
11868 LLM系统:解码
解码:采样、束搜索和推测性解码
关于基础概念(贪婪解码、束搜索基础、采样方法、KV缓存、计算与内存限制分析),请参见我的11711高级NLP:解码算法笔记。本文重点关注那里未涵盖的系统级细节。
高效离散采样
在每个解码步骤中,我们需要从词汇表上的分类分布中进行采样。这是一个值得优化的系统瓶颈。
采样复杂度
给定\(k\)个类别,概率为\(p_1, p_2, \ldots, p_k\),需要抽取\(n\)个样本:
| 方法 | 复杂度 | 备注 |
|---|---|---|
| 直接采样 | \(O(nk)\) | 每次线性扫描CDF |
| 二分搜索 | \(O(k + n \log k)\) | 构建一次CDF,每个样本二分搜索 |
| 别名采样 | \(O(k \log k + n)\) | 构建一次别名表,每个样本\(O(1)\) |
别名采样注意事项:别名采样的\(O(1)\)每样本优势仅在从同一分布抽取多个样本时才有效(例如蒙特卡洛模拟)。在LLM解码中,每步分布都会变化(每个分布\(n=1\)),因此别名表无法重用,每次必须以\(O(k \log k)\)的代价重建——没有任何好处。这促使了下面的Gumbel Max技巧。
在PyTorch中,标准方法是: 1
2probs = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
Gumbel Max技巧
一种更快的替代方法,完全避免计算softmax。
关键定理:从\(\text{Categorical}(\text{Softmax}(h))\)采样等价于:
\[ x_i = h_i - \log(-\log(z_i)), \quad z_i \sim \text{Uniform}(0, 1) \] \[ \text{采样的token} = \arg\max_i \; x_i \]
理论:\(x_i\)服从Gumbel分布,且\(\arg\max_i x_i\)服从\(\text{Categorical}\left(\frac{\exp(h_i)}{\sum_{j=1}^{k} \exp(h_j)}\right)\)。
为什么有用:用加法 + argmax替换softmax + 多项式采样,这对硬件更友好。Gumbel噪声可以预先计算。
1 | class GumbelSampler: |
参考:Kool等人。“随机束及其寻找方法:无重复采样序列的Gumbel-Top-k技巧。” ICML 2019。
束搜索:算法细节与剪枝
除了基本束搜索概念外,本节涵盖完整的算法实现和剪枝优化。
算法细节
带优先队列的完整束搜索过程:
1 | best_scores = [] |
关键实现细节: - 使用大小为\(k\)的最小堆优先队列——总是驱逐得分最低的候选 - EOS终止的序列被保留但阻止扩展(为所有token分配\(-\infty\),EOS除外) - 得分是累积对数概率(对数概率之和)
剪枝策略
为了减少计算,可以提前剪枝候选(Freitag & Al-Onaizan, 2017):
1. 相对阈值剪枝
给定剪枝阈值\(r_p\)和候选集\(C\),如果以下条件成立则丢弃候选\(c\):
\[ \text{score}(c) \leq r_p \cdot \max_{c' \in C} \text{score}(c') \]
2. 绝对阈值剪枝
如果以下条件成立则丢弃候选\(c\):
\[ \text{score}(c) \leq \max_{c' \in C} \text{score}(c') - a_p \]
3. 相对局部阈值剪枝
在每个扩展步骤(局部)而非全局应用阈值。
结合采样和束搜索
一种混合方法: 1. 采样前几个token(引入多样性) 2. 束搜索剩余的token(确保质量)
为什么:纯束搜索倾向于产生重复、低多样性的输出。采样初始token创建多样化的前缀,束搜索将每个前缀细化为高质量的完成。
代码示例
推测性解码:深入探讨
在基本推测性解码概念的基础上,本节详细介绍验证机制、性能权衡和对齐考虑。
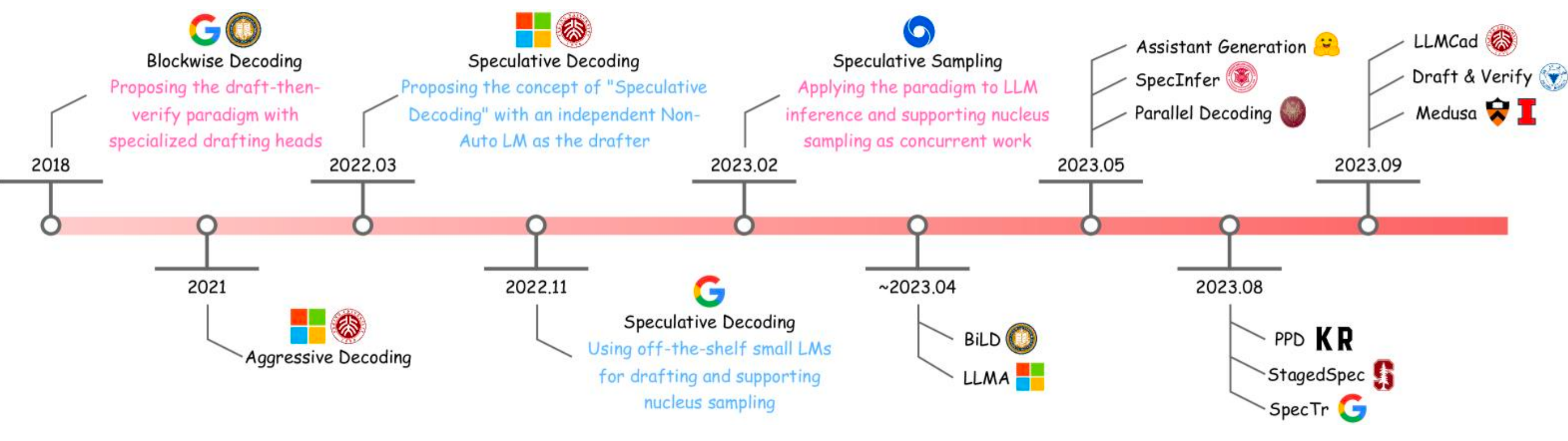
回顾核心流程:小型草稿模型\(f_{\text{draft}}\)生成\(N\)个token \(y_{1:N} \sim f_{\text{draft}}(\cdot \mid x)\),然后大型目标模型\(f_{\text{target}}\)在单次前向传递中验证它们。
验证准则
如果草稿token \(y_i\)出现在目标模型的top-\(K\)预测中,则接受:
\[ \text{接受} y_i \quad \text{如果} \quad y_i \in \text{TopK}\left(f_{\text{target}}(\cdot \mid x, y_{1:i-1})\right) \]
目标模型为每个前缀计算\(f_{\text{target}}(\cdot \mid x, y_{1:i-1})\)——但所有这些都在同一次前向传递中计算,因为因果注意力允许并行计算所有前缀位置的似然。
拒绝处理
如果草稿token \(y_i\)被拒绝,目标模型丢弃\(y_i\)和所有后续的草稿token \(y_{i+1:N}\)。然后目标模型从最后接受的位置开始生成。
最坏情况:所有\(N\)个token被拒绝→退回到正常的自回归解码(没有质量损失,只是浪费了草稿计算)。
为什么更快?
关键洞察:验证\(N\)个token比生成\(N\)个token更便宜。
- 生成\(N\)个token:目标模型的\(N\)次顺序前向传递
- 验证\(N\)个token:目标模型的1次前向传递(因果注意力同时计算所有位置的似然)
草稿模型的前向传递很便宜(小模型)。所以总成本大约是:\(N\)次便宜的草稿传递 + 1次昂贵的目标传递,相比\(N\)次昂贵的目标传递。
选择\(N\)(草稿长度)
| 大\(N\) | 小\(N\) |
|---|---|
| ✅ 更高的理论加速 | ✅ 更低的拒绝成本 |
| ❌ 更高的拒绝概率 | ❌ 更少的并行化收益 |
| ❌ 更多的softmax计算(内存压力) | ✅ 更低的内存开销 |
| ❌ 实时应用的停顿时间更长 | ✅ 更适合交互使用 |
流行选择:\(N = 4\)或\(N = 8\)。
对齐考虑
草稿-目标对齐(草稿模型近似目标的程度)至关重要: - 良好对齐→低拒绝率→高加速 - 差对齐→频繁拒绝→加速被抵消
最佳实践:从同一模型家族选择草稿和目标模型(例如,LLaMA-7B为LLaMA-70B起草)。
实证结果
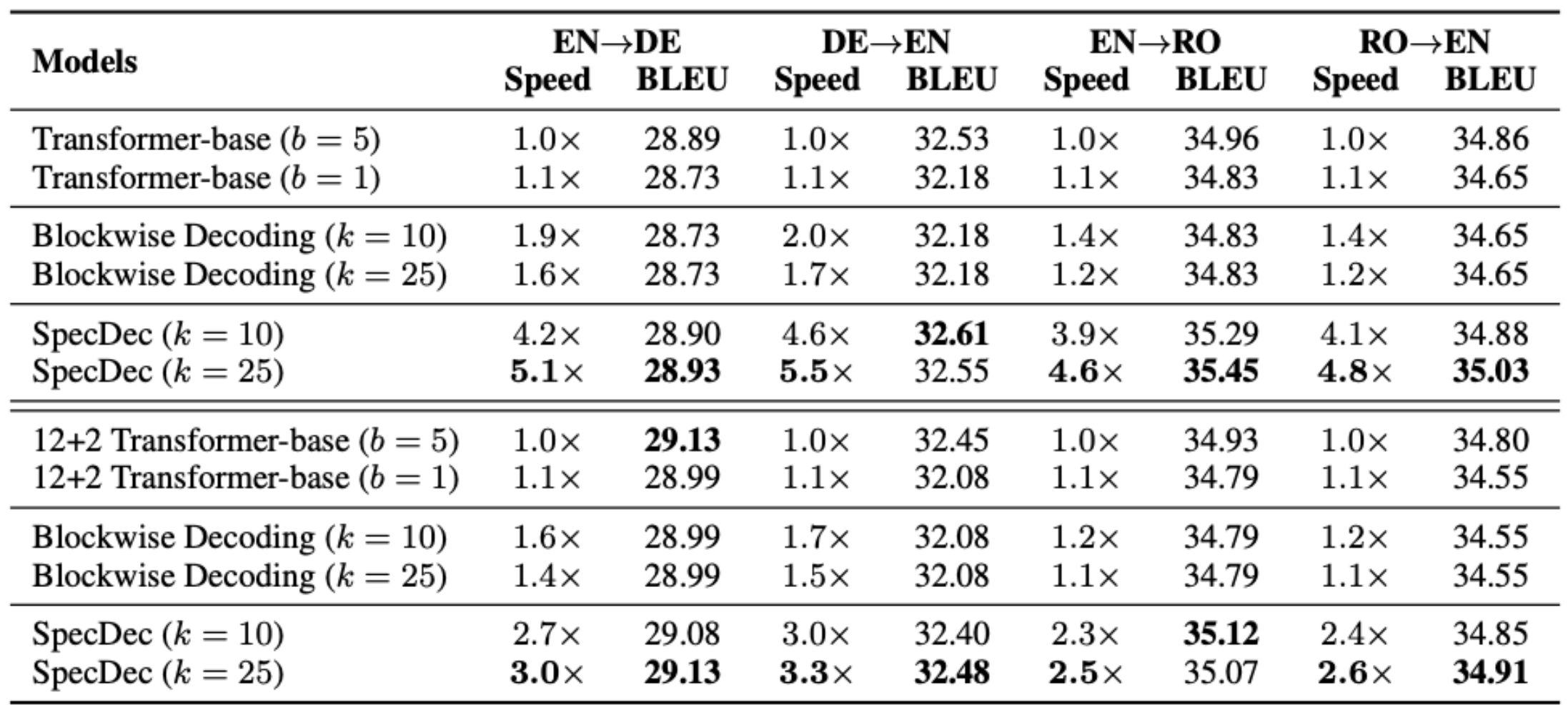
推测性解码已被证明: - 生成与标准自回归解码质量相当的文本 - 实现显著的时钟加速(通常为2-3倍),具体取决于草稿-目标对齐
EAGLE:更大语言模型效率的外推算法
EAGLE通过一个关键观察改进了普通推测性解码:预测下一个token的最终层特征比预测下一个token本身更容易。
动机
普通推测性解码使用单独的小型LM作为草稿模型,它预测下一个token。但从完整词汇表预测离散token是困难的。EAGLE转而使用单个Transformer层预测下一个最终层特征向量,然后应用原始模型的LM head来获得token预测。
架构
EAGLE重用原始LLM的两个组件: - 嵌入层(token → 向量) - LM head(特征 → logits)
它添加一个小型Transformer层,其输入为: - token嵌入\(e_t\)和目标模型的最终层特征\(f_t\)的拼接
并输出预测的特征\(\hat{f}_{t+1}\),LM head从中产生token预测。
为什么嵌入 + 特征? 采样的token强烈影响最终层特征。例如,在”I am”之后,“excited”和”begin”的特征非常不同。token嵌入捕获这种离散选择,而最终层特征捕获上下文表示。

树结构起草
EAGLE不是生成单一的线性草稿token链,而是生成候选继续的树:
1 | "How can" |
实现使用树注意力:将所有候选展平为单个序列,使用树形注意力掩码,允许高效的并行计算。
训练
EAGLE的草稿层使用组合损失训练:
\[ L = L_{\text{reg}} + w_{\text{cls}} \cdot L_{\text{cls}} \]
回归损失(特征预测): \[ L_{\text{reg}} = \text{SmoothL1}\left(f_{i+1}, \; \text{DraftModel}(T_{2:i+1}, F_{1:i})\right) \]
其中\(T_{2:i+1}\)是token嵌入,\(F_{1:i} = (f_1, \ldots, f_i)\)是目标模型特征。
分类损失(token预测): \[ L_{\text{cls}} = \text{CrossEntropy}\left(p_{i+2}, \; \hat{p}_{i+2}\right) \]
其中\(p_{i+2} = \text{Softmax}(\text{LMHead}(f_{i+1}))\)和\(\hat{p}_{i+2} = \text{Softmax}(\text{LMHead}(\hat{f}_{i+1}))\)。
结果
EAGLE在MT-Bench上实现了比普通推测性解码显著更快的解码,质量退化极小。
进一步改进
- EAGLE-2:在草稿树中剪枝低置信度token,减少浪费的计算
- EAGLE-3:将方法扩展到更大的训练数据集以获得更好的草稿质量
代码
总结
| 方法 | 类型 | 关键思想 |
|---|---|---|
| Gumbel Max技巧 | 高效采样 | 用加法 + argmax替换softmax + 多项式 |
| 束搜索剪枝 | 搜索优化 | 提前丢弃低分候选 |
| 推测性解码 | 加速 | 便宜起草,并行验证 |
| EAGLE | 改进推测 | 预测特征而非token,树结构草稿 |
关键要点:从系统角度来看,LLM解码的瓶颈是自回归生成的顺序、内存限制性质。推测性解码和EAGLE通过将串行生成转换为并行验证来解决这个问题——基本洞察是验证比生成更便宜(使用因果注意力)。
参考文献
- Freitag & Al-Onaizan。“神经机器翻译的束搜索策略。” 2017。
- Kool等人。“随机束及其寻找方法:无重复采样序列的Gumbel-Top-k技巧。” ICML 2019。
- Leviathan等人。“通过推测性解码实现Transformer的快速推理。” ICML 2023。
- Li等人。“EAGLE:推测性采样需要重新思考特征不确定性。” ICML 2024。
本文基于CMU 11-868 LLM系统课程(Lei Li教授)的讲座材料。

