
11868 LLM Sys: Tokenization and Embedding
分词与嵌入
什么是分词?
分词是将文本拆分为可以被语言模型处理的基本单元(标记)的过程。许多单词并不映射到单个标记——例如,“indivisible”可能会被拆分为多个子词标记。
一般流程如下: 1. 分词器:将文本拆分为标记 ID 2. 嵌入表查找:将标记 ID 转换为向量表示
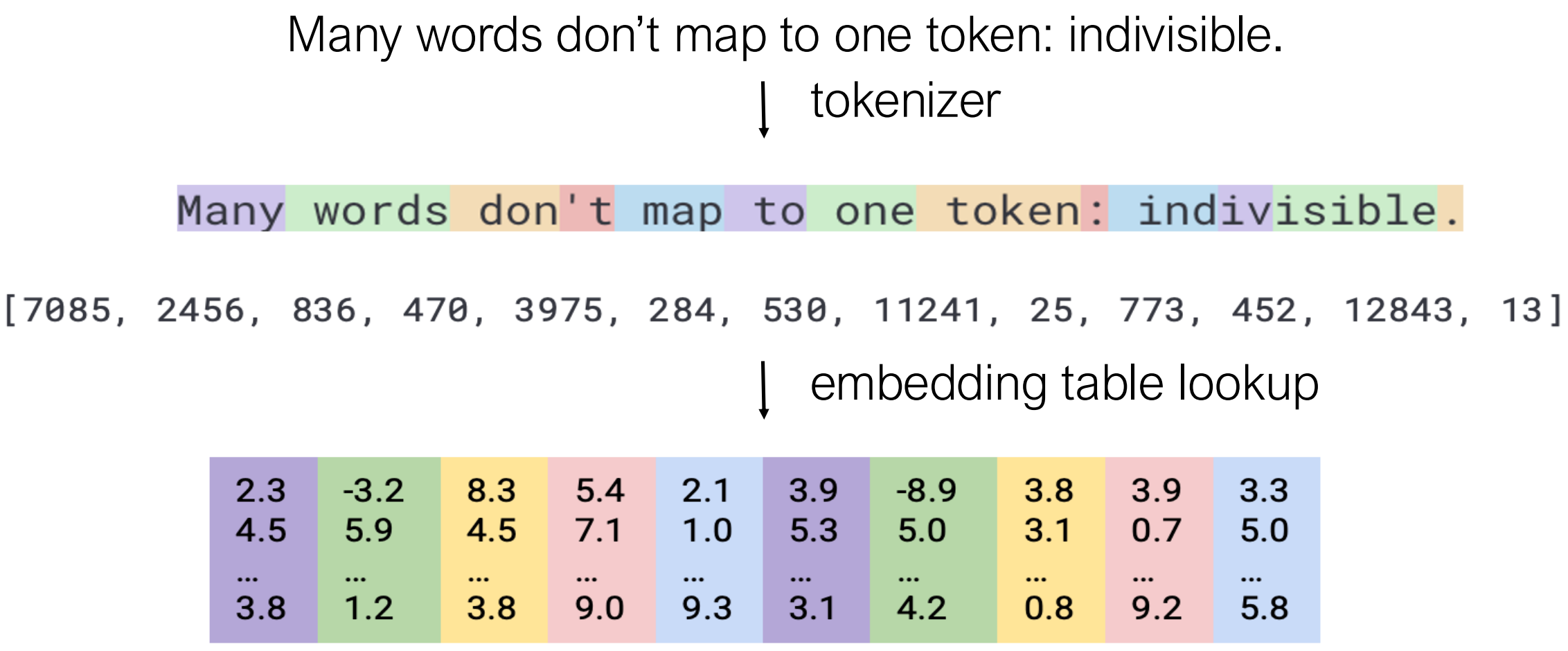
简单的分词方法
基于词的分词
方法:通过空格和标点符号拆分文本
示例: - 英语、法语、德语、西班牙语效果良好 -
特殊处理:数字用特殊标记 [number] 替代
示例: 1
2
3"The most eager is Oregon which is enlisting 5,000 drivers in the country's biggest experiment."
↓
["The", "most", "eager", "is", "Oregon", "which", "is", "enlisting", "5,000", "drivers", ...]
挑战:什么才算是一个“单词”? - 附加词: “Bob’s” - 复合词: “handyman” - 多词表达: “do-it-yourself” - 缩写: “isn’t”
优缺点: - ✅ 实现简单 - ❌ 超出词汇表(OOV)标记(例如,“Covid”) - ❌ 词汇大小与未知标记之间的权衡: - 较小的词汇 → 较少的参数,更多的 OOV - 较大的词汇 → 更多的参数,较少的 OOV - ❌ 对于没有空格的语言(中文、日文、韩文、柬文)困难
基于字符的分词
方法:每个字母和标点符号都是一个标记
1 | "The most eager is Oreg..." |
优点: - ✅ 词汇量非常小(除了像中文这样的语言) - ✅ 没有 OOV 标记
缺点: - ❌ 序列较长 - ❌ 标记不代表语义含义
子词级别的分词
目标
- 中等大小的词汇
- 无 OOV 标记
- 通过子词序列表示稀有单词
字节对编码(BPE)
起源:最初由 Philip Gage(1994)开发用于数据压缩
构建词汇的算法: 1. 用所有字符作为标记(加上单词结束符)及其频率初始化词汇 2. 循环直到词汇大小达到容量: 1. 统计语料库中连续的标记对 2. 排名并选择最频繁的对 3. 合并该对形成新标记,添加到词汇中 3. 输出最终词汇
示例:
1 | 初始语料: |
分词过程: 1. 通过空格或其他分隔符拆分文本 2. 重复: - 贪婪地找到与 BPE 字典中标记匹配的最长前缀 - 拆分并处理剩余部分,直到没有更多文本
示例输出: 1
2
3"The most eager is Oregon which is enlisting 5,000 drivers in the country's biggest experiment."
↓
["The", "most", "eager", "is", "Oregon", "which", "is", "en", "listing", "5,000", "driver", "s", "in", "the", "country", "'s", "big", "g", "est", "experiment", "."]
代码示例:
- 官方示例:llmsys_code_examples/tokenization
- 我的实现:请参见 CS336
作业 1:BPE 分词器 以获取完整的从零实现,包括:
- 带增量对更新的 BPE 训练算法
- 使用多进程的并行语料处理
- 内存优化技术
- 完整的编码器/解码器实现
- 代码:GitHub - CS336 Transformer
信息论词汇(VOLT)
动机
寻找最佳词汇通常需要: - 多次完整的训练和测试周期 - 尝试不同的词汇大小(1k、10k、30k 标记) - 评估每种配置的 NLG/MT 性能
挑战:我们能在不进行完整训练的情况下预测良好的词汇吗?
测量词汇质量
1. 压缩指标: - 每标记字节数(BPT): \[BPT = \frac{\text{utf8 字节}}{\text{标记}}\]
- 归一化序列长度(NSL): \[NSL = \frac{\text{标记}}{\text{LLaMA 中的标记}}\]
2. 归一化熵: \[\mathcal{H}(v) = -\frac{1}{l_v}\sum_{i \in v} P(i)\log P(i)\]
其中 \(l_v\) 是词汇 \(v\) 中所有标记的平均字符数。
解释:测量每个字符的语义信息。越小越好(歧义少,更容易生成)。
示例: 1
2
3
4
5词汇 1: {a: 200, e: 90, c: 30, t: 30, s: 90}
→ H(v) = 1.37
词汇 2: {a: 100, aes: 90, cat: 30}
→ H(v) = 0.14 ✓ 更好!
词汇的边际效用(MUV)
定义: \[M_{v_k \rightarrow v_{k+m}} = -\frac{H(v_k) - H(v_{k+m})}{m}\]
- 价值:归一化熵(语义信息)
- 成本:词汇大小
- MUV:相对于大小的归一化熵的负梯度
- 解释:每增加一个标记带来的价值
关键发现:MUV 预测性能
经验观察: - 最大 MUV 与最佳 BLEU 分数相关 - MUV 和 BLEU 在约 2/3 的任务中相关 - MUV 作为词汇质量的 粗略评估指标
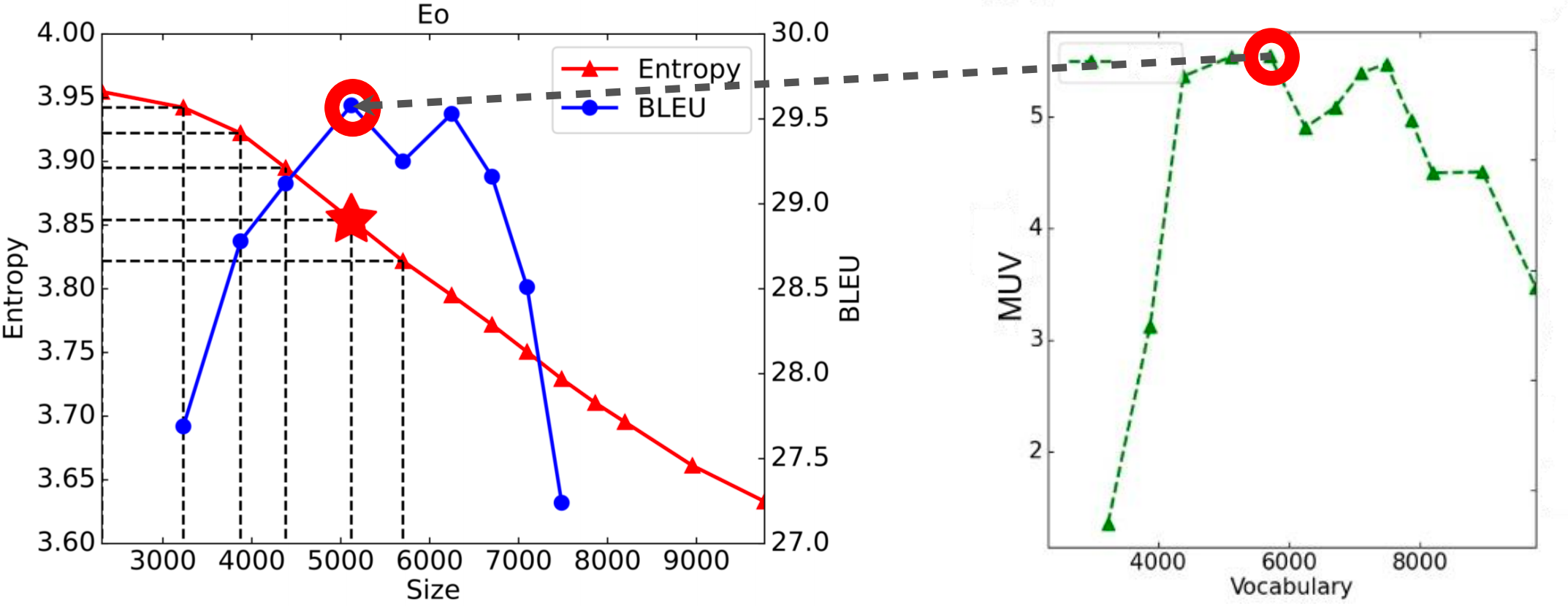
LLM 中的实际考虑
1. 语料去重和过滤
LLaMA 3 去重策略: - URL 级去重:移除重复的 URL - 文档级去重:使用 MinHash - 行级去重:对每 30M 文档使用 SHA-1 64 位哈希 - 移除模板(导航菜单、Cookie 警告、联系信息)
过滤: - 一行内的 N-gram 重复 - “脏字”计数 - 标记分布的 KL 散度与语料库差异过大
2. 现代子词分词方法
字节级 BPE(BBPE): - 将语言视为 Unicode 字节序列 - 对所有语言通用 - 无需语言特定的预处理
WordPiece: - 类似于 BPE,但合并最大化 \(P(b|a)\) 的对 - 用于 BERT
SentencePiece: - 对空格和标点的统一处理 - 将空格 ’ ’ 替换为 _ (U+2581) - 然后拆分为字符并应用 BPE - 语言无关的方法
3. 处理代码:预分词
使用正则表达式智能地拆分序列:
GPT-4 模式: 1
(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}|...
组成部分: - 英语缩写 - 单词(可选的前导非字母数字) - 数字(一次 1-3 个) - 非字母数字字符 - 换行符 - 尾随空格
示例:.append →
单个标记(保持方法名称不变)
4. 处理数字
挑战:传统分词将每个数字单独处理,使得算术运算变得困难。
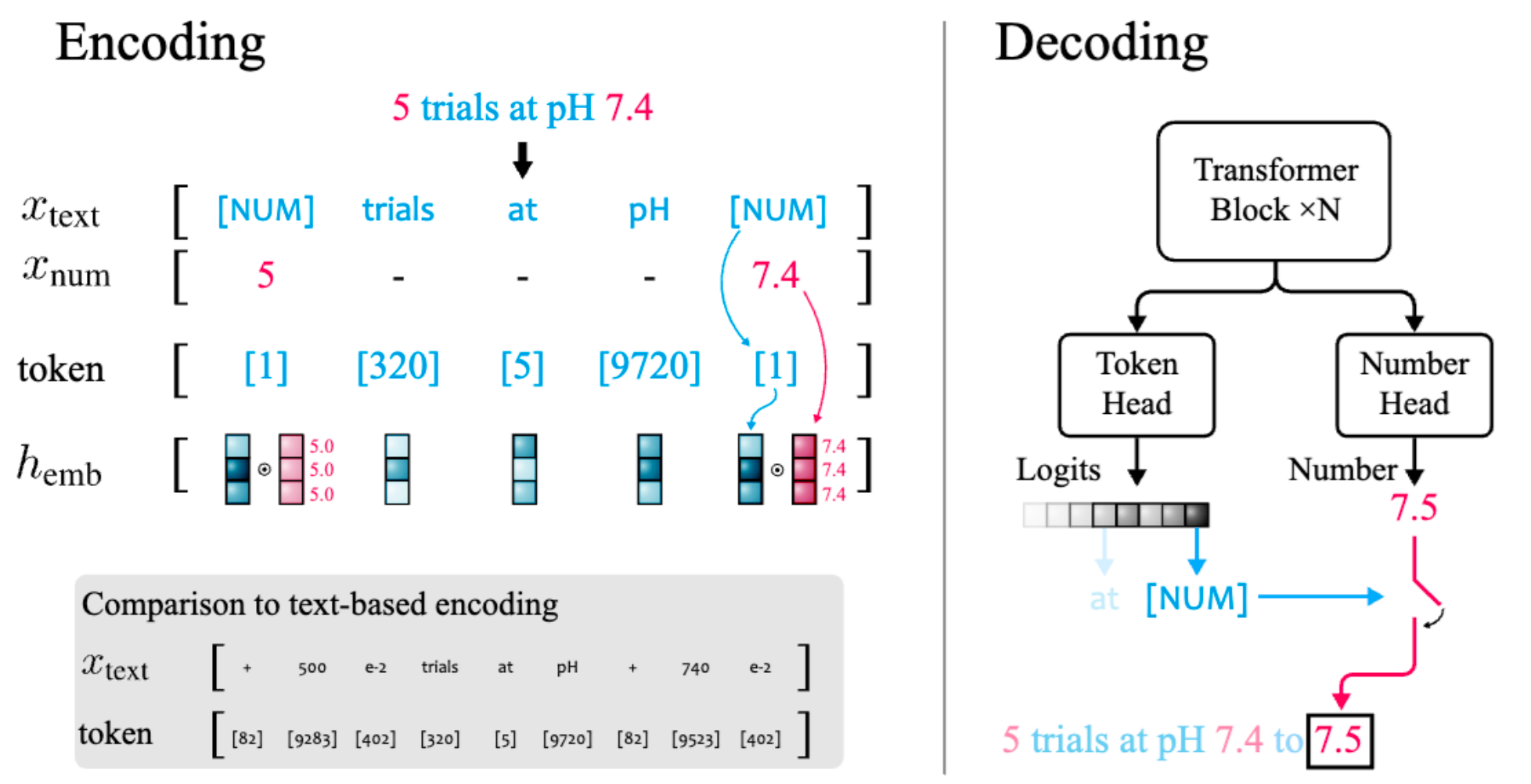
xVal 方法(Golkar 等,2023): - 用特殊标记
[NUM] 替换数字 - 在离散标记嵌入旁边添加连续数值嵌入 -
双头解码器: - 标记头:预测下一个标记(logits) -
数字头:预测数值
5. 多语言词汇
LLaMA 3 演变: - LLaMA 2:32k 标记 - LLaMA 3.1:128k 标记 - 100k 来自 OpenAI 的 tiktoken(从 200k 减少) - 28k 分配给多语言支持
构建方法:
- 联合 BPE:合并来自多种语言的文档(LLaMA 3 中有 176 种),在联合语料上应用 BPE
- 每种语言 BPE + 合并:为每种语言生成相同数量的标记,然后合并
- ALP 平衡:通过平衡各语言的平均对数概率分配容量
词汇共享的好处:
共享标记使跨语言转移成为可能。例如 - “television”
在多种语言中的表现: 1
2
3
4英语: television 西班牙语: televisión
法语: television 意大利语: television
荷兰语: televisie 葡萄牙语: televisão
瑞典语: television 芬兰语: televisio
相似的拼写 → 共享的子词标记 → 多语言理解
词汇共享与多语言性能
实验设置
Yuan 等(ACL 2024)的研究调查了: 1. 使用双语平行数据构建 10k 指令微调数据集 2. 仅微调 LLaMA-7B 嵌入层 3. 评估翻译性能: - 双语:监督语言对 - 多语言:所有其他方向
四个性能象限
| 象限 | 双语性能 | 多语言性能 | 示例语言 |
|---|---|---|---|
| 互惠 | ↑ | ↑ | cs, da, fr, de |
| 利他 | ↓ | ↑ | ar, vi, zh, ko |
| 停滞 | ↓ | ↓ | km, lo, gu, te |
| 自私 | ↑ | ↓ | hi |
关键见解:在双语数据上微调并不总是对监督方向有利!
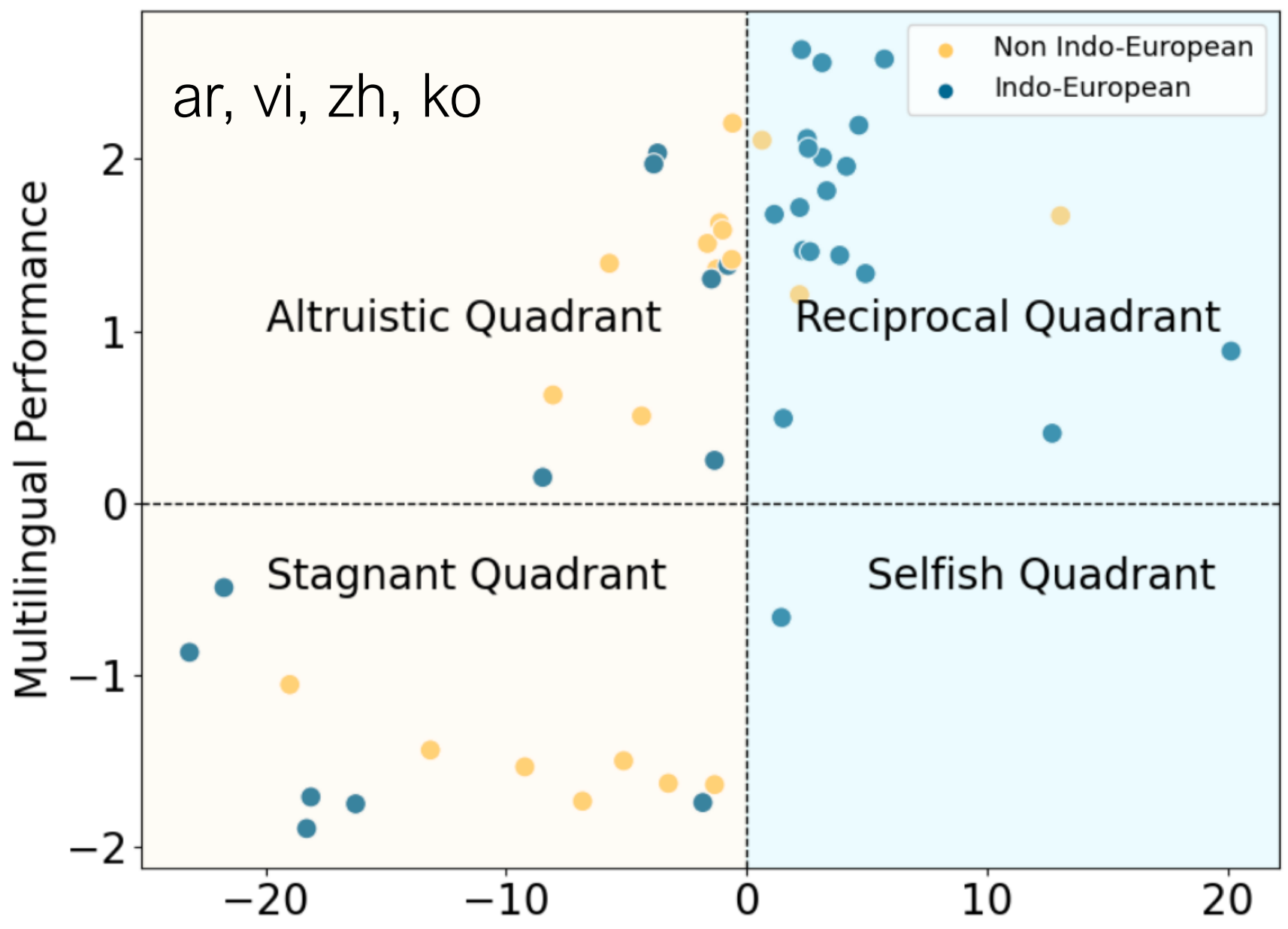
语言家族的重要性
- 印欧语言:大多位于互惠象限
- 非印欧语言:分布更为多样,包括利他和停滞象限
停滞象限:过度分词问题
根本原因:字节 BPE 生成的字节序列比某些语言的字符计数更长。
示例: 1
饕 [tāo](贪吃)→ 三个标记:[227, 234, 260]
解决方案 - 缩短: - 移除常见字节前缀(例如,许多汉字的 227) - 改善双语和多语言性能
实验结果: 1
2
3
4方向:en→km en→lo en→gu en→te
完全微调: 10.1 7.0 10.0 17.0
扩展: 11.9 6.9 0.5 7.2
缩短: 12.7 9.4 11.3 21.6 ✓ 最佳
建议:对于过度分词的语言,缩短比扩展词汇更有效。
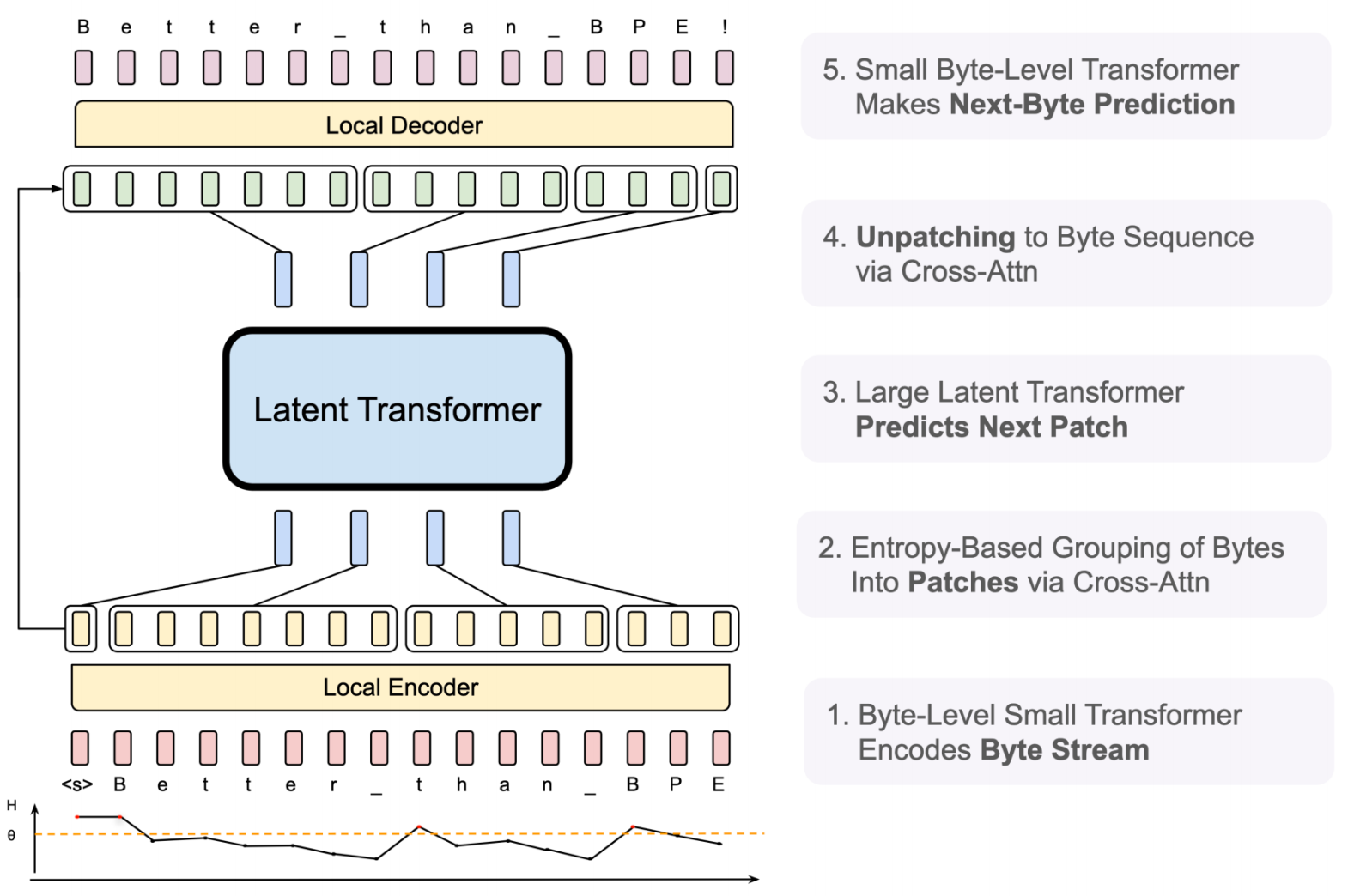
无分词器模型:字节潜在变换器(BLT)
动机:完全消除分词器,直接处理字节。
架构(Pagnoni 等,2024):
- 字节级小型变换器:编码字节流
- 基于熵的分组:通过交叉注意力将字节分组为补丁
- 大型潜在变换器:预测下一个补丁(主要计算)
- 解补丁:通过交叉注意力将补丁转换回字节序列
- 小型字节级变换器:进行下一个字节预测
关键好处: - ✅ 无需分词器训练 - ✅ 对所有语言通用 - ✅ 处理任何字节流(文本、代码、数据) - ✅ 动态粒度(基于熵的补丁)
权衡: - 更复杂的架构 - 两级变换器层次 - 交叉注意力开销
总结
关键要点
- 子词分词(BPE):
- 迭代合并最频繁的标记对
- 平衡词汇大小和 OOV 率
- 广泛使用(GPT、LLaMA 等)
- 信息论词汇(VOLT):
- 使用归一化熵测量词汇质量
- MUV(词汇的边际效用)预测性能
- 解决熵约束的最优传输问题
- 避免昂贵的网格搜索
- 实际考虑:
- 使用正则表达式进行代码的预分词
- 对数字的特殊处理(xVal 方法)
- 多级语料去重
- 多语言词汇分配
- 多语言挑战:
- 词汇共享使跨语言转移成为可能
- 过度分词对某些语言有害(停滞象限)
- 缩短字节序列比扩展词汇更有效
- 语言家族影响共享好处
- 未来方向:
- 无分词器模型(BLT)显示出潜力
- 简单性与效率之间的权衡
- 通过基于熵的补丁实现动态粒度
参考文献
- Rico Sennrich 等. “Neural Machine Translation of Rare Words with Subword Units.” ACL 2016.
- Xu, Zhou, Gan, Zheng, Li. “Vocabulary Learning via Optimal Transport for Neural Machine Translation.” ACL 2021.
- Kudo 和 Richardson. “SentencePiece: A simple and language independent approach to subword tokenization.” EMNLP 2018.
- Dagan 等. “Getting the most out of your tokenizer for pre-training and domain adaptation.” ICML 2024.
- Golkar 等. “xVal: A Continuous Numerical Tokenization for Scientific Language Models.” 2023.
- Zheng 等. “Allocating large vocabulary capacity for cross-lingual language model pre-training.” EMNLP 2021.
- Liang 等. “XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models.” EMNLP 2023.
- Yuan 等. “How Vocabulary Sharing Facilitates Multilingualism in LLaMA?” ACL 2024.
- Pagnoni 等. “Byte Latent Transformer: Patches Scale Better Than Tokens.” 2024.
演示工具
交互式分词器演示: - LLaMA 分词器 - GPT 分词器
本文基于 CMU 11-868 LLM 系统的讲义材料,由 Lei Li 提供。


