
15642 机器学习系统:分布式训练与并行化
数据并行与零冗余优化
课程:15-442/15-642 机器学习系统 授课教师:Tianqi Chen 和 Zhihao Jia 卡内基梅隆大学
DNN 训练概述
DNN 训练迭代三个阶段:前向传播计算层输出 \(h^{(l+1)} = f^{(l)}(W^{(l)} h^{(l)} + b^{(l)})\),反向传播通过链式法则计算梯度 \(\frac{\partial L}{\partial W^{(l)}}\),以及权重更新应用 \(W^{(l)} \leftarrow W^{(l)} - \eta \frac{\partial L}{\partial W^{(l)}}\)。
每个 GPU 必须存储参数、激活值(为反向传播保存)、梯度和优化器状态(例如 Adam 的动量和方差)。对于大型模型,这种内存占用成为主要瓶颈。
数据并行基础
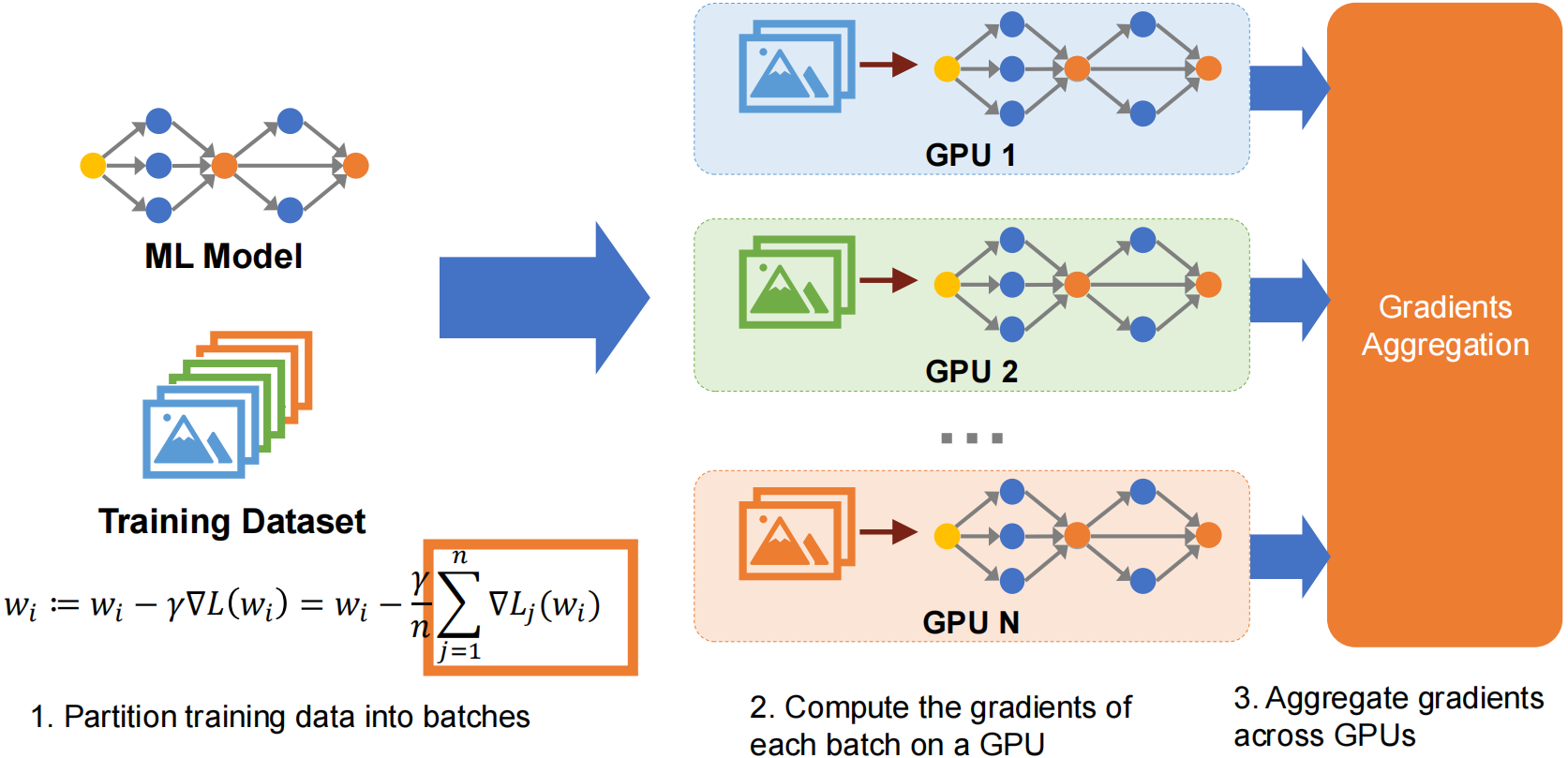
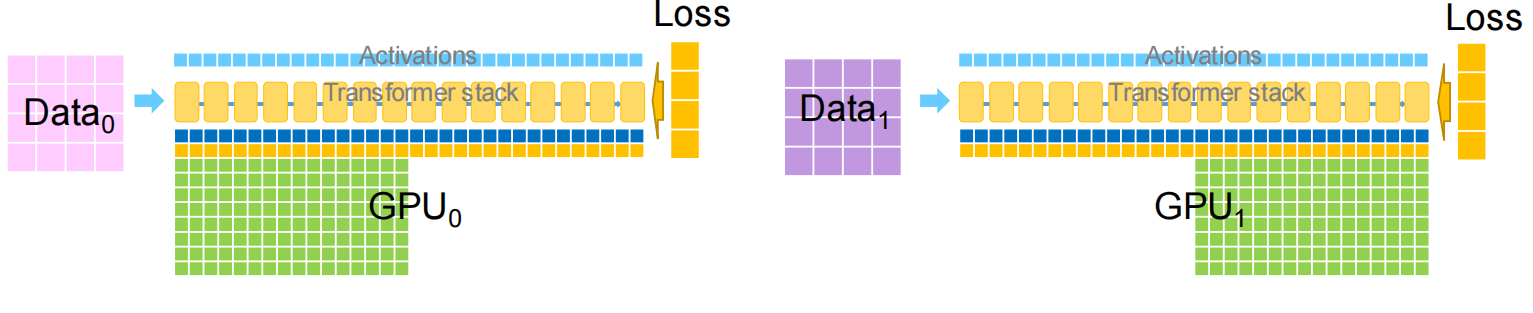
数据并行将训练数据分割到多个工作器(GPU)上,每个工作器持有模型的完整副本。每次迭代的训练循环:
- 分散数据:将不同的 mini-batch 分发到各个工作器
- 前向和反向传播:每个工作器独立地在其本地数据上计算梯度
- 同步梯度:跨所有工作器聚合梯度(AllReduce)
- 更新参数:每个工作器使用聚合后的梯度应用优化器步骤
所有工作器通过同步梯度更新保持相同的参数。对于 4 个工作器和批量大小 32,每个处理 8 个样本——理想情况下可获得 4 倍加速。
梯度聚合策略
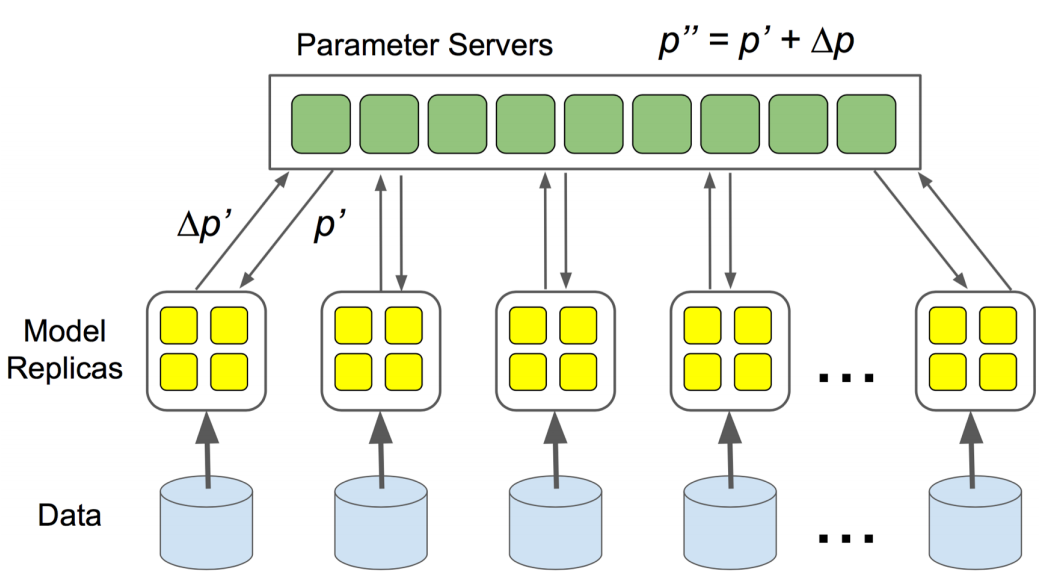
参数服务器架构
参数服务器是一种中心化方法:工作器将梯度推送到中心服务器(\(N \times M\) 通信),服务器聚合并更新参数,然后工作器拉取更新后的权重(\(N \times M\) 通信)。每次迭代总通信量:\(2NM\)。
局限性:所有流量都通过服务器,造成带宽瓶颈,随着工作器增多而恶化。它也是单点故障,负载分布不均。这种架构扩展性差。
AllReduce 通信模式
AllReduce 是一种去中心化的集体操作:所有工作器贡献本地梯度并接收聚合结果。没有单一瓶颈节点。
朴素 AllReduce
每个工作器将其 \(M\) 个参数广播给所有 \((N-1)\) 个其他工作器。总通信量:\(N(N-1)M = O(N^2 M)\) —— 二次扩展,效率低下。
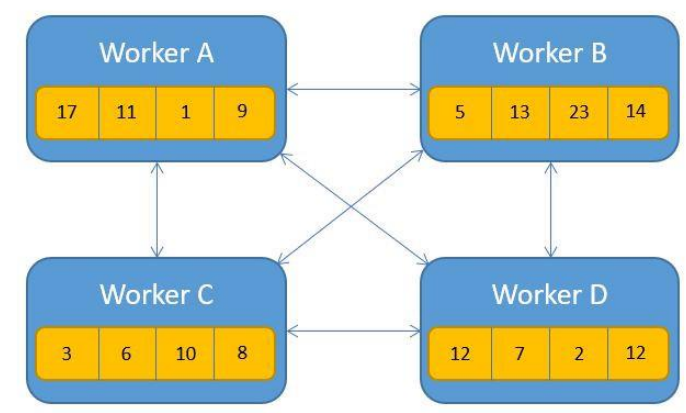
Ring AllReduce
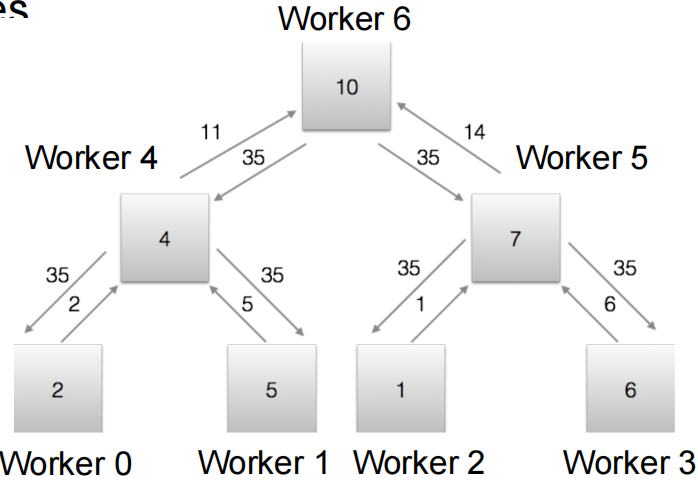
Ring AllReduce 通过将工作器组织成逻辑环来实现最优通信复杂度。
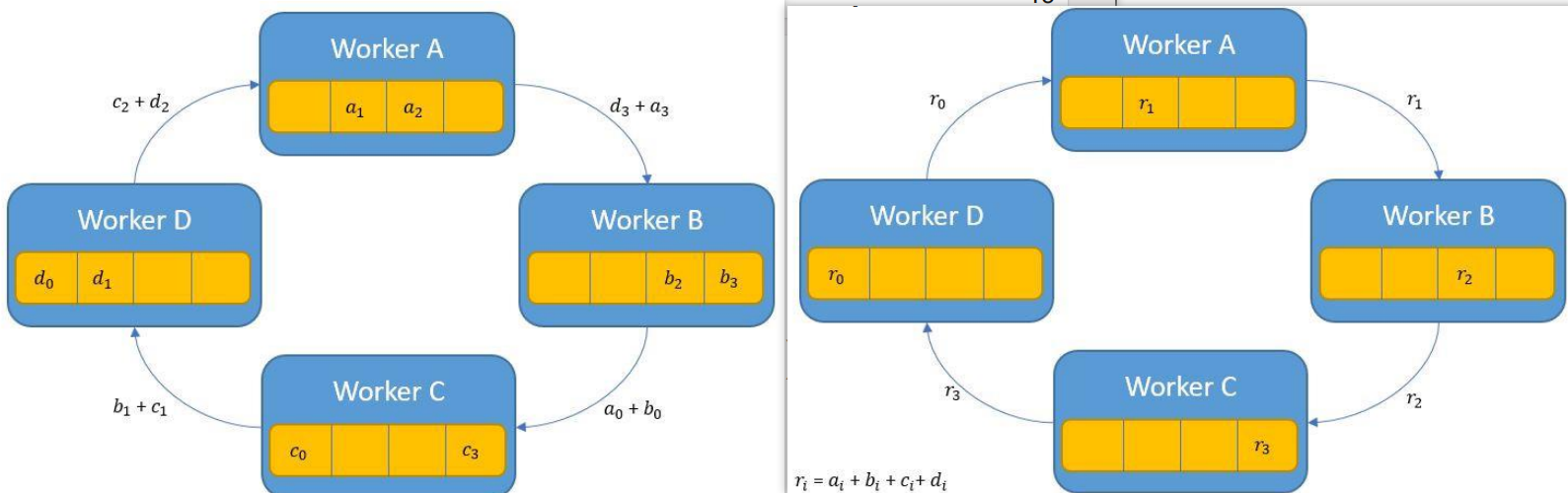
聚合阶段
设置:将 N 个工作器排列成环:\(W_0 \leftrightarrow W_1 \leftrightarrow \cdots \leftrightarrow W_{N-1} \leftrightarrow W_0\)
策略:将参数分成 N 个块,每步处理一个块。
过程(N-1 步):
- 每个工作器以一个块作为”负责块”开始
- 步骤 k(\(k = 0, 1,
\ldots, N-2\)):
- 工作器 \(i\) 将块 \(j\) 发送给工作器 \((i+1) \mod N\)
- 工作器 \(i\) 从工作器 \((i-1) \mod N\) 接收块 \(j'\)
- 工作器 \(i\) 累加接收的块:\(\text{chunk}_{j'} \leftarrow \text{chunk}_{j'} + \text{received}\)
结果:N-1 步后,每个工作器都有一个块的完全聚合结果。
广播阶段
目标:分发聚合后的块,使每个工作器都拥有所有块。
过程(N-1 步):
- 步骤 k(\(k = 0, 1,
\ldots, N-2\)):
- 工作器 \(i\) 将其完成的块发送给工作器 \((i+1) \mod N\)
- 工作器 \(i\) 从工作器 \((i-1) \mod N\) 接收一个完成的块
结果:N-1 步后,所有工作器都拥有所有聚合后的块。
通信成本分析
每步传输每个工作器 \(M/N\)。总步数:\(2(N-1)\)(N-1 聚合 + N-1 广播)。
每个工作器总量:\(2(N-1) \times \frac{M}{N} \approx 2M\) —— 与 N 无关,最优扩展。
总网络通信量:\(2(N-1)M \approx 2NM\)。
Tree AllReduce
工作器形成深度为 \(\log_2 N\) 的二叉树。Reduce 阶段(自底向上)将梯度从叶子聚合到根;Broadcast 阶段(自顶向下)将结果分发回去。
通信量:Reduce 阶段 \(\sum_{i=1}^{\log_2 N} \frac{N}{2^i} \times M = (N-1)M\),broadcast 阶段 \((N-1)M\)。总计:\(2(N-1)M \approx 2NM\),仅需 \(2\log_2 N\) 次迭代(少于 ring 的 \(2(N-1)\))。权衡:根节点可能存在带宽瓶颈。
Butterfly AllReduce
使用基于超立方体的模式:在迭代 \(k\) 中,工作器 \(i\) 与工作器 \(i \oplus 2^k\)(异或)通信。对于 8 个工作器:迭代 0 配对 0↔︎1, 2↔︎3, 4↔︎5, 6↔︎7;迭代 1 配对 0↔︎2, 1↔︎3, 4↔︎6, 5↔︎7;迭代 2 配对 0↔︎4, 1↔︎5, 2↔︎6, 3↔︎7。
每次迭代,工作器与其伙伴交换 \(M/2\) 个参数并在本地聚合。所有工作器并行运行,负载均衡。
通信量:每个工作器每次迭代 \(M\) × \(\log_2 N\) 次迭代 = 总计 \(NM\log_2 N\)。略多于 Ring/Tree(\(2NM\)),但仅需 \(\log_2 N\) 次迭代——当延迟比总带宽更重要时最佳。需要工作器数量为 2 的幂次。

性能对比
| 算法 | 总通信量 | 迭代次数 | 带宽瓶颈 |
|---|---|---|---|
| 参数服务器 | \(2NM\) | 2 | 服务器瓶颈 |
| 朴素 AllReduce | \(N(N-1)M\) | 1 | 二次扩展 |
| Ring AllReduce | \(2NM\) | \(2(N-1)\) | 均衡 |
| Tree AllReduce | \(2NM\) | \(2\log_2 N\) | 根节点瓶颈 |
| Butterfly AllReduce | \(NM\log_2 N\) | \(\log_2 N\) | 均衡 |
Ring AllReduce 在实践中最常用(PyTorch DDP、Horovod)—— 最优的 \(2NM\) 通信量和均衡的带宽。Tree AllReduce 以根节点瓶颈风险换取更少的迭代次数(\(2\log_2 N\))。Butterfly 以略高的总通信量代价最小化迭代次数(\(\log_2 N\))。

大模型训练挑战
随着模型扩展到数十亿参数,内存成为关键瓶颈。
内存分解
对于使用 Adam 进行混合精度训练的 M 参数模型:
| 组件 | 精度 | 内存 |
|---|---|---|
| 参数 | FP16 | \(2M\) 字节 |
| 梯度 | FP16 | \(2M\) 字节 |
| 优化器:FP32 主副本 | FP32 | \(4M\) 字节 |
| 优化器:动量(一阶矩) | FP32 | \(4M\) 字节 |
| 优化器:方差(二阶矩) | FP32 | \(4M\) 字节 |
| 总计 | \(16M\) 字节 |
FP16 用于前向/反向计算(更快,内存更少)。FP32 是优化器更新所需,以防止累积过程中的数值误差。

扩展示例
| 模型 | 参数量 | 训练内存 | 硬件 |
|---|---|---|---|
| BERT-Large (2018) | 340M | 5.4 GB | 单个 V100 (16GB) 可容纳 |
| GPT-2 (2019) | 1.5B | 24 GB | 需要多 GPU |
| GPT-3 (2020) | 175B | 2.8 TB | 35+ A100-80GB GPU |
标准数据并行在每个 GPU 上复制完整模型——大量内存冗余。
ZeRO:零冗余优化器
概述
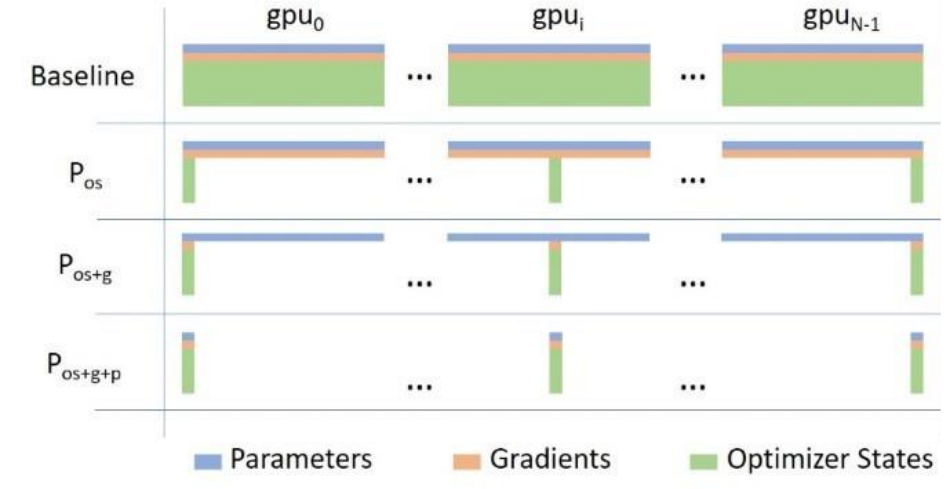
ZeRO(Zero Redundancy Optimizer)消除了数据并行训练中的内存冗余。标准 DP 在每个 GPU 上复制参数、梯度和优化器状态——对于 N 个 GPU,这意味着所有内容都有 N 份副本,浪费 \((N-1) \times 16M\) 字节。
ZeRO 的想法:在 GPU 之间分区这些组件而不是复制它们,将每个 GPU 的内存从 \(16M\) 减少到 \(\frac{16M}{N}\),代价是额外的通信。
ZeRO Stage 1:分区优化器状态
ZeRO-1 仅在 GPU 之间分区优化器状态。参数和梯度保持完全复制。每个 GPU 仅负责更新其分配的 \(\frac{1}{N}\) 分区。
训练迭代: 1. 前向传播:使用完整的本地参数正常计算(无通信) 2. 反向传播:计算完整梯度 → AllReduce 同步(\(2M\) 通信) 3. 权重更新:每个 GPU 仅使用本地优化器状态更新其分区 4. 参数同步:AllGather 在每个 GPU 上重建完整参数(\(2M\) 通信)
每 GPU 内存:\(4M + \frac{12M}{N}\)(参数 \(2M\) + 梯度 \(2M\) + 分区优化器 \(\frac{12M}{N}\))
通信量:每次迭代 \(4M\)。对于 N=4:内存 = \(7M\) vs 基线 \(16M\) —— 2.3 倍减少。
ZeRO Stage 2:分区梯度
ZeRO-2 额外分区梯度——因为每个 GPU 只需要其更新的参数的梯度,所以不需要完整的梯度缓冲区。
关键变化:在反向传播期间用 Reduce-Scatter 替换 AllReduce。Reduce-Scatter 聚合梯度但仅向每个 GPU 传递其拥有的分区(不需要广播阶段)。这可以在反向传播期间逐层发生,将通信与计算重叠。
训练迭代: 1. 前向传播:正常计算(无通信) 2. 反向传播:计算梯度 → 每层 Reduce-Scatter,每个 GPU 仅保留其分区 3. 权重更新:每个 GPU 更新其分区 4. 参数同步:AllGather 重建完整参数(\(2M\))
每 GPU 内存:\(2M + \frac{14M}{N}\)(参数 \(2M\) + 分区梯度 \(\frac{2M}{N}\) + 分区优化器 \(\frac{12M}{N}\))
通信量:每次迭代 \(4M\)(与 ZeRO-1 相同)。对于 N=4:内存 = \(5.5M\) —— 2.9 倍减少。

ZeRO Stage 3:分区参数
ZeRO-3 分区所有内容——没有组件被复制。每个 GPU 仅存储参数、梯度和优化器状态的 \(\frac{1}{N}\)。挑战:如何在没有完整参数的情况下计算前向/反向传播?解决方案:按需 AllGather 参数,然后丢弃。
前向传播(逐层):AllGather \(W^{(l)}\) → 计算层 → 丢弃收集的参数(仅保留自己的分区和激活值)。
反向传播(逐层):再次 AllGather \(W^{(l)}\) → 计算梯度 → Reduce-Scatter 梯度 → 丢弃收集的参数 → 立即更新自己的分区。

不需要单独的参数同步步骤——更新后的参数已经正确分区。
每 GPU 内存:\(\frac{16M}{N}\) —— 完美的线性扩展(\(O(M/N)\))。
通信量:每次迭代 \(4M\)(前向 AllGather + 反向 AllGather + Reduce-Scatter 梯度)。这是基线的 2 倍,但能够训练否则无法装入内存的模型。当 ZeRO-2 不足时使用。
性能分析
内存对比(M 参数,N GPU)
| 组件 | 基线 DP | ZeRO-1 | ZeRO-2 | ZeRO-3 |
|---|---|---|---|---|
| 参数 | \(2M\) | \(2M\) | \(2M\) | \(\frac{2M}{N}\) |
| 梯度 | \(2M\) | \(2M\) | \(\frac{2M}{N}\) | \(\frac{2M}{N}\) |
| 优化器状态 | \(12M\) | \(\frac{12M}{N}\) | \(\frac{12M}{N}\) | \(\frac{12M}{N}\) |
| 总计 | \(16M\) | \(4M + \frac{12M}{N}\) | \(2M + \frac{14M}{N}\) | \(\frac{16M}{N}\) |
GPT-3 (175B, 64 GPUs):基线 = 2.8 TB/GPU(不可能),ZeRO-1 = 750 GB,ZeRO-2 = 481 GB,ZeRO-3 = 44 GB(可装入 A100-80GB)。
通信对比
| 阶段 | 前向 | 反向 | 更新 | 总计 |
|---|---|---|---|---|
| 基线 DP | - | \(2M\) (AllReduce) | - | \(2M\) |
| ZeRO-1 | - | \(2M\) (AllReduce) | \(2M\) (AllGather) | \(4M\) |
| ZeRO-2 | - | \(2M\) (Reduce-Scatter) | \(2M\) (AllGather) | \(4M\) |
| ZeRO-3 | \(2M\) (AllGather) | \(2M\) (Reduce-Scatter) | - | \(4M\) |
所有 ZeRO 阶段的通信量是基线的 2 倍。ZeRO-3 由于逐层同步具有更高的延迟,但能够训练最大的模型。高速互连(NVLink、InfiniBand)是必需的,通信可以与计算重叠以隐藏延迟。
总结
| 阶段 | 分区内容 | 每 GPU 内存 | 通信量 |
|---|---|---|---|
| 基线 DP | 无 | \(16M\) | \(2M\) |
| ZeRO-1 | 优化器状态 | \(4M + \frac{12M}{N}\) | \(4M\) |
| ZeRO-2 | 优化器 + 梯度 | \(2M + \frac{14M}{N}\) | \(4M\) |
| ZeRO-3 | 所有内容 | \(\frac{16M}{N}\) | \(4M\) |
ZeRO 以适度的 2 倍通信开销实现线性内存扩展(\(O(M/N)\))。在 DeepSpeed 和 PyTorch FSDP 中实际使用。
选择策略:当模型适合单个 GPU 时使用标准 DP;当优化器内存受限时使用 ZeRO-1;当梯度也需要减少时使用 ZeRO-2;当连参数都无法装入时使用 ZeRO-3。
关于内存模型的说明:上述笔记使用 16M 模型(优化器状态 = 12M)。下面的问答部分使用 ZeRO 论文中的 20Ψ 模型,该模型明确将 FP32 梯度副本计为优化器状态的一部分(优化器状态 = 16Ψ)。20Ψ 模型对于使用 Adam 的混合精度训练更精确。
模型并行与流水线并行
模型并行概述
模型并行解决了数据并行的根本限制:当模型太大而无法装入单个 GPU 时。模型并行不是复制整个模型,而是在多个设备上分割模型。
核心思想:将模型分区为多个子图,并将不同的子图分配给不同的 GPU。每个 GPU: - 仅存储模型参数的一部分 - 为其分配的层计算前向/反向传播 - 将中间激活值传输到流水线中的下一个 GPU

这使得可以训练超过单个 GPU 内存的模型,但引入了新的挑战:通信开销和潜在的 GPU 利用率不足。
张量模型并行
张量模型并行在单个层内跨多个 GPU 分区参数。对于矩阵乘法 \(y = xW\),我们可以分区 \(W\) 的输出维度或输入维度。
分区输出(按列分割)
按列分割权重矩阵 \(W\):\(W = [W_1, W_2]\)
每个 GPU 独立计算输出的一部分:
\[ \begin{aligned} y_1 &= x \times W_1 \quad \text{(GPU 1)} \\ y_2 &= x \times W_2 \quad \text{(GPU 2)} \\ y &= [y_1, y_2] \quad \text{(拼接)} \end{aligned} \]

前向传播:将输入 \(x\) 广播到所有 GPU → 每个 GPU 计算其分区 → 拼接输出(无通信)。
反向传播:每个 GPU 有其分区的梯度 → 需要跨 GPU 聚合输入梯度 \(\frac{\partial L}{\partial x}\)。
通信成本:\(O(B \times C_{in})\),用于前向传播中的输入广播和反向传播中的梯度聚合。
减少输出(按行分割)
按行分割权重矩阵 \(W\):\(W = \begin{bmatrix} W_1 \\ W_2 \end{bmatrix}\)
相应地分割输入 \(x\):\(x = [x_1, x_2]\)
每个 GPU 计算必须求和的部分结果:
\[ \begin{aligned} y_1 &= x_1 \times W_1 \quad \text{(GPU 1)} \\ y_2 &= x_2 \times W_2 \quad \text{(GPU 2)} \\ y &= y_1 + y_2 \quad \text{(AllReduce)} \end{aligned} \]

前向传播:分割输入 \(x\) → 每个 GPU 计算部分输出 → AllReduce 求和结果。
反向传播:每个 GPU 接收完整梯度 → 计算其分区的梯度 → 输出其输入部分的梯度。
通信成本:\(O(B \times C_{out})\),用于前向传播中的输出减少和反向传播中的梯度分割。
通信成本对比
对于批量大小为 \(B\)、输入通道 \(C_{in}\)、输出通道 \(C_{out}\) 的层:
| 策略 | 前向 | 反向 | 梯度同步 | 总通信量 |
|---|---|---|---|---|
| 数据并行 | 0 | 0 | \(O(C_{out} \times C_{in})\) | \(O(C_{out} \times C_{in})\) |
| 张量 MP(分区输出) | \(O(B \times C_{in})\) | \(O(B \times C_{in})\) | 0 | \(O(B \times C_{in})\) |
| 张量 MP(减少输出) | \(O(B \times C_{out})\) | \(O(B \times C_{out})\) | 0 | \(O(B \times C_{out})\) |
权衡:
- 数据并行:前向/反向传播期间无通信,但需要梯度的 AllReduce(与参数数量成正比)。
- 张量模型并行:每次前向/反向传播期间都有通信(与批量大小和激活值成正比),但不需要梯度同步。
何时使用什么: - 小批量,大参数:张量模型并行更好(例如,批量大小为 1 的推理)。 - 大批量,中等参数:数据并行更好(通信成本在批量上摊销)。

结合数据并行和模型并行
为了最大的可扩展性,结合两者: - 跨数据并行组的数据并行 - 每个数据并行副本内的张量模型并行

示例:并行化卷积神经网络
CNN 有两种具有不同特征的层类型:
| 层类型 | 计算量 | 参数量 | 激活值 | 最佳策略 |
|---|---|---|---|---|
| 卷积层 | 90-95% | 5% | 非常大 | 数据并行 |
| 全连接层 | 5-10% | 95% | 小 | 张量模型并行 |
推荐方法:混合并行化 - 对卷积层应用数据并行(计算密集,参数少) - 对全连接层应用张量模型并行(参数密集,激活值小)

这最小化了通信:卷积层使用 DP(前向/反向传播期间无通信),全连接层使用张量 MP(通信与小批量 × 输出维度成正比)。
示例:并行化 Transformer(Megatron-LM)
Transformer 由自注意力层和前馈(MLP)层组成。Megatron-LM 对两者都应用张量模型并行。
MLP 层
每个 transformer 层包含两个 MLP 块:
\[ \begin{aligned} Y &= \text{GeLU}(X \times A) \\ Z &= \text{Dropout}(Y \times B) \end{aligned} \]
策略: 1. 第一个 MLP(\(X \times A\)):使用分区输出张量并行 - 按列分割 \(A\) → 每个 GPU 计算 \(Y\) 的一部分 - GeLU 是逐元素的 → 独立应用 - 在前向传播中插入恒等算子(无操作),在反向传播中插入 AllReduce
- 第二个 MLP(\(Y \times
B\)):使用减少输出张量并行
- 按行分割 \(B\) → 每个 GPU 计算部分 \(Z\)
- 在前向传播中插入 AllReduce,在反向传播中插入恒等算子

结果:每个 transformer 层仅需两次 AllReduce 操作(一次前向,一次反向)—— 最小通信开销。
自注意力层
对 \(Q\)、\(K\)、\(V\) 投影和注意力输出投影应用类似的分区策略。
扩展结果
Megatron-LM 通过结合以下方式扩展到 512 个 GPU: - 节点内的张量模型并行(2-8 GPU) - 跨节点的数据并行
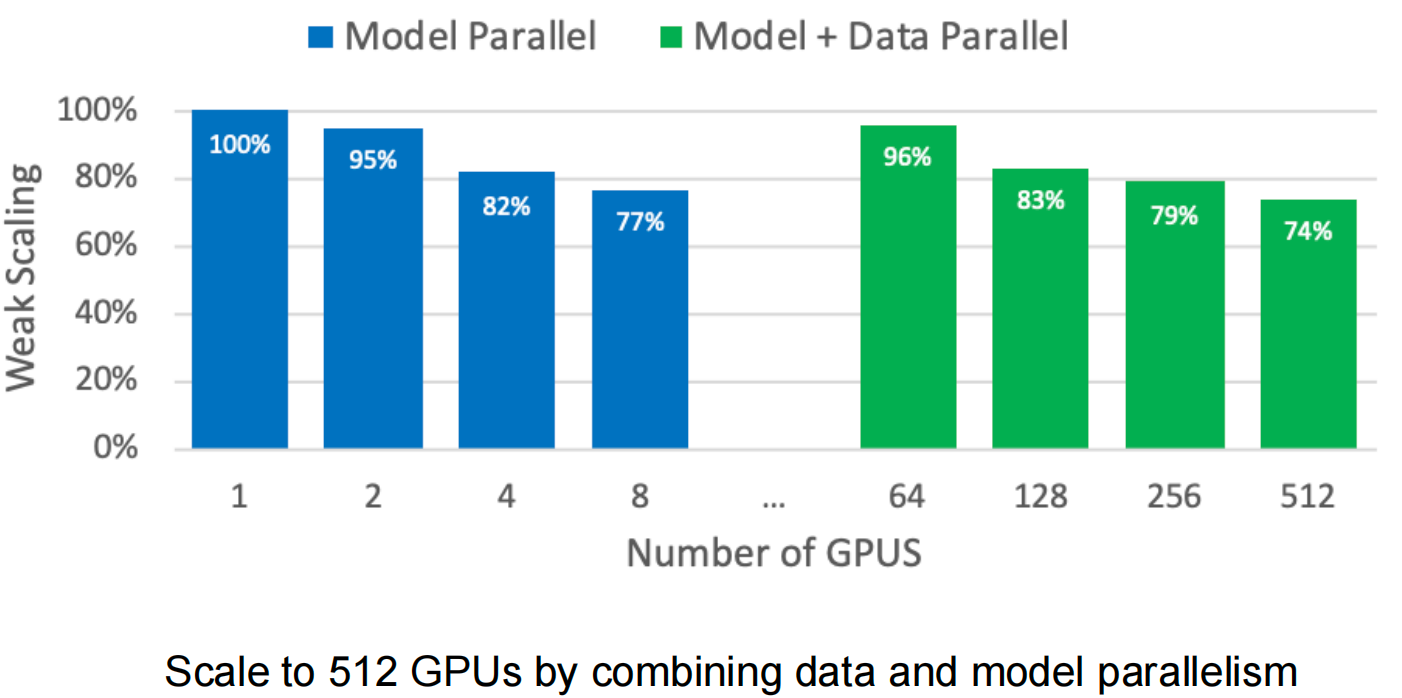
在 512 个 GPU 上对 8.3B 参数模型实现 74% 的弱扩展效率。
流水线模型并行
动机
朴素模型并行的问题:顺序执行导致严重的 GPU 利用率不足。
考虑一个分布在 4 个 GPU 上的 4 层模型:
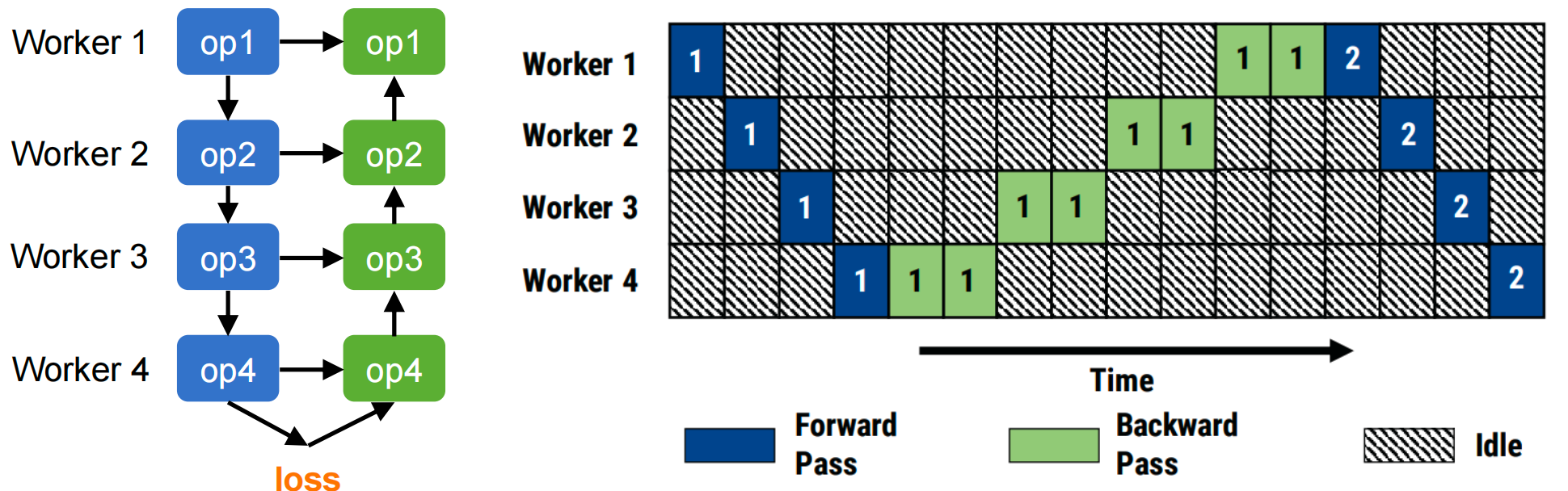
在前向传播期间一次只有一个 GPU 活跃,然后在反向传播期间再次如此。利用率 ≈ 25%!
解决方案:流水线并行——同时处理多个微批次。
基本概念
Mini-batch:每次训练迭代处理的总样本数(例如,32 个样本)
Micro-batch:将 mini-batch 细分为更小的块(例如,4 个微批次 × 每个 8 个样本)
思想:当 GPU 1 处理微批次 2 时,GPU 2 可以处理微批次 1,依此类推。
GPipe 调度
原始 GPipe 调度在开始反向传播之前完成所有前向传播:

气泡时间(空闲期):
\[ \text{BubbleFraction} = \frac{(p-1) \times (t_f + t_b)}{m \times t_f + m \times t_b} = \frac{p-1}{m} \]
其中: - \(p\) = 流水线阶段数 - \(m\) = 微批次数 - \(t_f, t_b\) = 一个微批次的前向/反向传播时间
问题:必须存储所有 \(m\) 个微批次的激活值直到反向传播开始——高内存成本。
1F1B(一前向一反向)调度
改进:交错前向和反向传播以更快地释放激活值内存。

三个阶段: 1. 预热:用前向传播填充流水线(前 \(p\) 个微批次) 2. 稳定状态:交替进行一次前向和一次反向(1F1B 模式) 3. 冷却:用剩余的反向传播排空流水线
优点: - 减少内存:只需存储 \(p\) 个微批次(流水线深度)的激活值,而不是 \(m\) 个总微批次 - 相同的气泡分数:\(\frac{p-1}{m}\)(无性能下降)
在途微批次:GPipe 需要 \(m\),1F1B 仅需要 \(p\) —— 通常 \(p \ll m\)。
交错 1F1B 调度
进一步优化:将每个流水线阶段分成 \(v\) 个更小的子阶段(块)。
每个设备被分配 \(v\) 个非连续的子阶段,而不是一个连续的阶段。

气泡时间减少: \[ \text{BubbleFraction}_{\text{interleaved}} = \frac{1}{v} \times \frac{p-1}{m} \]
权衡: - ✅ 气泡时间减少 \(v\) 倍(更好的 GPU 利用率) - ❌ 通信增加 \(v\) 倍(子阶段之间更频繁的传输)
何时使用:当气泡时间占主导且有高速互连可用时(例如,NVLink、InfiniBand)。
流水线效率分析
提高效率:减少气泡分数 \(\frac{p-1}{m}\) 的两个旋钮
- 增加 \(m\)(更多微批次):
- ✅ 减少气泡时间
- ❌ 注意:大的总批量大小可能损害收敛;小的微批次大小降低 GPU 计算效率
- 减少 \(p\)(更少的流水线阶段):
- ✅ 减少气泡时间
- ❌ 注意:增加每阶段内存需求
典型配置:选择 \(m \geq 4p\) 以实现气泡分数 ≤ 25%。
并行化策略比较

建议:现代大规模训练结合所有三种方法。
3D 并行:结合所有策略
DeepSpeed 和类似框架实现 3D 并行来训练万亿参数模型:

三个正交维度:
- 数据并行:跨数据并行组(外层维度)
- 张量模型并行:层内(例如,注意力/MLP 的 4 路分割)
- 流水线模型并行:跨层(例如,4 个流水线阶段)
示例:800 GPU = 64 数据并行副本 × 2 张量并行 × 4 流水线阶段
扩展结果:
- 在 800 个 A100 GPU 上可训练 1 万亿参数
- 30-40 TFLOPS/GPU 持续吞吐量
- 近线性扩展到数百个 GPU
成功关键:
- 用于张量并行的高速节点内互连(NVLink)
- 用于数据/流水线并行的高带宽节点间网络(InfiniBand)
- 仔细重叠通信和计算
面试复习问答
第 1 部分:核心概念(高频面试问题)
Q1:解释数据并行的工作流程。每个 GPU 在一次训练迭代中做什么?梯度如何同步?
在数据并行中,每个 mini-batch 的数据分发到不同的 GPU,其中每个 GPU 都持有模型参数的完整副本。每个 GPU 独立执行前向和反向传播以计算本地梯度。然后通过 AllReduce 跨所有 GPU 同步梯度,因此每个 GPU 获得相同的聚合梯度。最后,每个 GPU 执行本地参数更新,保持所有模型副本相同。
一次迭代工作流程:
- 前向传播:每个 GPU 使用完整模型在其本地 mini-batch 上计算预测
- 反向传播:每个 GPU 基于其本地损失计算所有参数的梯度
- 梯度同步(AllReduce):跨所有 GPU 聚合梯度,使每个 GPU 都有相同的结果
- 本地权重更新:每个 GPU 使用聚合梯度独立应用优化器步骤
关键不变量:所有 GPU 始终保持相同的参数(每次同步后)。
Q2:主要的 AllReduce 实现有哪些?比较 Ring AllReduce 与 Naive AllReduce 的总通信量,并解释为什么 Ring AllReduce 更具可扩展性。
主要实现:Naive AllReduce、Ring AllReduce、Tree AllReduce、Butterfly AllReduce。
通信量比较(M = 参数大小,N = 工作器数量):
| 算法 | 总通信量 | 每工作器通信量 |
|---|---|---|
| Naive AllReduce | \(N(N-1)M = O(N^2 M)\) | \((N-1)M\) |
| Ring AllReduce | \(2(N-1)M \approx 2NM\) | \(2 \cdot \frac{N-1}{N} \cdot M \approx 2M\) |
为什么 Ring AllReduce 更具可扩展性:
- 每工作器通信量是常数:无论 N 如何,每个工作器发送/接收大约 \(2M\)。添加更多 GPU 不会增加任何单个工作器的通信负担。
- 完全带宽利用:环上的所有链路并行传输数据,最大化聚合带宽。
- 无瓶颈节点:与参数服务器或树根不同,没有单个工作器处理不成比例的流量。
相比之下,Naive AllReduce 的每工作器通信量为 \(O(N)\),随着工作器的增加而线性下降。
Q3:在使用 Adam 优化器的混合精度训练中,对于具有 Ψ 个参数的模型,每个 GPU 需要存储什么,每个组件占用多少内存?
| 组件 | 精度 | 大小 |
|---|---|---|
| FP16 参数 | FP16 | \(2\Psi\) 字节 |
| FP16 梯度 | FP16 | \(2\Psi\) 字节 |
| FP32 参数副本(主权重) | FP32 | \(4\Psi\) 字节 |
| FP32 梯度副本 | FP32 | \(4\Psi\) 字节 |
| FP32 一阶矩(动量) | FP32 | \(4\Psi\) 字节 |
| FP32 二阶矩(方差) | FP32 | \(4\Psi\) 字节 |
| 总计 | \(20\Psi\) 字节 |
解释:
- FP16 参数和梯度(\(2\Psi + 2\Psi = 4\Psi\)):用于实际的前向/反向计算(更快,内存更少)。
- FP32 优化器状态(\(4\Psi + 4\Psi + 4\Psi + 4\Psi = 16\Psi\)):Adam 优化器需要 FP32 精度以保证数值稳定性。这包括主权重副本、梯度副本、一阶矩(动量)和二阶矩(方差)。
这个 \(4\Psi + 16\Psi = 20\Psi\) 分解是理解 ZeRO Stage 1/2/3 内存分区的基础。
第 2 部分:ZeRO 深入探讨
Q4:用你自己的话解释 ZeRO Stage 1/2/3。每个阶段分区什么,保持什么被复制?
ZeRO Stage 1:在 N 个 GPU 之间分区优化器状态(FP32 参数副本、动量、方差和 FP32 梯度副本)。每个 GPU 仅存储优化器状态的 \(\frac{1}{N}\)。保持复制:每个 GPU 上的完整 FP16 参数和完整 FP16 梯度。
ZeRO Stage 2:在 Stage 1 的基础上额外分区梯度。每个 GPU 仅存储优化器状态和梯度的 \(\frac{1}{N}\)。保持复制:每个 GPU 上的完整 FP16 参数。
ZeRO Stage 3:分区所有内容——优化器状态、梯度和参数。每个 GPU 仅存储所有模型状态的 \(\frac{1}{N}\)。没有被复制;参数在前向/反向传播期间按需收集并在之后丢弃。
渐进式分区总结:
| 阶段 | 分区内容 | 复制内容 |
|---|---|---|
| ZeRO-1 | 优化器状态(\(16\Psi\)) | FP16 参数(\(2\Psi\))+ FP16 梯度(\(2\Psi\)) |
| ZeRO-2 | 优化器状态 + 梯度(\(18\Psi\)) | FP16 参数(\(2\Psi\)) |
| ZeRO-3 | 所有内容(\(20\Psi\)) | 无 |
Q5:在一次完整的训练迭代中演练 ZeRO Stage 1。前向传播、反向传播、权重更新和参数同步期间发生了什么?涉及哪些通信操作?
前向传播:每个 GPU 使用其本地完整 FP16 参数正常计算前向传播。不需要通信。
反向传播:每个 GPU 在其本地 mini-batch 上计算所有参数的完整 FP16 梯度。然后执行 AllReduce,使每个 GPU 获得跨所有工作器的相同聚合梯度。
权重更新:每个 GPU 使用聚合梯度仅对其拥有的分区更新其本地 \(\frac{1}{N}\) 的优化器状态(应用 Adam 步骤)。这仅为该分区生成更新的 FP16 参数值。
参数同步:AllGather 操作从所有 GPU 收集更新的 FP16 参数分区,因此每个 GPU 重建完整的更新 FP16 参数集。
通信操作: - AllReduce(梯度同步):\(\approx 2M\) 通信 - AllGather(参数重组):\(\approx M\) 通信
Q6:ZeRO Stage 2 的反向传播阶段与 Stage 1 有何不同?为什么梯度可以在反向传播期间被分区?
Stage 1:在反向传播完成后对梯度执行完整的 AllReduce —— 每个 GPU 最终都有完整的聚合梯度。
Stage 2:用 Reduce-Scatter 替换 AllReduce —— 每个 GPU 仅接收其自己分区的聚合梯度。不存储其他分区的梯度。
为什么梯度可以在反向传播期间被分区:
反向传播逐层进行。一旦所有 GPU 都计算了给定层的梯度,该层的 Reduce-Scatter 可以立即执行——不需要等待所有层完成。在 Reduce-Scatter 完成一层后,每个 GPU 丢弃属于其他 GPU 分区的梯度部分,立即释放内存。
这是可能的,因为每个 GPU 只需要其负责更新的参数的梯度。反向传播的逐层性质使得重叠梯度计算与梯度通信成为可能,隐藏延迟。
Q7:ZeRO Stage 3 在前向和反向传播期间都需要 AllGather 来检索完整参数。为什么总通信量是基线的 1.5 倍而不是 2 倍或 3 倍?提供定量分析。
基线(标准数据并行):每次迭代一次 AllReduce = 每工作器 \(2M\) 通信(AllReduce = Reduce-Scatter + AllGather,每个 \(\approx M\))。
ZeRO Stage 3 每工作器:
| 阶段 | 操作 | 通信量 |
|---|---|---|
| 前向 | AllGather 参数(每层前收集,之后丢弃) | \(M\) |
| 反向 | AllGather 参数(因为前向后丢弃所以需要再次收集) | \(M\) |
| 反向 | Reduce-Scatter 梯度(分区聚合梯度) | \(M\) |
| 总计 | \(3M\) |
比率:\(\frac{3M}{2M} = 1.5\times\) 基线。
为什么不是 2 倍或 3 倍? - 不是 2 倍,因为反向 Reduce-Scatter 替换了基线的 AllReduce——它是相同的梯度同步,只是以分区形式。 - 不是 3 倍,因为两次 AllGather(前向 + 反向)每次仅花费 \(M\),而不是 \(2M\)。它们一起增加 \(2M\),替换了基线的隐式参数访问(因为参数被复制,所以通信成本为零)。 - 相对于基线的净额外成本:\(+M\)(前向传播参数的一次额外 AllGather),给出 \(3M\) vs \(2M\) = 1.5 倍。
第 3 部分:具体计算——7B 模型内存
Q8:计算使用 N = 64 个 GPU 的 7B 参数模型在所有 ZeRO 阶段的每 GPU 内存。
给定:\(\Psi = 7\text{B}\),\(N = 64\)
基线(无分区): \[20 \times 7\text{B} = 140\text{ GB}\] 这超过了 A100-80GB —— 基线数据并行甚至无法加载模型!
每个阶段的详细计算:
| 阶段 | 公式 | 计算 | 结果 |
|---|---|---|---|
| 基线 DP | \(20\Psi\) | \(20 \times 7\text{B}\) | 140 GB(内存溢出!) |
| ZeRO-1 | \(4\Psi + \frac{16\Psi}{N}\) | \(28\text{ GB} + 1.75\text{ GB}\) | 29.75 GB |
| ZeRO-2 | \(2\Psi + \frac{18\Psi}{N}\) | \(14\text{ GB} + 1.97\text{ GB}\) | 15.97 GB |
| ZeRO-3 | \(\frac{20\Psi}{N}\) | \(\frac{140}{64}\) | 2.19 GB |
公式分解:
- 基线:FP16 参数(\(2\Psi\))+ FP16 梯度(\(2\Psi\))+ FP32 优化器状态(\(16\Psi\))= \(20\Psi\)
- ZeRO-1:FP16 参数(\(2\Psi\))+ FP16 梯度(\(2\Psi\))+ 分区优化器状态(\(\frac{16\Psi}{N}\))= \(4\Psi + \frac{16\Psi}{N}\)
- ZeRO-2:FP16 参数(\(2\Psi\))+ 分区梯度(\(\frac{2\Psi}{N}\))+ 分区优化器状态(\(\frac{16\Psi}{N}\))= \(2\Psi + \frac{18\Psi}{N}\)
- ZeRO-3:所有内容分区 = \(\frac{(2+2+16)\Psi}{N} = \frac{20\Psi}{N}\)
关键面试要点:
- 使用基线 DP 的 7B 模型无法装入单个 A100-80GB —— 140 GB 的内存占用是主要限制
- ZeRO-1 将其降至约 30 GB —— 舒适地装入 A100-80GB
- ZeRO-3 将模型状态仅减少到约 2.2 GB —— 但请注意,激活值内存是额外的,取决于批量大小和序列长度可能很大
- 从基线到 ZeRO-1 的跳跃提供了最大的绝对节省(140 GB → 30 GB),而 ZeRO-2 和 ZeRO-3 以更多通信复杂性为代价提供了进一步的减少



