且会主动优化通信与计算的调度顺序。
DDP 的设计目标
讲义引用了 PyTorch Distributed 论文中 DDP 的两个设计目标:
- Non-intrusive:尽量少改动本地训练脚本
- Interceptive:框架能够拦截梯度就绪事件,并在合适时机尽早触发通信
第二点是 DDP 高性能的关键。
分布式进程的组织方式
DDP 的基本执行单位是分布式 process。
讲义里强调了三个概念:
- World size:总进程数
- Global rank:整个任务中的全局进程序号
- Local rank:某个节点内部的本地进程序号
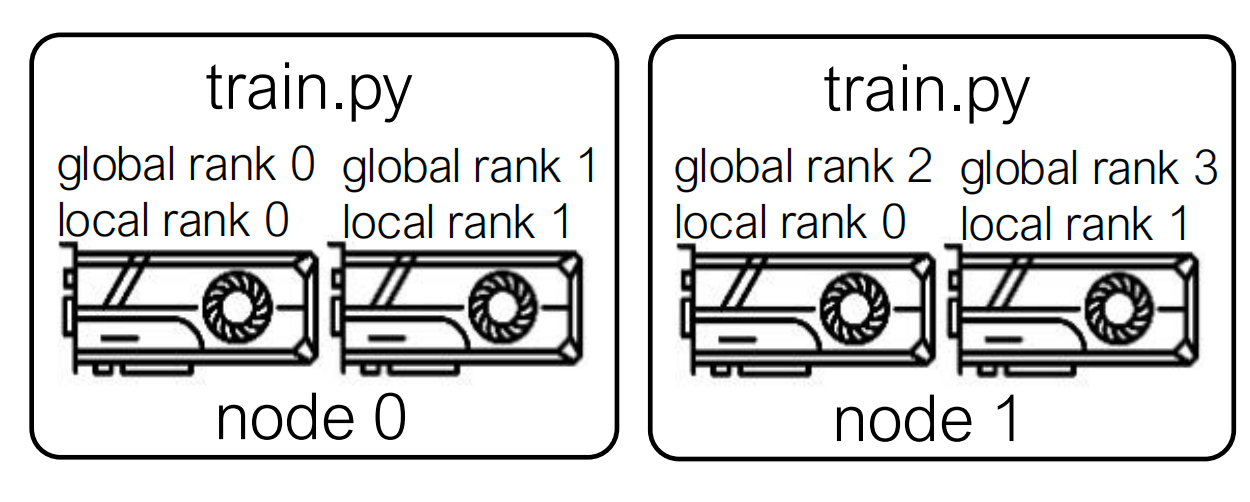
图:DDP 任务中 world size、global rank 和 local rank 的组织关系。通常一个进程绑定一张 GPU。
在多节点训练中,每台机器都会启动若干本地进程。launcher 会传入一些 process group 相关的元信息,例如:
MASTER_ADDRMASTER_PORTRANKWORLD_SIZE
之后,每个进程都会初始化分布式通信:
1 | import argparse |
一个最小的 DDP 训练骨架
讲义给出的最小使用模式如下:
1 | import torch |
在真实训练里,data loader 通常还需要做 shard,使得不同 rank 看到不同样本,但核心思路和上面是一样的。
为什么朴素的 DDP 实现不够好
一个非常直观但低效的实现方式是:
- 先跑完整个 backward
- 等所有梯度都算出来
- 再启动一次大的 AllReduce
- 最后执行 optimizer step
这样虽然是正确的,但它把以下两件事完全串行化了:
- backward computation
- communication
结果就是,GPU 一部分时间在等梯度算完,另一部分时间又在等通信结束。
梯度分桶(Gradient Bucketing)
DDP 对朴素实现的核心改进,就是 gradient bucketing。
它不会等到所有梯度都准备好,而是:
- 把参数梯度划入若干个 bucket
- 在 backward 过程中跟踪每个梯度何时就绪
- 一旦某个 bucket 的梯度都已经准备好,就立刻启动一次异步 AllReduce
这样就能把通信与后续反向传播重叠起来。
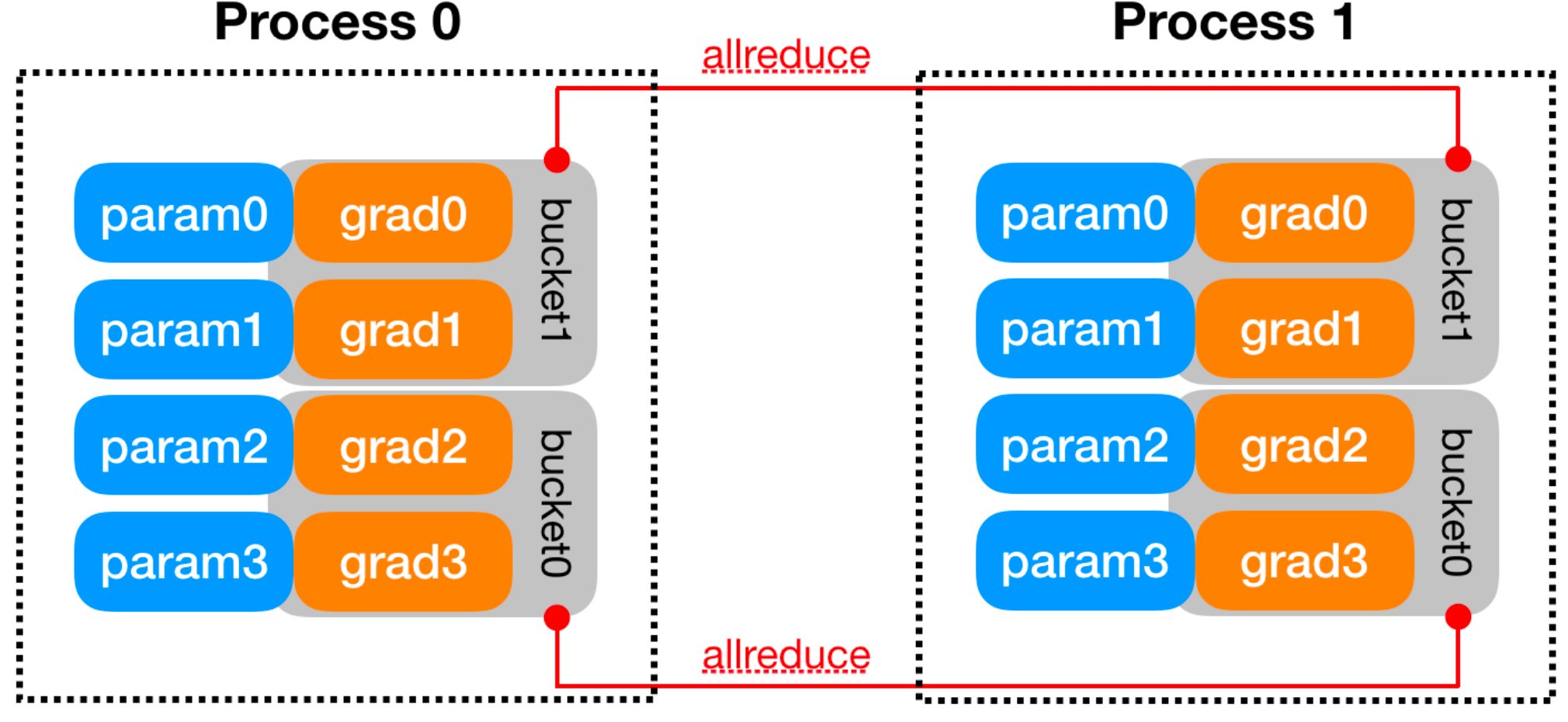
图:当一个 bucket 内的梯度全部 ready 之后,DDP 就会异步启动该 bucket 的 AllReduce。
Bucket 的构建方式
讲义里提到了几个很关键的工程细节:
- bucket 大小可以通过
bucket_cap_mb配置 - 参数到 bucket 的映射会在构造时固定下来
- 参数通常会按照
model.parameters()的近似逆序放进 bucket
之所以使用逆序,是因为反向传播时,梯度大概率会从最后一层向前一层一层准备好。这样组织 bucket,更容易让某个 bucket 早点全部 ready,从而更早触发通信。
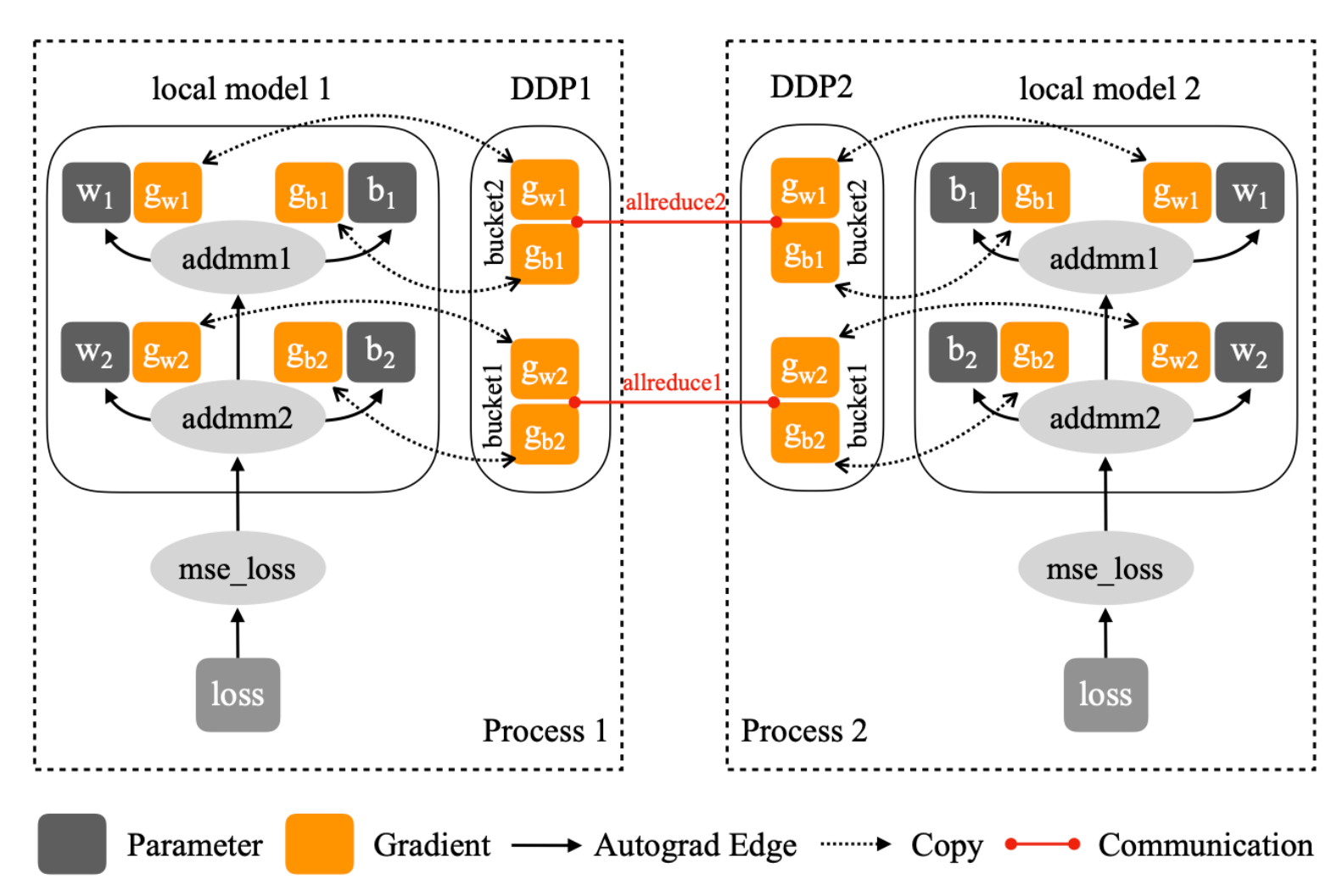
图:参数梯度在构造阶段被映射到不同 bucket 中,目标是让 backward 中的就绪顺序尽量匹配 bucket 的完成顺序。
Bucket 大小的权衡
Bucket 大小本质上是一个典型的系统权衡:
- 小 bucket
- 更容易产生重叠机会
- 但 collective 次数更多,延迟开销更高
- 大 bucket
- collective 次数更少
- 但通信和计算的重叠程度会下降
因此,DDP 的重点不只是“用了 AllReduce”,而是“以合适的粒度使用 AllReduce”。
DDP 如何拦截反向传播
DDP 的 reducer 会为每个参数注册一个 autograd hook。当某个参数的梯度被计算并累加到梯度张量中时,这个 hook 就会把它标记为 ready。
讲义中的核心逻辑可以简化为:
1 | autograd_hook(param_i): |
真实实现当然还会维护更多元数据,但关键机制就是:
- 某个参数的梯度一旦完成,就触发 hook
- hook 会减少对应 bucket 的 pending 计数
- 当 bucket 的 pending 降到 0,DDP 就立即启动这一桶的通信
讲义里展示了这条调用链上的几个函数:
autograd_hookmark_variable_readymark_bucket_readyall_reduce_bucket
这也正是 DDP “interceptive” 设计目标的具体体现。
通信与计算重叠
这部分是 DDP 最重要的性能收益来源。
在 backward 过程中:
- 靠后的层会更早产出梯度
- DDP 一旦发现某个 bucket ready,就启动它的 AllReduce
- 与此同时,更前面的层仍然继续执行 backward
因此,一轮训练的时间线不再是完全割裂的:
- backward compute
- communication
而是两者在 GPU 与网络层面上发生了部分重叠。
这会显著降低暴露出来的通信延迟,并改善扩展性。
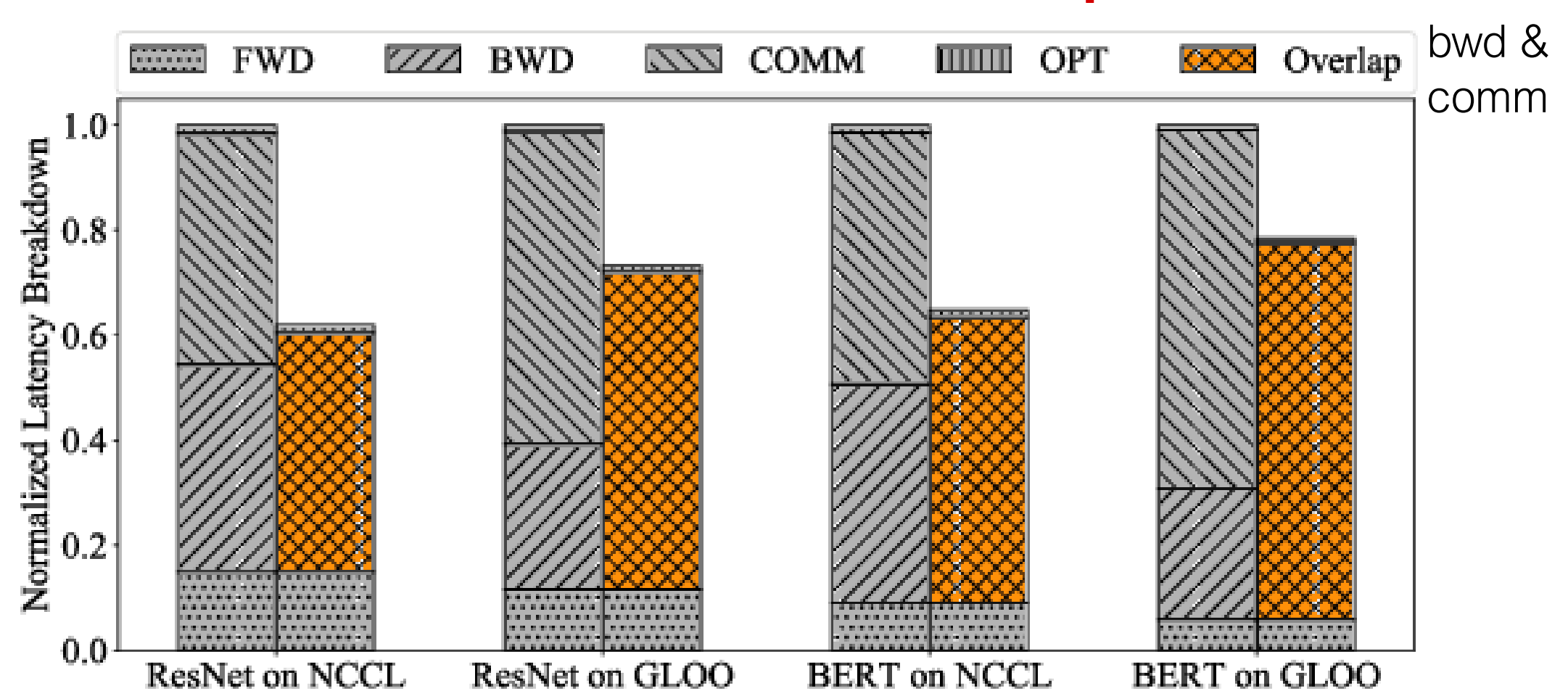
图:DDP 通过让梯度同步和反向传播并行推进,减少等待通信完成的空转时间。
DDP 真正优化的是什么
从本质上说,DDP 依然只是同步数据并行训练。它真正优化的是执行调度:
- 它不再等到所有梯度都 ready 之后才开始通信
- 它通过 bucket 减少过多的小通信操作
- 它尽可能把 collective communication 藏到 backward compute 背后
这也是为什么 DDP 会比“先 backward,再 AllReduce”的朴素实现扩展得更好。
如何理解这套栈
把 Lec13 和 Lec14 放在一起看,会更容易理解整个系统栈:
- 算法层:采用同步数据并行
- 通信层:用 Ring AllReduce 这类高效 collective 完成梯度同步
- 框架层:让用户继续写普通的 PyTorch 代码,而由 DDP 自动调度通信
这也是 DDP 在工业界和研究中被广泛采用的原因:它让用户几乎不用自己写通信代码,就能获得相当好的分布式训练性能。
DDP 的边界
DDP 只解决了扩展性问题中的一部分。
它适合的场景是:
- 单份模型仍然能放进每张 GPU
- 主要目标是通过切分数据来提升训练吞吐
它并不能解决“单份模型本身就放不下单卡”的问题。到了这种情况下,就需要更激进的技术,例如:
- 张量 / 模型并行
- 流水线并行
- ZeRO、FSDP 这类参数或优化器状态分片方法
所以,DDP 更适合被理解为:同步数据并行训练的默认工程方案,而不是大模型训练的完整终点。
Lec14 小结
- DDP 保留了数据并行的编程模型,但比朴素的 post-backward AllReduce 高效得多。
- 它最核心的优化是 gradient bucketing:一个 bucket 内梯度全部 ready 后立刻同步。
- autograd hook 让 DDP 能够在 backward 过程中尽早截获梯度完成事件。
- DDP 最大的系统收益,是把 backward compute 和 AllReduce communication 尽可能重叠起来。
全文总结
| 主题 | 核心思想 |
|---|---|
| 参数服务器 | 把更新集中化,但会形成通信热点 |
| NCCL Collectives | 提供高效的 GPU 间通信原语 |
| Ring AllReduce | 通过 ReduceScatter + AllGather 实现均衡、高效的梯度聚合 |
| 数据并行训练 | 切分数据,复制模型,统一同步梯度 |
| DDP | 通过梯度分桶与通信重叠,让数据并行训练更高效 |
核心 takeaway:分布式训练真正难的不是“让很多 GPU 同时算”,而是“让它们以尽量低的同步代价协同起来”。AllReduce 去掉了中心节点瓶颈,而 DDP 则通过 bucket 和 overlap 进一步降低了通信带来的延迟暴露。
参考资料
- Li et al. “PyTorch Distributed: Experiences on Accelerating Data Parallel Training.” VLDB 2020.
- NVIDIA NCCL collective communication primitives and programming model.
本文基于 CMU 11-868 LLM Systems 课程 Lei Li 的讲义整理(Distributed Training, Lec13;Distributed Data Parallel Training, Lec14)。


