
11711 Advanced NLP: Multimodal Modeling
Lec11 多模态建模 I(Multi-to-Text)
全局视角
这部分课程重点是 multi-to-text:
- 输入可以是图像(也可以带文本)。
- 输出是文本。
- 核心问题是:如何把图像映射成语言模型可消费的向量序列。
把图像表示为“token”
文本我们已有 token embedding。
图像则需要一个编码器: \[
f_{\text{enc}}(x_{\text{image}}) \rightarrow z_1,\dots,z_L
\] 其中每个 \(z_i\) 都是一个向量
token。
Vision Transformer(ViT)
ViT 的思路是把图像切成 patch,线性映射为向量,再送入标准 Transformer。
给定: \[ x_{\text{image}} \in \mathbb{R}^{H \times W \times C} \]
按 \(P \times P\) 划分 patch: \[ N=\frac{HW}{P^2}, \quad x_p \in \mathbb{R}^{N \times (P^2C)} \]
投影到模型维度 \(D\): \[ x = x_p W_e, \quad W_e \in \mathbb{R}^{(P^2C)\times D}, \quad x \in \mathbb{R}^{N\times D} \]
再加位置编码并通过 Transformer。


课程中的直觉总结:
- 浅层更偏局部结构信息。
- 深层更偏全局语义区域。
- ViT 随预训练算力扩大有良好的扩展性。
CLIP:用语言监督学习视觉表示
CLIP(Radford et al., 2021)在共享嵌入空间中联合学习图像与文本。
- 图像编码器:\(f_I(x)\)
- 文本编码器:\(f_T(y)\)
- 配对图文应接近,不配对应远离。
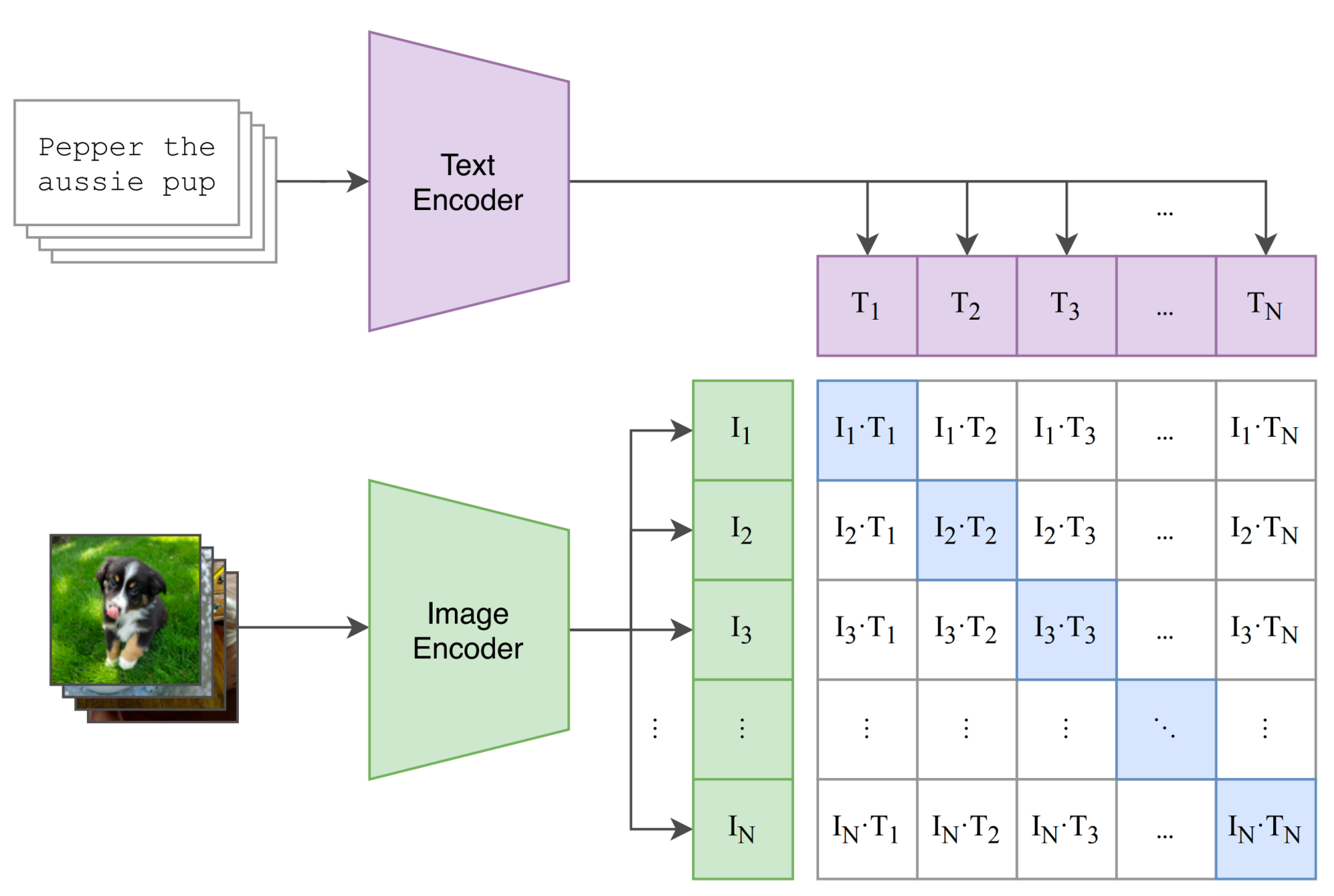
对一个 batch 中 \(N\) 对样本 \((x_n,y_n)\),定义相似度: \[ s_{ij}=\frac{f_I(x_i)^\top f_T(y_j)}{\tau} \]
对称对比学习目标: \[ \mathcal{L}_{\text{img}}=-\frac{1}{N}\sum_{i=1}^N \log \frac{e^{s_{ii}}}{\sum_j e^{s_{ij}}}, \quad \mathcal{L}_{\text{text}}=-\frac{1}{N}\sum_{i=1}^N \log \frac{e^{s_{ii}}}{\sum_j e^{s_{ji}}} \] \[ \mathcal{L}_{\text{CLIP}}=\frac{1}{2}\left(\mathcal{L}_{\text{img}}+\mathcal{L}_{\text{text}}\right) \]
它的重要性在于:
- 用自然语言描述替代“仅类别标签”的弱监督。
- 可扩展到 web 规模图文数据。
- 零样本迁移能力强。
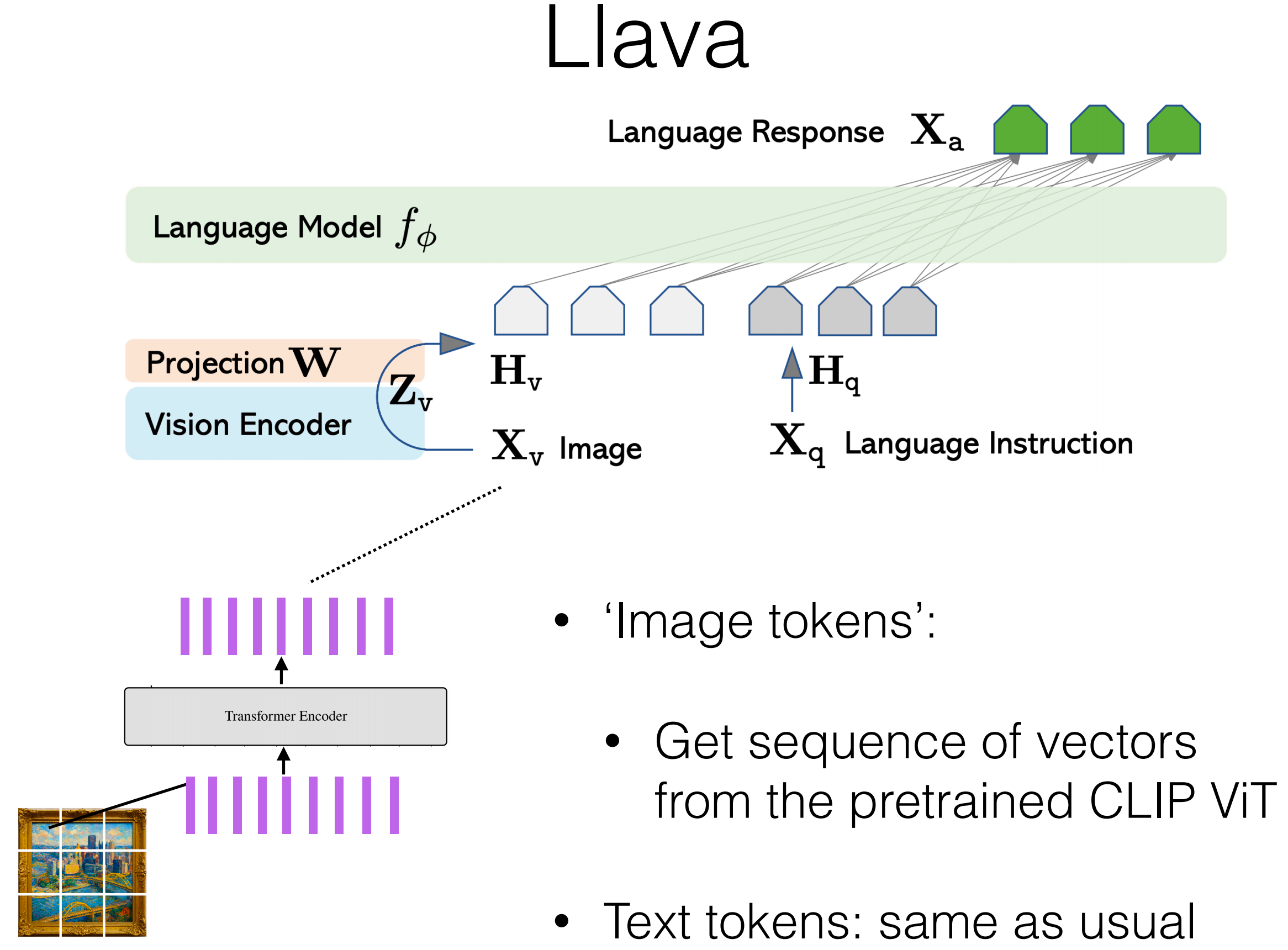
与语言模型结合:LLaVA 风格
课程给出的通用 pipeline:
- 图像预处理(patch/crop)。
- 用视觉编码器提取特征(常见是 CLIP ViT)。
- 线性映射到 LM 的 embedding 维度。
- 将视觉 token 与文本 token 拼接。
- 用图文指令数据训练/微调。
- 图像位置不计算 token-level LM loss。
可写成: \[ h_v=\text{Proj}(f_I(x_{\text{image}})), \quad p_\theta(y_t\mid y_{<t},x_{\text{text}},h_v) \]
课程中提到的系统案例
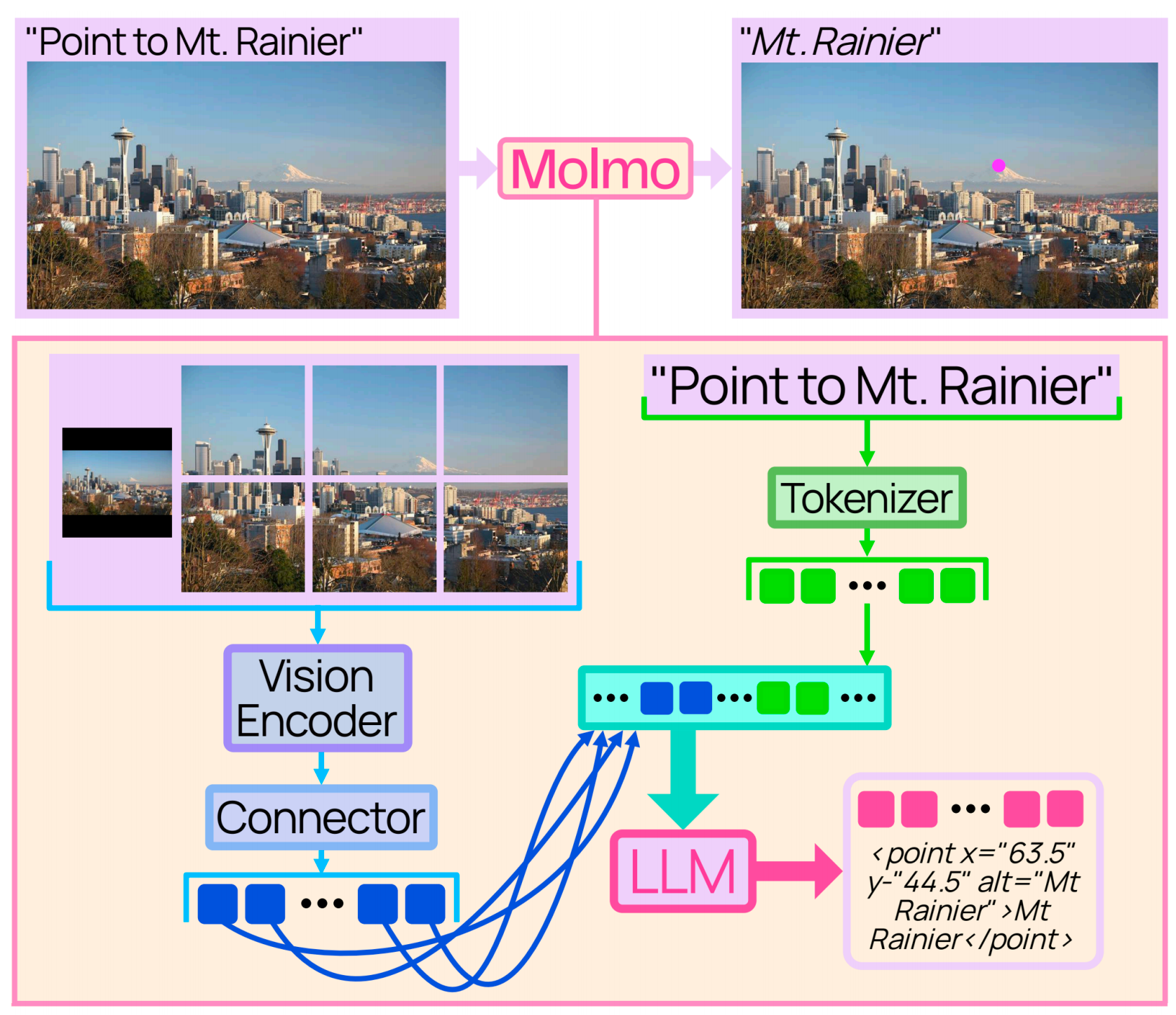
- Molmo(AI2): 使用 CLIP ViT-L/14(336px),经 pooling 和投影后送入 LLM,并结合全图和裁剪视图。
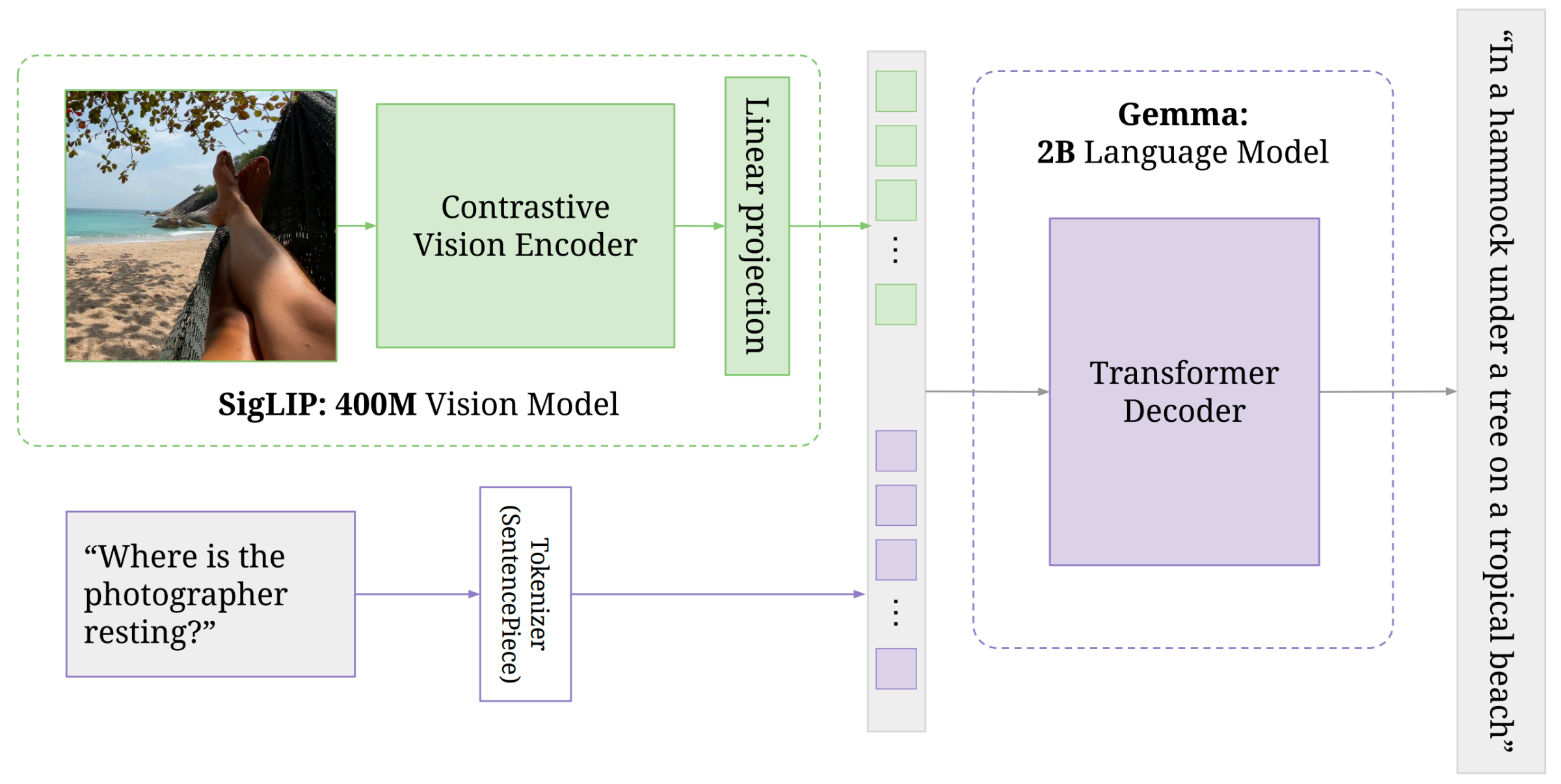
- PaliGemma(Google): 课上强调“联合更新视觉编码器与 LM”通常优于只更新一侧。
Lec11 要点
- ViT 给出了图像 token 化的标准接口。
- CLIP 用对比学习提供了高可扩展的图像表示。
- 多模态助手的工程核心是视觉 token 与语言 token 的对接方式。
Lec12 多模态建模 II(图像生成)
生成建模范式
课程对比了四大类:
- Autoregressive(AR): 建模 \(p(x_t\mid x_{<t})\)。
- VAE: 编码到潜变量 \(z\),再解码重建。
- GAN: 生成器与判别器对抗训练。
- Diffusion: 从噪声逐步去噪到数据分布。
尝试一:像素级自回归
把图像展平成像素序列: \[ x_{\text{img}} \rightarrow (x_1,\dots,x_T),\quad x_t\in\{0,\dots,255\} \] \[ \mathcal{L}_{\text{MLE}}=-\sum_{t=1}^{T}\log p_\theta(x_t\mid x_{<t}) \]
课程提到的代表:PixelRNN、Image Transformer、iGPT。
主要瓶颈:
- 序列过长(如 \(1024\times1024\times3\approx 3\)M tokens)。
- 单个像素语义弱,训练非常吃数据。
尝试二:学习离散图像 token
核心思路:先学一个图像 tokenizer/de-tokenizer,再让 LM 建模更短、更语义化的 token 序列。
VAE 回顾
标准目标: \[ \mathcal{L}_{\text{VAE}}(x)= -\mathbb{E}_{q_{\theta_{\text{enc}}}(z\mid x)}[\log p_{\theta_{\text{dec}}}(x\mid z)] +D_{\text{KL}}\!\left(q_{\theta_{\text{enc}}}(z\mid x)\|p(z)\right) \]
等价的 ELBO 视角: \[ \log p(x)\ge \mathbb{E}_{q(z\mid x)}[\log p(x\mid z)] -D_{\text{KL}}(q(z\mid x)\|p(z)) \]
VQ-VAE:从连续到离散
编码器给连续潜变量: \[ z_e(x)\in\mathbb{R}^{d} \]
再做最近邻量化: \[ k^*=\arg\min_j\|z_e(x)-e_j\|_2,\quad z_q(x)=e_{k^*} \]
训练损失由重建项 + codebook 项 + commitment 项组成: \[ \mathcal{L}= -\log p(x\mid z_q(x)) +\|\text{sg}[z_e(x)]-e\|_2^2 +\beta\|z_e(x)-\text{sg}[e]\|_2^2 \]
之后即可对离散图像 token 做自回归建模。
VQ-GAN
VQ-GAN 在 VQ-VAE 的基础上加入对抗/感知损失来提升 tokenizer 质量,再对得到的离散 token 训练 AR Transformer。
课上的实际收益:
- 序列长度显著降低(例如 \(32\times32=1024\));
- 比直接像素建模更可行,质量与计算开销更平衡。
统一文本 token 和图像 token
训练完 tokenizer 后:
- 将图像 token 加入 LM 词表。
- 在混合的文本+图像 token 序列上训练/微调。
- 用 de-tokenizer 把图像 token 还原为像素图像。
课程案例:DALL-E(2021)、Chameleon(Meta,2024)。
Lec12 要点
- 像素级 AR 概念直观,但扩展困难。
- VQ-VAE/VQ-GAN 这类离散 tokenizer 是 AR 多模态生成的关键桥梁。
- 统一 token 建模的代价是 tokenizer 引入的信息损失。
Lec15 多模态建模 III(Diffusion and Flows)
这部分在整门课里的位置
前两讲多模态主要讲了两件事:
- multi-to-text: 怎么把图像编码成语言模型可用的 token/向量序列
- token-based multi-to-image: 怎么通过离散视觉 token 生成图像
这一讲转向现代 text-to-image 的主流范式:
- 从噪声出发
- 逐步去噪得到图像
- 用文本或其他条件控制整个生成过程
Stable Diffusion 3 就是这种路线的代表。
Diffusion 的核心想法
扩散模型包含两个过程:
- 一个固定的前向加噪过程
- 一个可学习的反向去噪过程
前向过程可以写成: \[ q(x_t \mid x_{t-1}) = \mathcal{N}\!\left(x_t;\sqrt{\alpha_t}\,x_{t-1}, (1-\alpha_t)I\right) \]
记 \(\beta_t = 1-\alpha_t\),以及 \(\bar{\alpha}_t=\prod_{i=1}^t \alpha_i\),则可直接从 \(x_0\) 采样到任意中间时刻: \[ q(x_t \mid x_0) = \mathcal{N}\!\left(x_t;\sqrt{\bar{\alpha}_t}\,x_0,(1-\bar{\alpha}_t)I\right) \] \[ x_t=\sqrt{\bar{\alpha}_t}\,x_0+\sqrt{1-\bar{\alpha}_t}\,\epsilon, \quad \epsilon \sim \mathcal{N}(0,I) \]
课上强调的 noise schedule 要满足:
- \(\bar{\alpha}_0 = 1\),一开始还是原始数据
- \(\bar{\alpha}_T \approx 0\),最后接近纯噪声
- 随时间单调下降
最常见的做法是对 \(\beta_t\) 使用线性 schedule。
DDPM 的训练目标
严格来说,DDPM 是通过对隐变量 \(x_{1:T}\) 的 ELBO 来最大化 \(\log p_\theta(x_0)\)。
这个 ELBO 可以拆成三类项:
- 末端噪声分布的 prior matching
- 每一步反向转移的 denoising loss
- 靠近 \(x_0\) 的 reconstruction loss
但实际训练时,课程里给出的简化目标就是预测噪声: \[ \mathcal{L}_{\text{simple}}(\theta)= \mathbb{E}_{x_0,\epsilon,t} \left[\left\|\epsilon-\epsilon_\theta(x_t,t)\right\|_2^2\right], \quad t \sim \text{Uniform}\{1,\dots,T\} \]
训练流程非常直接:
- 采样真实图像 \(x_0\)
- 采样时间步 \(t\)
- 采样高斯噪声 \(\epsilon\)
- 构造加噪后的 \(x_t\)
- 让网络预测出被加进去的噪声
采样过程
生成时,从纯噪声开始: \[ x_T \sim \mathcal{N}(0,I) \]
然后对 \(t=T,\dots,1\),用 \(\epsilon_\theta(x_t,t)\) 参数化 \[ p_\theta(x_{t-1}\mid x_t) \] 不断采样更“干净”的状态,直到恢复出图像。
从噪声预测到 Score Learning
这一讲里一个非常关键的点,是把噪声预测和score estimation 连接起来。
记: \[ z_t = a_t x_0 + \sigma_t \epsilon \]
分布 \(p(z_t)\) 的 score 定义为: \[ \nabla_{z_t} \log p(z_t) \]
对于这个高斯扰动过程,可以得到: \[ \bar{\epsilon} = -\sigma_t \nabla_{z_t}\log p(z_t) \]
而 DDPM 正是在训练 \(\epsilon_\theta(z_t,t)\) 去逼近真实噪声,因此最优解满足: \[ \epsilon_\theta(z_t,t)\approx -\sigma_t \nabla_{z_t}\log p(z_t) \]
也就是说,DDPM 实际上是在隐式学习 score function。直觉上:
- 你能判断“加了什么噪声”,就知道该往哪个方向去噪
- 去噪的方向,也就是往更高概率区域移动的方向
条件生成与 Guidance
如果我们希望模型根据 prompt、类别标签或其他条件 \(c\) 生成图像,就需要 conditional generation。
Classifier Guidance
如果有一个额外分类器 \(p_\phi(c \mid z_t)\),可以用分类器梯度修正去噪预测: \[ \tilde{\epsilon}_{\theta,\phi}(z_t,c) = \epsilon_\theta(z_t,c)-w\sigma_t \nabla_{z_t}\log p_\phi(c\mid z_t) \]
这个额外项会把采样往更符合条件 \(c\) 的方向推。
Classifier-Free Guidance
更常见的做法是不单独训练分类器,而是训练一个既能“带条件”也能“不带条件”工作的模型,在采样时把两种预测线性组合: \[ \tilde{\epsilon}_\theta(z_t,c) = (1+w)\epsilon_\theta(z_t,c)-w\epsilon_\theta(z_t) \]
这就是现代扩散模型里最常见的 CFG 配方。
一般来说,\(w\) 越大,prompt
跟随性越强,但样本多样性也往往越差。
常见扩展
课上总结了几类重要扩展:
| 问题 | 方案 | 核心想法 |
|---|---|---|
| 像素空间扩散太贵 | Latent Diffusion | 在自编码器的 latent space 中做扩散 |
| U-Net 的归纳偏置可能受限 | Diffusion Transformer (DiT) | 用 Transformer 替代卷积式骨干 |
| 反向过程随机且慢 | 连续时间 / ODE 视角 | 用确定性路径和更好的数值求解器 |
| 采样步数仍然太多 | Distillation | 训练更少步数的 student sampler |
这些扩展也是扩散模型从“能跑”走向“能用”的关键。
连续时间视角
当离散步数趋向无穷时,扩散过程可以写成随机微分方程(SDE): \[ dz = f(t)z\,dt + g(t)\,dw \]
它的反向时间 SDE 为: \[ dz= \left[f(t)z-g(t)^2 \nabla_z \log p_t(z)\right]dt + g(t)\,d\bar{w} \]
由于 DDPM 已经学到了 score,我们可以代入近似: \[ \nabla_z \log p_t(z)\approx -\frac{\epsilon_\theta(z,t)}{\sigma_t} \]
此外,还存在一个与之具有相同边缘分布的确定性 probability-flow ODE: \[ dz= \left[f(t)z-\frac{1}{2}g(t)^2 \nabla_z \log p_t(z)\right]dt \]
这个视角的重要性在于:
- 可以引入 ODE solver 改善采样
- 也自然引出了 “除了 diffusion,还能不能用别的 flow 方式从噪声走到数据” 这个问题
Flow Matching
Flow matching 保留了“把一个分布运输到另一个分布”的目标,但把问题更直接地写成学习速度场。
设:
- \(p_0\) 是简单源分布,例如高斯噪声
- \(p_1\) 是目标数据分布
- \(v_t(\cdot)\) 是随时间变化的 velocity field
对应的 flow \(\phi_t\) 满足 ODE: \[ \frac{d}{dt}\phi_t(x)=v_t(\phi_t(x)), \quad \phi_0(x)=x \]
如果 \(v_t\) 学对了,那么把 \(X_0 \sim p_0\) 沿着这个 ODE 推到 \(t=1\),就会得到 \(X_1 \sim p_1\)。
Conditional Flow Matching
对单个数据点 \(x_1\),课上采用的条件路径是直线插值: \[ X_t = (1-t)X_0 + t x_1 \]
它的速度是已知的: \[ \frac{d}{dt}X_t = x_1 - X_0 \]
所以训练目标变成: \[ \mathcal{L}_{\text{CFM}} = \mathbb{E}_{x_1,X_0,t} \left[\left\|v_\theta(X_t,t)-(x_1-X_0)\right\|_2^2\right] \]
直觉上:
- diffusion 学的是“如何把一个被污染的点去噪”
- flow matching 学的是“如何沿着一条运输路径往前走”
相比 DDPM,flow matching 往往路径更直、数值积分更省步数。
案例:Stable Diffusion 3
课上用 Stable Diffusion 3 作为现代系统的案例:
- Flow matching: 不再使用经典 DDPM 式训练目标
- Latent space: 在预训练 autoencoder 的 latent space 中建模
- Text conditioning: 同时结合 CLIP 文本特征和 T5 特征
更一般地说,当前 SOTA 的 text-to-image 系统已经是多种思想的组合:
- 用 latent space 提高效率
- 用强文本编码器提供条件信号
- 用 Transformer/ODE/flow 视角提升生成质量与采样效率
Lec15 要点
- DDPM 的本质是学习如何反转一个固定的加噪过程。
- 预测噪声与学习 score function 本质上是连在一起的。
- Guidance 让扩散模型可以稳定地做条件生成。
- 连续时间视角把扩散模型和 ODE 求解联系起来。
- Flow matching 是更直接的分布运输视角,也是 Stable Diffusion 3 这类系统的重要基础。
总结
- Lec11: 关注“如何把图像编码给语言模型”。
- Lec12: 关注“如何用 token 化范式生成图像”。
- Lec15: 关注现代 text-to-image 系统如何通过去噪或连续流把噪声变成图像。
- 三部分合起来就是多模态系统的完整图景:
表示(encode)+ 对齐(alignment)+ 生成(离散或连续)。
本文基于 CMU 11-711 Advanced NLP(Sean Welleck)Multimodal Modeling I、II、III 课件整理。

