
11711 Advanced NLP: Retrieval and RAG
Lec10 检索与RAG
为什么需要检索?
大型语言模型虽然强大,但仍存在以下问题:
- 幻觉: 生成流畅但无根据的声明。
- 过时的知识: 模型参数无法立即反映新事实。
- 单体记忆瓶颈: 所有知识都被压缩到固定参数中。
检索增强系统将外部文档视为非参数记忆,并在推理时获取证据。
检索增强语言模型:核心直觉
给定查询 \(x\):
- 从数据存储中检索前 \(k\) 个相关段落。
- 将检索到的段落 + 查询馈送到生成器。
- 生成基于检索证据的答案。
关键组件:
- 数据存储: 语料库和索引。
- 检索器: 将查询/文档映射到相似度分数。
- 生成器(LM): 产生最终响应。

第一部分:数据存储
存储什么?
典型选项包括:
- 网页、论文、维基页面、领域文档。
- 段落级块而不是完整文档。
- 元数据(来源、时间戳、URL、章节标题)用于归因和过滤。
处理流程
实用流程:
- 策划: 选择与目标任务相关的来源。
- 预处理: HTML/PDF转换为干净文本、规范化、去重。
- 分块: 将长文档拆分为段落。
- 索引: 构建稀疏或稠密检索索引。
分块权衡:
- 太短:缺乏上下文。
- 太长:引入噪声并损害检索精度。

扩展考虑因素
- 语料库大小可达数十亿个标记或更多。
- 使用ANN索引和分片实现低延迟服务。
- 通过定期重新索引保持文档新鲜度。
第二部分:检索器
稀疏检索器(TF-IDF / BM25)
经典词法匹配使用词袋风格向量。
TF-IDF基础: \[ \text{TF}(t, d)=\frac{\text{freq}(t,d)}{\sum_{t'} \text{freq}(t',d)}, \quad \text{IDF}(t)=\log\frac{N}{\text{df}(t)} \]
TF(t, d) 衡量词项 \(t\) 在文档 \(d\) 中出现的频率,按文档长度归一化。
IDF(t) 衡量词项在整个语料库中的稀有程度。常见词如”the”几乎出现在每个文档中,因此 \(\text{df}(t) \approx N\) 且 IDF → 0。
最终的TF-IDF分数就是 \(\text{TF}(t,d) \times \text{IDF}(t)\):当一个词项在本文档中频繁出现但在全局稀有时,它最重要。
BM25分数: \[ \text{BM25}(q,d)=\sum_{t \in q} \text{IDF}(t)\cdot \frac{\text{TF}(t,d)(k_1+1)} {\text{TF}(t,d)+k_1\left(1-b+b\frac{|d|}{\text{avgdl}}\right)} \]
BM25(Best Matching 25)是TF-IDF的概率精化版本,是Elasticsearch和Lucene等搜索引擎的默认排名函数。两个关键改进:
- TF饱和(由 \(k_1\) 控制,通常为1.2):随着 \(\text{TF}(t,d)\) 增长,分数接近 \((k_1 + 1)\) 的渐近极限。这防止了文档仅因过度重复关键字而占主导地位。相比之下,原始TF-IDF线性增长无界限。
- 文档长度归一化(由 \(b\) 控制,通常为0.75):项 \(b \cdot \frac{|d|}{\text{avgdl}}\) 惩罚较长文档,因为它们自然具有更高的词频。当 \(b = 0\) 时,不应用长度归一化;当 \(b = 1\) 时,相对于平均文档长度(avgdl)进行完全归一化。
优点:
- 快速且词法精度高。
- 无需神经训练。
缺点:
- 对释义的语义匹配较弱。
稠密检索器(双编码器)
将查询和文档编码为稠密向量: \[ s(q,d)=\langle E_q(q), E_d(d) \rangle \]
常见训练使用对比学习: \[ \mathcal{L}= -\log \frac{\exp(s(q,d^+)/\tau)} {\exp(s(q,d^+)/\tau)+\sum_{d^-}\exp(s(q,d^-)/\tau)} \]
优点:
- 更好的语义检索。
- 适用于释义和词法不匹配。
缺点:
- 需要训练数据和ANN基础设施。

快速最近邻搜索
大规模稠密检索依赖于近似最近邻(ANN)方法(例如FAISS),以微小的召回损失换取大幅延迟降低。
使用交叉编码器重排序
两阶段检索很常见:
- 双编码器快速检索前 \(k\) 个候选。
- 交叉编码器以更高精度重排序候选列表。
评估指标和基准
常用指标:
- Recall@k:相关文档是否在前 \(k\) 个中找到。
- MRR:第一个相关命中的倒数排名质量。
- nDCG@k:分级排名质量。
- Precision@k:前 \(k\) 个命中中相关的比例。

课程中强调的基准:
- BEIR(跨异构任务的零样本IR)。
- MTEB(大规模嵌入基准)。
第三部分:如何使用检索
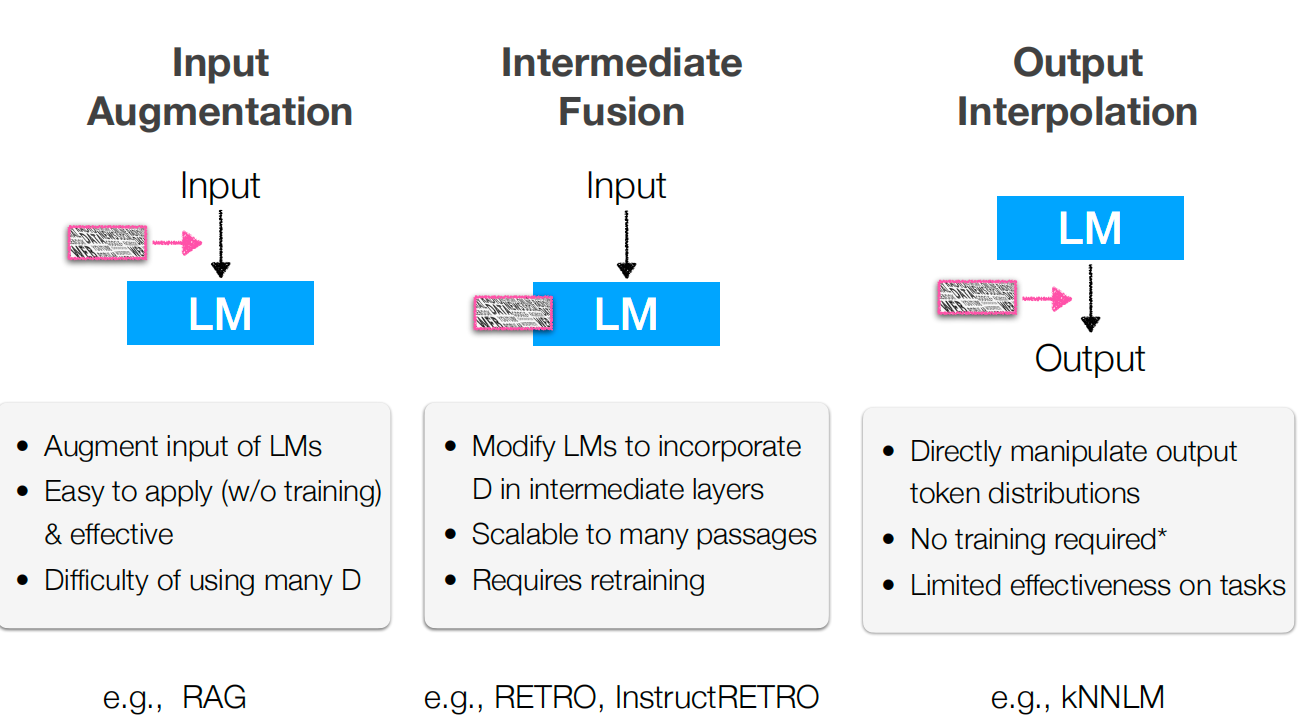
上下文RAG(输入增强)
检索证据并将其附加到提示上下文。
序列级RAG形式: \[ p(y \mid x) \approx \sum_{z \in \text{top-}k} p_\eta(z \mid x)\,p_\theta(y \mid x, z) \]
标记级边际化形式: \[ p(y \mid x) \approx \prod_i \sum_{z \in \text{top-}k} p_\eta(z \mid x)\,p_\theta(y_i \mid x, z, y_{<i}) \]

RAG的训练策略
- 独立训练: 分别训练检索器和生成器。
- 顺序训练: 先训练检索器,然后适配生成器。
- 端到端训练: 联合优化检索和生成。
上下文RAG的局限性
- 检索可能返回不相关的段落(错误传播)。
- 长上下文增加成本,可能稀释有用证据。
- 如果提示较弱,生成器可能仍然忽略检索到的证据。
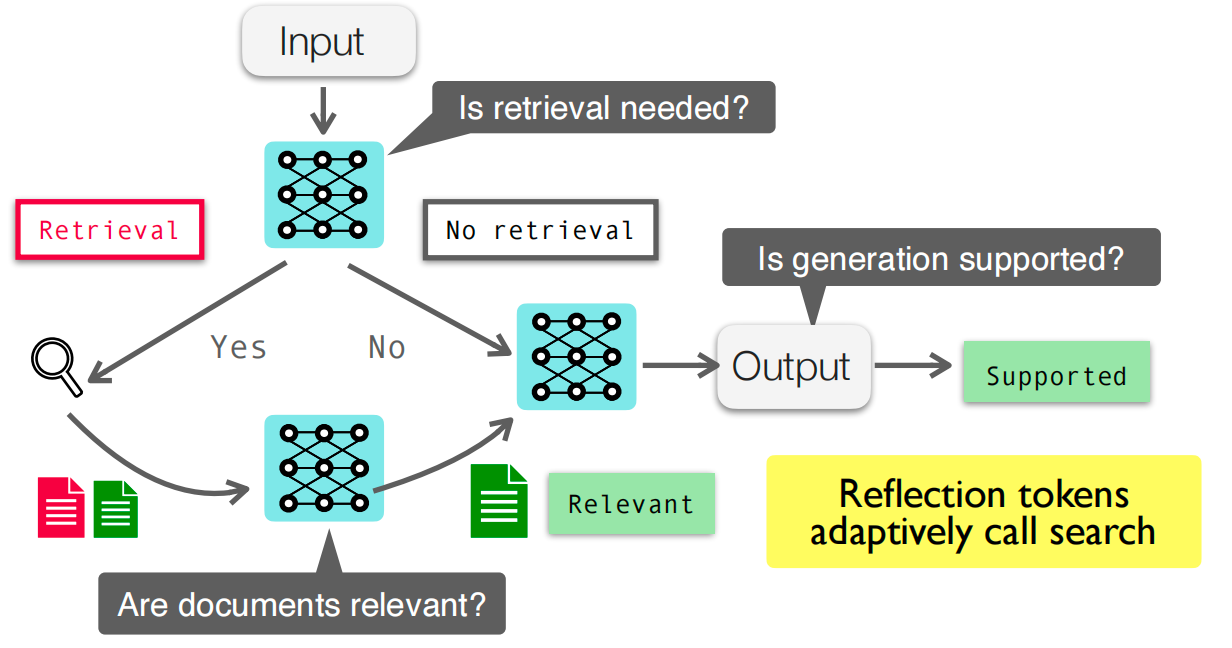
Self-RAG和自适应检索
Self-RAG风格的系统学习:
- 决定是否需要检索。
- 决定何时在生成过程中再次检索。
- 用证据批评或验证生成质量。
这使检索使用成为条件性的,而不是始终开启。
超越上下文RAG
- 工具增强LM: 迭代调用工具/搜索API。
- 深度研究代理: 多步检索 + 综合工作流。
- 中间增强: RETRO / kNN-LM在隐藏状态或标记级别检索,而不仅仅是提示级别。


实用检查清单
- 定义目标领域和新鲜度要求。
- 构建干净、良好分块的数据存储并包含元数据。
- 根据延迟-质量预算选择稀疏/稠密/混合检索。
- 如果前 \(k\) 质量是瓶颈,添加重排序器。
- 联合跟踪检索指标和端任务准确性。
- 添加引用和证据检查以降低幻觉风险。
关键要点
- RAG为LM添加外部、可更新的记忆。
- 质量取决于三个耦合部分:数据存储、检索器、生成器。
- 稠密检索 + 重排序通常是实用的高性能路径。
- 自适应检索(Self-RAG、工具使用)解决了静态上下文RAG的局限性。

