
11711 Advanced NLP: Quantization
Lec19 量化
本讲解决一个核心部署问题:现代 LLM 太大,无法在消费级硬件上运行。量化通过减少每个权重所用的比特数来大幅缩减内存需求,同时尽可能保留模型质量。
动机
核心问题很直观:模型太大了。
以 Qwen3-8B 为例: - 80 亿参数 × 16 位(BFloat16)= 16 GB(仅权重) - 推理时激活值约需 ~1.5× 开销 → 总计约 ~24 GB - MacBook Air(16 GB 共享内存)必须换页到磁盘才能运行 - T4 GPU(16 GB 显存)直接内存溢出
量化提供了直接的解决方案:用更少的位数表示每个权重。Qwen3-8B 的 4-bit 量化版本仅需 ~6 GB,两种设备都能轻松容纳。
计算机中的数值表示
在理解量化之前,需要先了解数字的存储方式。
无符号整数
每一位代表 2 的某次幂。8 位无符号整数(U8)将各位为 1 的位置对应的幂次求和:
\[ 01010110_2 = 1 \times 2^6 + 1 \times 2^4 + 1 \times 2^2 + 1 \times 2^1 = 64 + 16 + 4 + 2 = 86 \]
| 类型 | 位数 | 范围 |
|---|---|---|
| U8 | 8 | 0 到 255 |
| U16 | 16 | 0 到 65,535 |
| U32 | 32 | 0 到 4,294,967,295 |
有符号整数
最左位用作符号位。负数使用补码表示:将所有位取反再加 1。
- INT8:8 位,范围 [-128, 127]
- INT16、INT32 同理,范围更大
浮点数
浮点数使用三个部分来表示实数值:符号位、指数和尾数(significand):
\[ \text{value} = (-1)^{\text{sign}} \times (1.\text{significand}) \times 2^{\text{exponent} - \text{bias}} \]
偏置(bias)使指数可以作为无符号整数存储。本质上就是二进制的科学计数法:\(1.101 \times 2^3 = (1 + 0.5 + 0.125) \times 8 = 13\)。
计算示例(Float32):
| 符号位 | 指数(8 位) | 尾数(23 位) |
|---|---|---|
| 0 | 10000001 = 129 | 01100…0 |
- 指数 − 偏置:\(129 - 127 = 2\)
- 尾数:\(1 + 0 \times 2^{-1} + 1 \times 2^{-2} + 1 \times 2^{-3} = 1.375\)
- 值:\(1.375 \times 2^2 = 5.5\)
浮点数类型
| 格式 | 总位数 | 符号位 | 指数 | 尾数 |
|---|---|---|---|---|
| Float32(全精度) | 32 | 1 | 8 | 23 |
| Float16(半精度) | 16 | 1 | 5 | 10 |
| BFloat16 | 16 | 1 | 8 | 7 |
BFloat16 是一个值得注意的设计选择:它保留了与 Float32 相同的指数范围(因此能表示相同量级的数值),但牺牲了尾数精度。这使得 BFloat16 与 Float32 之间的转换非常简单(只需在尾数后补零),并在训练过程中避免溢出问题,代价是相近数值之间的精度较低。大多数现代 LLM(如 Qwen3-8B)以 BFloat16 格式存储权重。
推理量化
什么是量化?
量化是将大集合中的值映射到小集合中的过程。最简单的例子:将实数四舍五入到最近的整数。
\[ Q(x) = \text{round}(x) \]
量化误差是原始值与量化值之间的差。例如,\(Q(1.4) = 1\)(误差 = 0.4),\(Q(0.8) = 1\)(误差 = 0.2)。
为什么要量化 LLM?
在大型 Transformer 中,前馈层和注意力投影层占 ~95% 的参数和 65-85% 的计算量(Ilharco et al., 2020)。目标是: 1. 将这些参数量化到更少的位数(如 BFloat16 → INT8 或 INT4) 2. 使用低位精度矩阵乘法 3. 减少内存以便大模型能在消费级硬件上运行
8 位量化:Absmax
Absmax 量化使用绝对最大值将整个输入张量缩放到 INT8 范围 \([-127, 127]\):
\[ X_{i8} = \text{round}\left(\frac{127 \cdot X_{f16}}{\max_{ij}(|X_{f16_{ij}}|)}\right) \]
缩放因子为 \(s = \frac{127}{\max(|X|)}\)。反量化时只需除以缩放因子。
1 | import numpy as np |
Absmax 的矩阵乘法使用逐向量量化:分别量化 \(X\) 的每一行和 \(W\) 的每一列,在 INT8 下相乘(累加到 INT32),然后反量化:
\[ XW = \frac{1}{s_x s_w} Z_{i32} \approx \frac{1}{s_x s_w} Q(X) Q(W) \]
8 位量化:Zero-Point
Zero-point 量化将浮点范围 \([\min, \max]\) 映射到完整的 INT8 范围 \([-128, 127]\),同时使用缩放因子和偏移量:
\[ \text{INT8} = \text{round}(s \cdot \text{FP}) + \text{offset} \]
其中:
\[ s = \frac{255}{\max - \min}, \quad \text{offset} = -\text{round}\left(\frac{255}{\max - \min} \cdot \min\right) - 128 \]
反量化:
\[ \text{FP} = \frac{\text{INT8} - \text{offset}}{s} \]
Zero-point 量化更适合非对称数据(如 ReLU 之后的激活值,全为非负)。Absmax 在这种情况下会浪费一半的整数范围在永远不会出现的负值上。
离群值问题
两种方法都基于张量的最小/最大值进行归一化。当存在离群值时,缩放因子被极端值主导,导致其他所有值挤压到整数范围的很小一部分。
| 场景 | Absmax MSE | Zero-Point MSE |
|---|---|---|
| 无离群值 | 0.000001 | 0.000001 |
| 有离群值(100.0) | 0.060013 | 0.014756 |
单个离群值就能使误差增大 4-5 个数量级。这并非理论上的担忧——真实的 Transformer 语言模型确实存在系统性的离群值特征。
LLM.int8()(Dettmers et al., 2022)
Dettmers 等人观察到 Transformer 语言模型会产生离群值特征:激活矩阵中某些列的值远大于其他列。在参数量 \(\geq\) 67 亿的模型中,100% 的层都存在离群值。朴素的 8 位量化在这个规模上会崩溃——准确率急剧下降。
关键洞察:仅有 ~0.1% 的激活特征是离群值。因此解决方案是混合精度分解:
- 识别激活中的离群值列(绝对值超过阈值的列)
- 从 \(X\) 中提取离群值列及 \(W\) 中对应的行
- 离群值部分在 FP16 下计算(高精度)
- 常规部分在 INT8 下计算(低精度,逐向量 absmax)
- 合并两部分结果
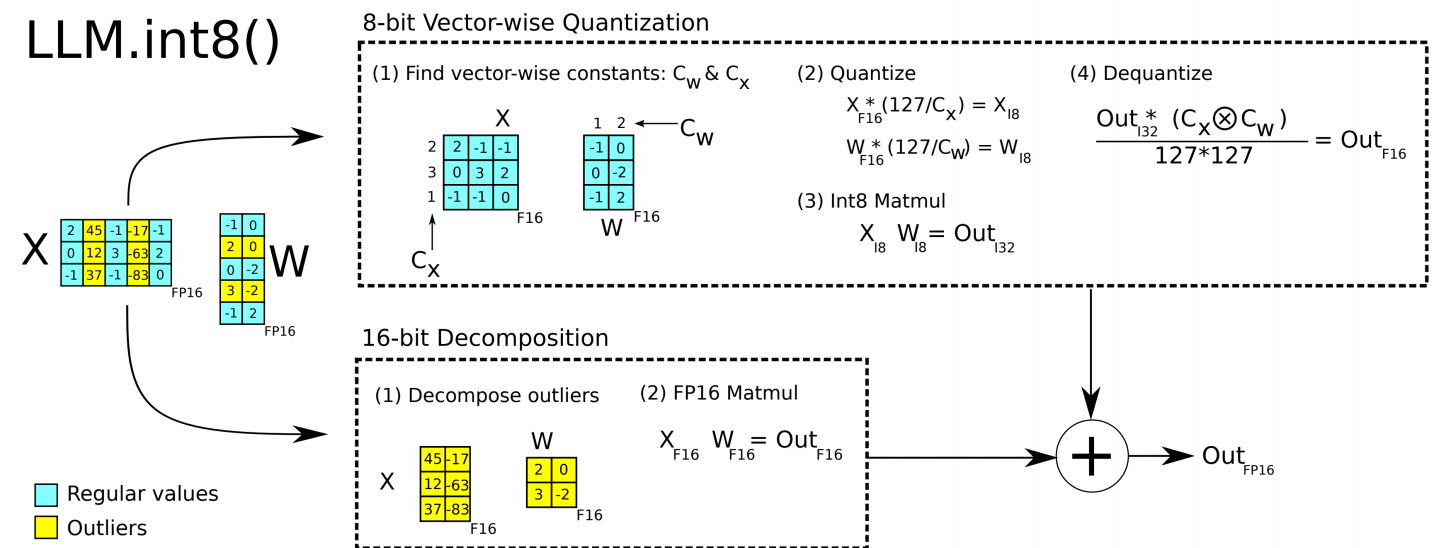
该方法在所有测试的模型规模(最大 175B 参数)上都达到了与 FP16 基线匹配的精度,而朴素 8 位基线在 6.7B 之后急剧退化。
| 方法 | 125M | 1.3B | 2.7B | 6.7B | 13B |
|---|---|---|---|---|---|
| 32-bit Float | 25.65 | 15.91 | 14.43 | 13.30 | 12.45 |
| Int8 absmax | 87.76 | 16.55 | 15.11 | 14.59 | 19.08 |
| Zeropoint LLM.int8() | 25.69 | 15.92 | 14.43 | 13.24 | 12.45 |
(验证集困惑度——越低越好)
GGML/GGUF/Llama.cpp
GGML 是一个张量运算库,拥有自己的量化方法,专为高效的 CPU 和 GPU 推理设计。
以量化方案 Q4_K 为例: - 将权重分组为超级块,每个超级块包含 8 个块,每个块有 32 个权重 - 每个权重存储为 4 位 - 每块的缩放因子和偏移量存储为 6 位
两个常用预设: - Q4_K_S:所有张量使用 Q4_K(更小,精度略低) - Q4_K_M:某些注意力和 FFN 张量的一半使用更高精度的 Q6(质量更好)
GGML 支持多种后端:Metal(Apple Silicon)、ARM、CUDA 等。
GGUF 是存储模型架构和量化权重的文件格式。Llama.cpp 是基于 GGML/GGUF 构建的推理库,支持本地 LLM 推理:
1 | llama-server -hf Qwen/Qwen3-8B-GGUF:Q4_K_M --port 8080 |
Qwen3-8B-GGUF 文件大小示例:
| 量化方式 | 位数 | 大小 |
|---|---|---|
| Q4_K_M | 4 | 5.03 GB |
| Q5_K_M | 5 | 5.85 GB |
| Q6_K | 6 | 6.73 GB |
| Q8_0 | 8 | 8.71 GB |
同一模型中不同张量可以使用不同的量化级别。例如在 Q4_K_M 中,归一化权重保持 F32,而注意力和 FFN 权重使用 Q4_K 或 Q6_K。
超越整数:NVFP4
新的硬件原生数据类型正在涌现。NVFP4 是一种 4 位浮点格式(E2M1:1 位符号、2 位指数、1 位尾数),随 NVIDIA Blackwell 架构引入。它使用: - 逐块缩放,每 16 个值一个 FP8(E4M3)缩放因子 - 逐张量缩放,使用 FP32 进行全局归一化
这将量化从纯整数推向低位浮点,更好地保留了权重值的分布。
量化与训练
量化感知训练(QAT)
训练后量化(PTQ)在预训练完成后直接对模型进行量化,无需额外训练。量化感知训练(QAT)则采用不同策略:在模拟量化的条件下微调模型,使权重学会对量化误差的鲁棒性。
核心机制是在前向传播中插入伪量化-反量化操作:
1 | # QAT: x_fq is still in float, but has been through quantize + dequantize |
模型在全精度下训练,但在前向传播中”感知”量化噪声,从而学习到在实际量化时更具鲁棒性的权重配置。推理时,伪量化节点被替换为真正的量化操作。
QAT 在各种位宽下始终优于 PTQ,尤其是在更低位宽时。例如,Kimi-K2-Thinking 在后训练阶段使用 QAT 实现原生 INT4 量化,在低延迟模式下达到了无损的 2 倍加速。
微调:QLoRA(Dettmers et al., 2023)
QLoRA 将量化与 LoRA 结合,大幅减少微调所需的 GPU 内存:
| 组件 | LoRA | QLoRA |
|---|---|---|
| 基础模型 | 16 位 | 4 位 |
| 适配器 | 16 位 | 16 位 |
| 优化器状态 | 32 位(GPU) | 32 位(CPU,分页) |
核心思路: 1. 4-bit NormalFloat(NF4):使用针对正态分布权重优化的数据类型,将冻结的基础模型量化到 4 位 2. 双重量化:对量化常数本身也进行量化,进一步节省内存 3. 分页优化器:将优化器状态卸载到 CPU 内存,仅在需要时分页加载到 GPU
这使得在单张 48GB GPU 上微调 650 亿参数的模型成为可能——否则需要多张高端 GPU。
Lec19 要点总结
- 量化是部署的关键:从 16 位降到 4 位可将模型大小缩减约 4 倍,使数十亿参数的模型能在消费级硬件上运行
- 离群值会破坏朴素量化:Transformer 语言模型在规模增大时会产生系统性离群值特征;混合精度分解(LLM.int8())通过对约 0.1% 的离群值特征使用高精度来解决这一问题
- 格式多样性在增长:从基于整数的(INT8、INT4)到浮点的(NVFP4、FP8),硬件协同设计推动着新格式的发展
- QAT 优于 PTQ:在训练中引入量化噪声使模型在实际量化时退化更小
- QLoRA 让微调平民化:将 4 位量化与 LoRA 和内存分页结合,使大模型微调在普通硬件上成为可能
总结
| 主题 | 核心思想 |
|---|---|
| 数值表示 | Float32/16、BFloat16 在精度和范围间权衡;BFloat16 保留 Float32 的指数范围 |
| Absmax 量化 | 按绝对最大值缩放映射到 [-127, 127];简单但对离群值敏感 |
| Zero-point 量化 | 使用缩放因子和偏移量映射完整范围;更适合非对称分布 |
| LLM.int8() | 混合精度:离群值特征(~0.1%)用 FP16,其余用 INT8 |
| GGML/Llama.cpp | 基于块的量化(Q4_K、Q6_K),逐块缩放;支持 Metal/CUDA |
| QAT | 训练时插入伪量化-反量化操作,学习对量化鲁棒的权重 |
| QLoRA | 4 位基础模型 + 16 位 LoRA 适配器 + CPU 分页优化器实现高效微调 |
核心要点:量化不仅仅是部署优化——它是 LLM 生命周期中的一等考量,方法横跨推理(PTQ、LLM.int8())、训练(QAT)和微调(QLoRA),每种方法都在模型大小与质量之间的根本权衡中寻找平衡。
参考文献
- Dettmers et al., “LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale,” 2022
- Dettmers et al., “QLoRA: Efficient Finetuning of Quantized Language Models,” 2023
- Ilharco et al., “High Performance Natural Language Processing,” 2020
- GGML / Llama.cpp: github.com/ggml-org/llama.cpp
- NVIDIA, “Introducing NVFP4 for Efficient and Accurate Low-Precision Inference”
- HuggingFace Quantization Overview: huggingface.co/docs/transformers/quantization/overview
本文基于 CMU 11-711 Advanced NLP 课程资料,由 Sean Welleck 讲授(Lecture 19: Quantization)。

