
11711 Advanced NLP: Multimodal Modeling
Lec11 多模态建模 I(Multi-to-Text)
全局视角
这部分课程重点是 multi-to-text:
- 输入可以是图像(也可以带文本)。
- 输出是文本。
- 核心问题是:如何把图像映射成语言模型可消费的向量序列。
把图像表示为“token”
文本我们已有 token embedding。
图像则需要一个编码器: \[
f_{\text{enc}}(x_{\text{image}}) \rightarrow z_1,\dots,z_L
\] 其中每个 \(z_i\) 都是一个向量
token。
Vision Transformer(ViT)
ViT 的思路是把图像切成 patch,线性映射为向量,再送入标准 Transformer。
给定: \[ x_{\text{image}} \in \mathbb{R}^{H \times W \times C} \]
按 \(P \times P\) 划分 patch: \[ N=\frac{HW}{P^2}, \quad x_p \in \mathbb{R}^{N \times (P^2C)} \]
投影到模型维度 \(D\): \[ x = x_p W_e, \quad W_e \in \mathbb{R}^{(P^2C)\times D}, \quad x \in \mathbb{R}^{N\times D} \]
再加位置编码并通过 Transformer。


课程中的直觉总结:
- 浅层更偏局部结构信息。
- 深层更偏全局语义区域。
- ViT 随预训练算力扩大有良好的扩展性。
CLIP:用语言监督学习视觉表示
CLIP(Radford et al., 2021)在共享嵌入空间中联合学习图像与文本。
- 图像编码器:\(f_I(x)\)
- 文本编码器:\(f_T(y)\)
- 配对图文应接近,不配对应远离。
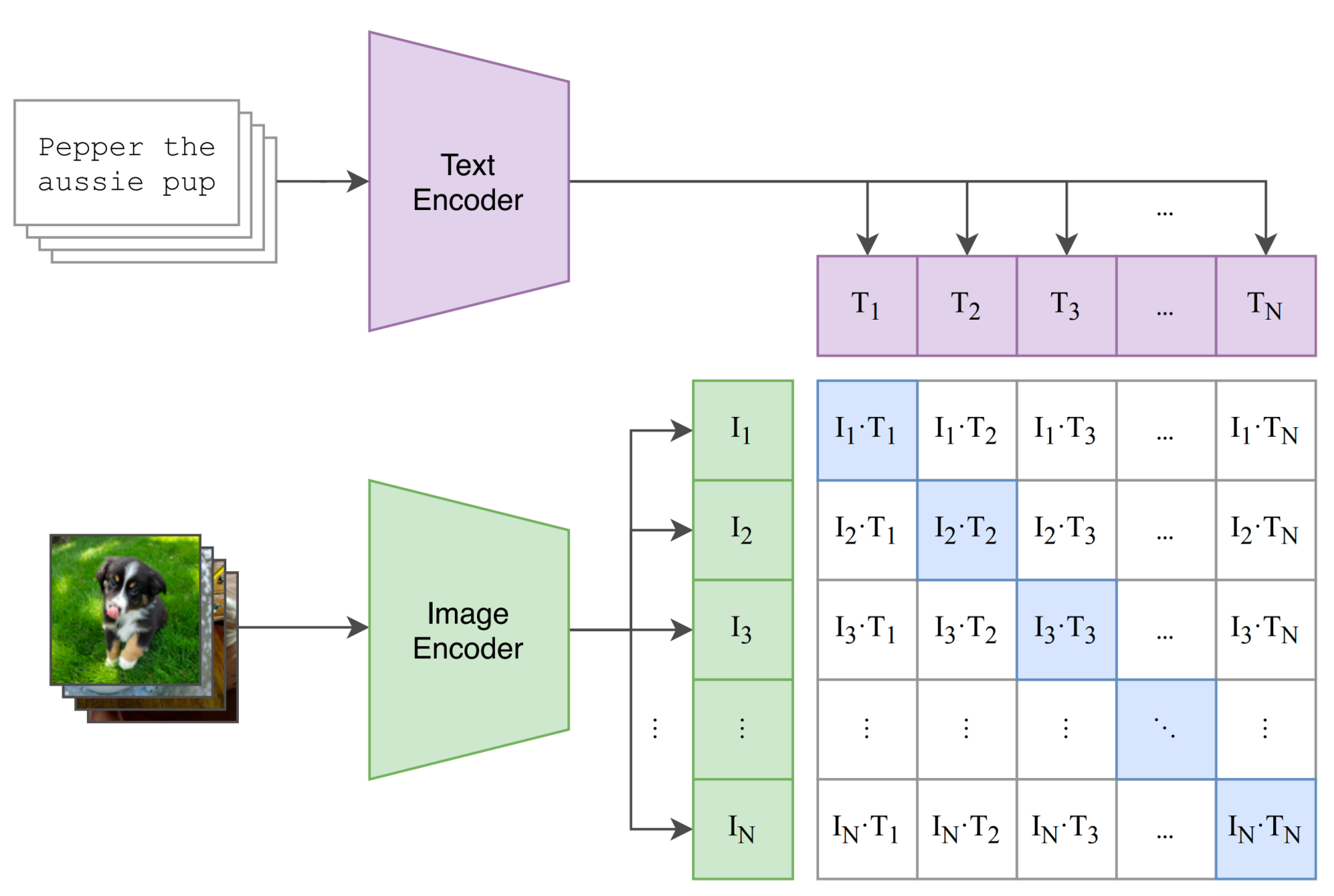
对一个 batch 中 \(N\) 对样本 \((x_n,y_n)\),定义相似度: \[ s_{ij}=\frac{f_I(x_i)^\top f_T(y_j)}{\tau} \]
对称对比学习目标: \[ \mathcal{L}_{\text{img}}=-\frac{1}{N}\sum_{i=1}^N \log \frac{e^{s_{ii}}}{\sum_j e^{s_{ij}}}, \quad \mathcal{L}_{\text{text}}=-\frac{1}{N}\sum_{i=1}^N \log \frac{e^{s_{ii}}}{\sum_j e^{s_{ji}}} \] \[ \mathcal{L}_{\text{CLIP}}=\frac{1}{2}\left(\mathcal{L}_{\text{img}}+\mathcal{L}_{\text{text}}\right) \]
它的重要性在于:
- 用自然语言描述替代“仅类别标签”的弱监督。
- 可扩展到 web 规模图文数据。
- 零样本迁移能力强。
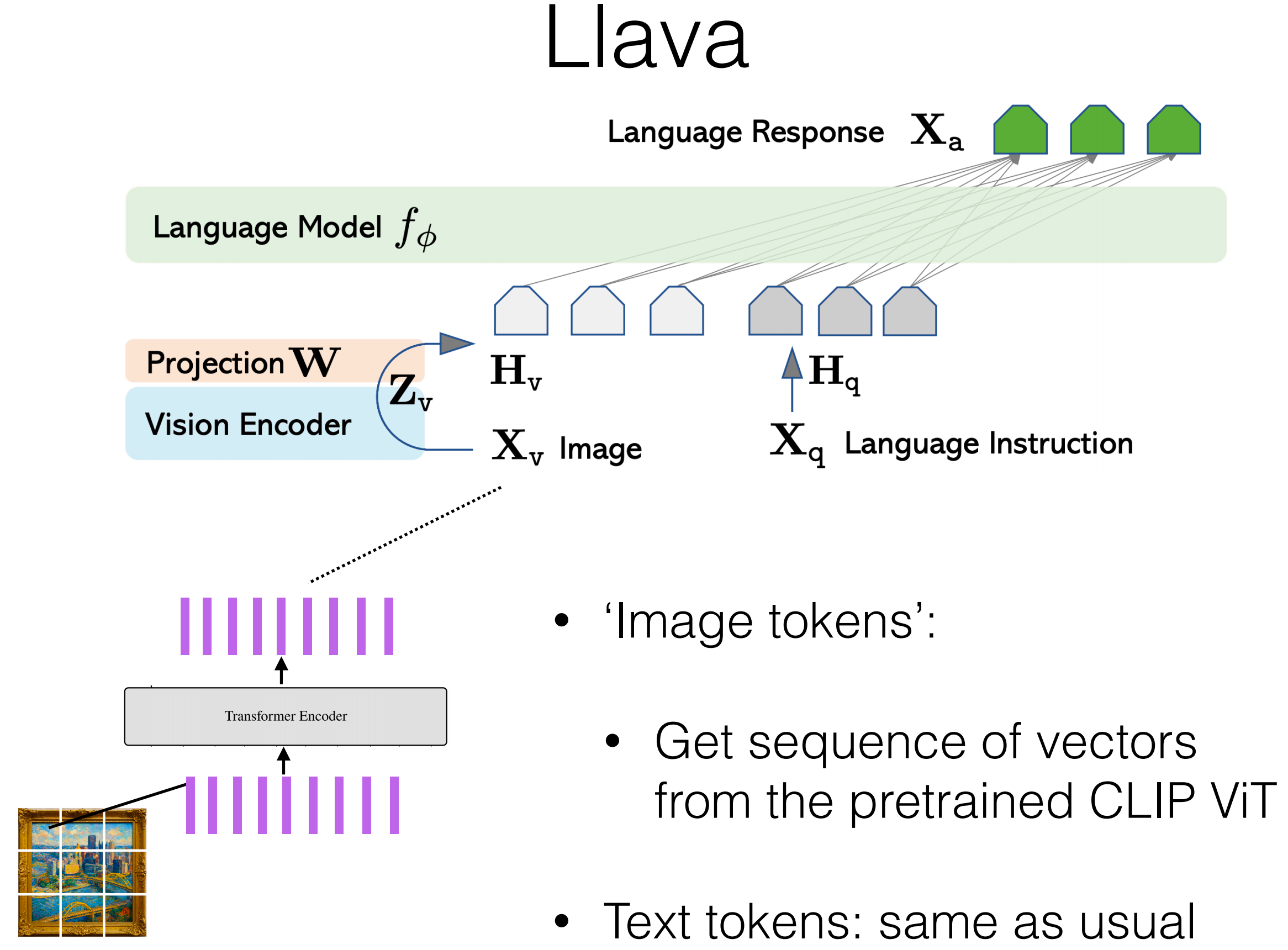
与语言模型结合:LLaVA 风格
课程给出的通用 pipeline:
- 图像预处理(patch/crop)。
- 用视觉编码器提取特征(常见是 CLIP ViT)。
- 线性映射到 LM 的 embedding 维度。
- 将视觉 token 与文本 token 拼接。
- 用图文指令数据训练/微调。
- 图像位置不计算 token-level LM loss。
可写成: \[ h_v=\text{Proj}(f_I(x_{\text{image}})), \quad p_\theta(y_t\mid y_{<t},x_{\text{text}},h_v) \]
课程中提到的系统案例
- Molmo(AI2): 使用 CLIP ViT-L/14(336px),经 pooling 和投影后送入 LLM,并结合全图和裁剪视图。

- PaliGemma(Google): 课上强调”联合更新视觉编码器与 LM”通常优于只更新一侧。

Lec11 要点
- ViT 给出了图像 token 化的标准接口。
- CLIP 用对比学习提供了高可扩展的图像表示。
- 多模态助手的工程核心是视觉 token 与语言 token 的对接方式。
Lec12 多模态建模 II(图像生成)
生成建模范式
课程对比了四大类:
- Autoregressive(AR): 建模 \(p(x_t\mid x_{<t})\)。
- VAE: 编码到潜变量 \(z\),再解码重建。
- GAN: 生成器与判别器对抗训练。
- Diffusion: 从噪声逐步去噪到数据分布。
尝试一:像素级自回归
把图像展平成像素序列: \[ x_{\text{img}} \rightarrow (x_1,\dots,x_T),\quad x_t\in\{0,\dots,255\} \] \[ \mathcal{L}_{\text{MLE}}=-\sum_{t=1}^{T}\log p_\theta(x_t\mid x_{<t}) \]
课程提到的代表:PixelRNN、Image Transformer、iGPT。
主要瓶颈:
- 序列过长(如 \(1024\times1024\times3\approx 3\)M tokens)。
- 单个像素语义弱,训练非常吃数据。
尝试二:学习离散图像 token
核心思路:先学一个图像 tokenizer/de-tokenizer,再让 LM 建模更短、更语义化的 token 序列。
VAE 回顾
标准目标: \[ \mathcal{L}_{\text{VAE}}(x)= -\mathbb{E}_{q_{\theta_{\text{enc}}}(z\mid x)}[\log p_{\theta_{\text{dec}}}(x\mid z)] +D_{\text{KL}}\!\left(q_{\theta_{\text{enc}}}(z\mid x)\|p(z)\right) \]
等价的 ELBO 视角: \[ \log p(x)\ge \mathbb{E}_{q(z\mid x)}[\log p(x\mid z)] -D_{\text{KL}}(q(z\mid x)\|p(z)) \]
VQ-VAE:从连续到离散
编码器给连续潜变量: \[ z_e(x)\in\mathbb{R}^{d} \]
再做最近邻量化: \[ k^*=\arg\min_j\|z_e(x)-e_j\|_2,\quad z_q(x)=e_{k^*} \]
训练损失由重建项 + codebook 项 + commitment 项组成: \[ \mathcal{L}= -\log p(x\mid z_q(x)) +\|\text{sg}[z_e(x)]-e\|_2^2 +\beta\|z_e(x)-\text{sg}[e]\|_2^2 \]
之后即可对离散图像 token 做自回归建模。
VQ-GAN
VQ-GAN 在 VQ-VAE 的基础上加入对抗/感知损失来提升 tokenizer 质量,再对得到的离散 token 训练 AR Transformer。
课上的实际收益:
- 序列长度显著降低(例如 \(32\times32=1024\));
- 比直接像素建模更可行,质量与计算开销更平衡。
统一文本 token 和图像 token
训练完 tokenizer 后:
- 将图像 token 加入 LM 词表。
- 在混合的文本+图像 token 序列上训练/微调。
- 用 de-tokenizer 把图像 token 还原为像素图像。
课程案例:DALL-E(2021)、Chameleon(Meta,2024)。
Lec12 要点
- 像素级 AR 概念直观,但扩展困难。
- VQ-VAE/VQ-GAN 这类离散 tokenizer 是 AR 多模态生成的关键桥梁。
- 统一 token 建模的代价是 tokenizer 引入的信息损失。
总结
- Lec11: 关注“如何把图像编码给语言模型”。
- Lec12: 关注“如何用 token 化范式生成图像”。
- 两节合起来就是多模态系统三件事:
表示(encode)+ 对齐(alignment)+ 生成(decode)。
本文基于 CMU 11-711 Advanced NLP(Sean Welleck)Multimodal Modeling I & II 课件整理。


