
15642 机器学习系统:Transformer、注意力机制与优化
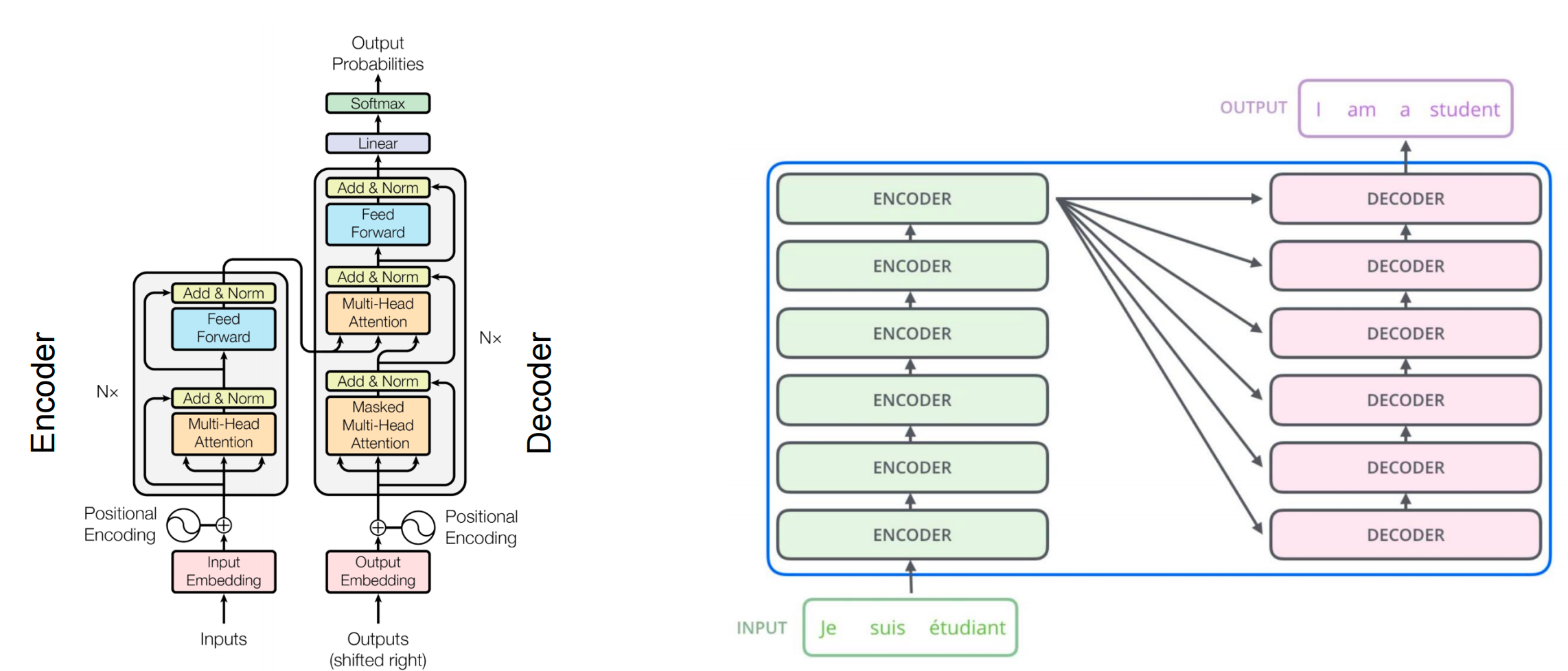
Transformer、注意力机制与优化
课程:15-442/15-642 机器学习系统 授课教师:Tianqi Chen 和 Zhihao Jia 卡内基梅隆大学
注意力机制
注意力机制是一种使用权重组合各个状态的方法。
基本概念
对于来自前一层输入 \(x_1, x_2, x_3, x_4\) 的隐藏状态 \(h_1, h_2, h_3, h_4\):
\[ h_t = \sum_{i=1}^{t} s_i x_t \]
其中 \(s_i\) 是”注意力分数”,用于计算位置 \(i\) 的输入与当前隐藏输出的相关程度。
自注意力机制
自注意力机制将查询(query)和一组键值对(key-value pairs)映射到输出。

数学公式
\[ A(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V \]
其中: - Q (查询):\(N \times d\) 矩阵 - K (键):\(N \times d\) 矩阵 - V (值):\(N \times d\) 矩阵 - d:键/查询/值向量的维度 - N:序列长度
计算步骤
从输入嵌入计算查询、键和值:
- \(Q = X W^Q\)
- \(K = X W^K\)
- \(V = X W^V\)
计算注意力分数:\(S = QK^T\)(大小:\(N \times N\))
按 \(\sqrt{d}\) 缩放:\(S' = S / \sqrt{d}\)
应用 softmax:\(A = \text{softmax}(S')\)
与值相乘:\(O = AV\)
多头自注意力机制
多头注意力通过在输入和输出上使用不同的线性变换来并行化注意力层。
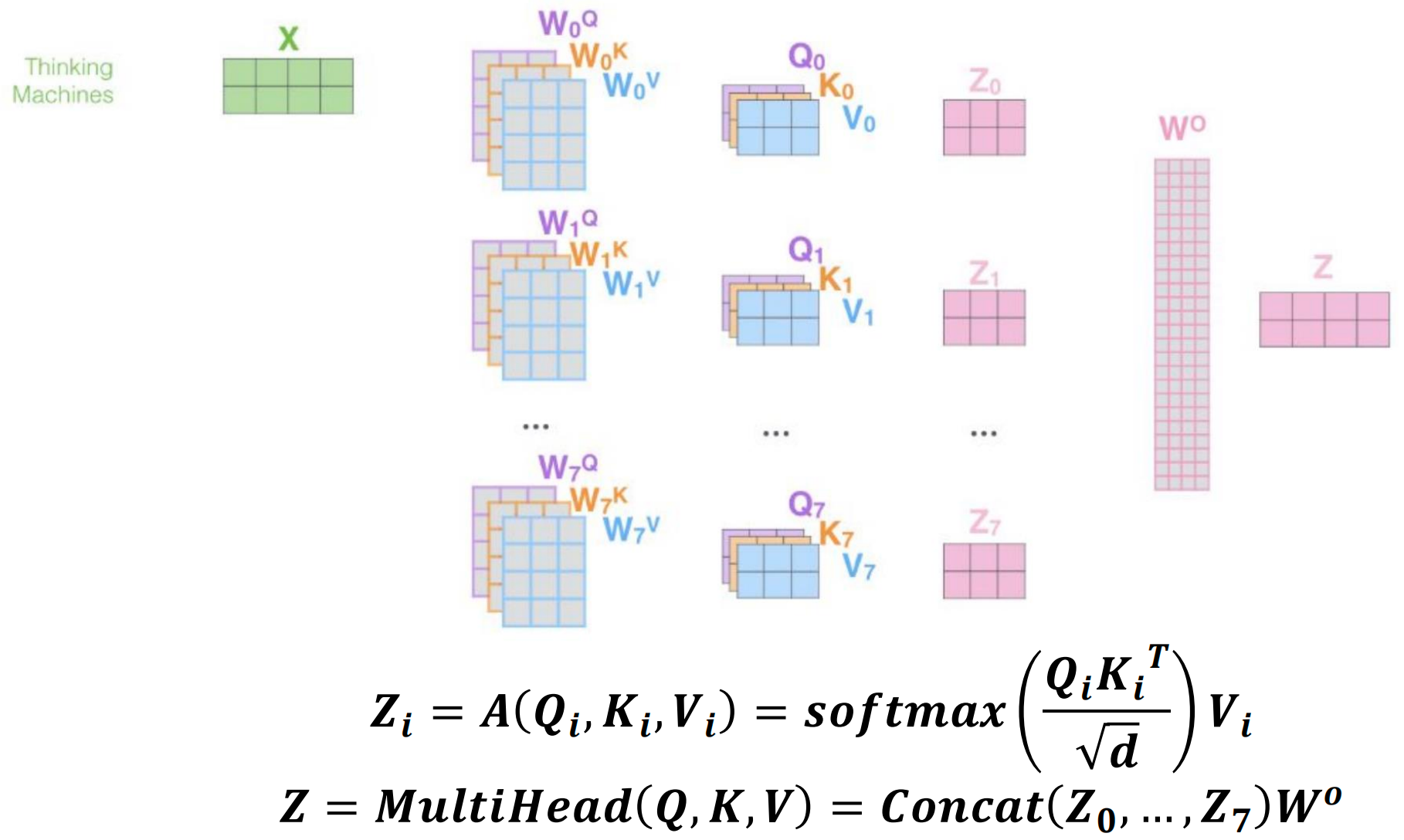
优势
- 更多并行性:可以同时处理多个表示子空间
- 降低每个头的计算成本:每个头处理更小的维度
公式
对于每个头 \(i\): \[ Z_i = A(Q_i, K_i, V_i) = \text{softmax}\left(\frac{Q_i K_i^T}{\sqrt{d}}\right)V_i \]
最终输出: \[ Z = \text{MultiHead}(Q, K, V) = \text{Concat}(Z_0, \ldots, Z_7)W^O \]
通常使用 8 个头,每个头处理 \(d/8\) 维子空间。
GPU上计算注意力的挑战
标准注意力计算
朴素方法:\(O = \text{Softmax}(QK^T)V\)
工作流程: 1. \(A = QK^T\):\(N \times N\) 矩阵 2. \(A = \text{mask}(A)\)(用于因果注意力) 3. \(A = \text{softmax}(A)\):\(N \times N\) 矩阵 4. \(O = AV\):\(N \times d\) 矩阵
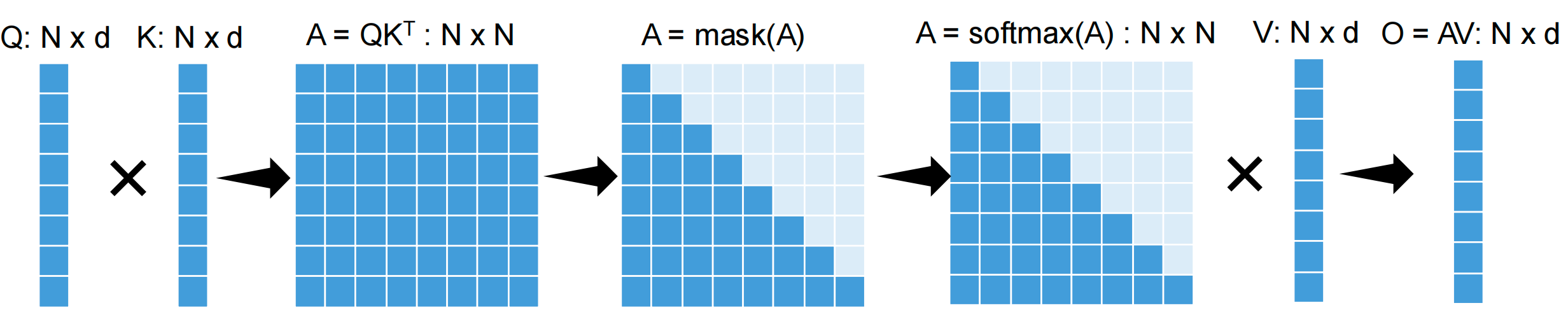
主要挑战
- 大型中间结果:\(O(N^2)\) 注意力矩阵
- 重复从 GPU 设备内存读写:内存带宽瓶颈
- 无法扩展到长序列:二次方内存需求
GPU 内存层次结构
NVIDIA A100 GPU: - 每块共享内存 (SRAM):19 TB/s 带宽,20 MB 容量 - 块内所有线程可读写 - 快速但容量小 - 设备全局内存 (HBM - High Bandwidth Memory,高带宽内存):1.5 TB/s 带宽,80 GB 容量 - 所有线程可读写 - 比 SRAM 慢约 12.6 倍 - 容量大但访问较慢
HBM(高带宽内存) 是 GPU 的主内存 - 它有很大的容量但比片上 SRAM 慢得多。FlashAttention 的核心优化就是通过尽可能在快速的 SRAM 中完成计算来最小化 HBM 访问。

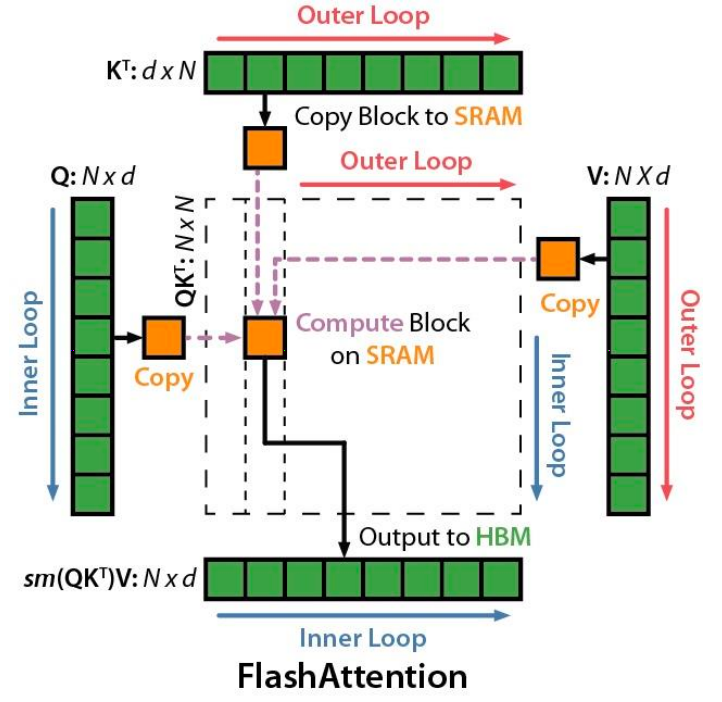
FlashAttention:IO感知的精确注意力
核心思想
通过分块计算注意力来减少全局内存访问
两个主要技术
1. 分块(Tiling)
重构算法以逐块将查询/键/值从全局内存加载到共享内存:
- 从 HBM 逐块加载输入到 SRAM
- 在片上计算相对于该块的注意力输出
- 通过缩放更新设备内存中的输出
2. 重计算(Recomputation)
不存储前向传播的注意力矩阵,在反向传播中重新计算
权衡:增加 FLOPs 但减少内存 I/O
在 GPU 中,带宽是瓶颈
| 指标 | 标准方法 | FlashAttention |
|---|---|---|
| GFLOPs | 66.6 | 75.2 (+13%) |
| 全局内存访问 | 40.3 GB | 4.4 GB (-89%) |
| 运行时间 | 41.7 ms | 7.3 ms (快5.7倍) |
安全 Softmax 与在线 Softmax
问题:16位浮点数的最大值为 65504(< \(e^{12}\))
解决方案:计算向量 \(x\) 的 softmax 为:
\[ m(x) := \max_i x_i \] \[ f(x) := [e^{x_1-m(x)}, \ldots, e^{x_n-m(x)}] \] \[ \ell(x) := \sum_i f(x)_i \] \[ \text{softmax}(x) := \frac{f(x)}{\ell(x)} \]
对于两个向量 \(x^{(1)}\) 和 \(x^{(2)}\):
\[ m(x) = m([x^{(1)} \, x^{(2)}]) = \max(m(x^{(1)}), m(x^{(2)})) \]
\[ f(x) = [e^{m(x^{(1)})-m(x)} f(x^{(1)}), \, e^{m(x^{(2)})-m(x)} f(x^{(2)})] \]
\[ \ell(x) = e^{m(x^{(1)})-m(x)} \ell(x^{(1)}) + e^{m(x^{(2)})-m(x)} \ell(x^{(2)}) \]
FlashAttention-2 算法

输入:HBM 中的矩阵 \(Q, K, V \in \mathbb{R}^{N \times d}\),块大小 \(B_c\), \(B_r\)
关键步骤: 1. 将 \(Q\) 分成 \(T_r = \lceil N/B_r \rceil\) 个大小为 \(B_r \times d\) 的块 2. 将 \(K, V\) 分成 \(T_c = \lceil N/B_c \rceil\) 个大小为 \(B_c \times d\) 的块 3. 对每个查询块 \(i\): - 从 HBM 加载 \(Q_i\) 到 SRAM - 初始化输出 \(O_i^{(0)} = 0\),统计量 \(\ell_i^{(0)} = 0\),\(m_i^{(0)} = -\infty\) - 对每个键/值块 \(j\): - 从 HBM 加载 \(K_j, V_j\) 到 SRAM - 计算 \(S_i^{(j)} = Q_i K_j^T\) - 使用在线 softmax 更新统计量 - 计算部分输出并累积 - 将最终的 \(O_i\) 写回 HBM
并行化策略
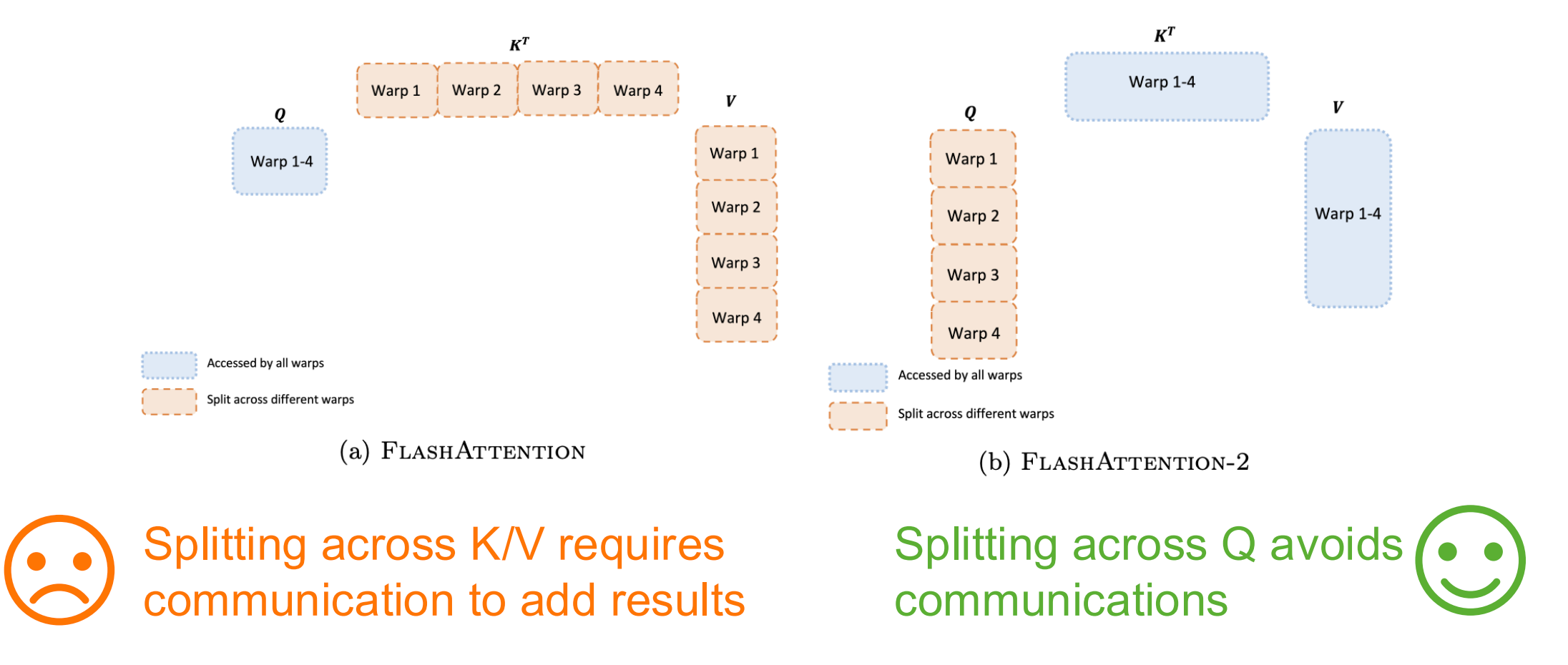
线程块级别: - 步骤1:将不同的头分配给不同的线程块(16-64个头) - 步骤2:将不同的查询分配给不同的线程块 - 为什么不划分键/值? 线程块之间无法通信;在划分键/值时无法执行 softmax
Warp 级别: - FlashAttention:跨 K/V 分割需要通信来相加结果 ❌ - FlashAttention-2:跨 Q 分割避免通信 ✅
为什么前向传播和反向传播的并行化策略不同?
前向传播(按行/查询并行化): - 计算 \(O = \text{softmax}(QK^T)V\) - 每个线程块独立处理不同的查询行 - 不需要通信 - 不同行完全独立 - 就像学生们各自独立做不同的题目
反向传播(按列/键值并行化): - 计算梯度需要更新 \(dQ\): \[dQ_i = dQ_i + dS^{(j)} K_j\] - 这个更新需要累加来自不同 K/V 块的贡献 - 每个列块都对同一个 \(dQ\) 行有贡献 - 需要通过 HBM 使用原子操作来协调更新 - 就像学生们一起做同一道题的不同部分 - 结果必须合并
关键区别: 前向传播有独立的行计算,但反向传播需要累加来自不同块的贡献,需要通过 HBM 和原子加法进行同步。
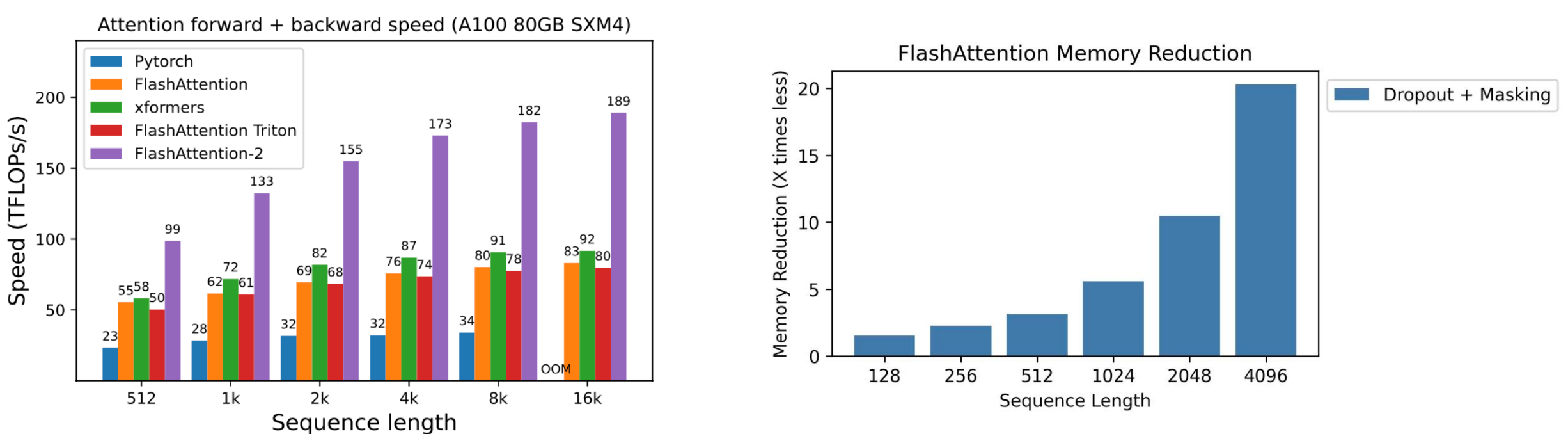
性能表现
FlashAttention 实现了: - 相比 PyTorch 和其他基线快 2-4 倍 - 内存减少 10-20 倍 - 内存随序列长度线性增长(vs 二次方)
生成式 LLM 推理:自回归解码
两个阶段
1. 预填充阶段(第0次迭代)
- 一次性处理所有输入token
- 计算整个提示的注意力
- 示例:
[Accelerating LLM requires machine]→ 输出:learning
2. 解码阶段(第1+次迭代)
- 处理从前一次迭代生成的单个 token
- 使用所有先前 token 的注意力键和值
- 示例迭代:
- 迭代1:
learning→systems - 迭代2:
systems→optimizations - 迭代3:
optimizations→[EOS]
- 迭代1:
键值缓存(KV Cache)
目的:保存注意力键和值用于后续迭代,避免重新计算
内存:随序列长度线性增长
解码中的注意力计算: - 查询:单个新 token - 键/值:所有先前的 token(来自缓存)
FlashAttention 用于 LLM 推理
适用性
预填充阶段: ✅ 是 - 可以使用不同的线程块/warp 计算不同的查询
解码阶段: ❌ 否 - 解码阶段只有一个查询 - FlashAttention 顺序处理 K/V - 对于长上下文的请求效率低(很多键/值)

Flash-Decoding:解码的并行注意力
核心洞察
注意力是可结合的和可交换的 - 可以分割并归约
方法
- 将键/值分割成小块
- 使用 FlashAttention 并行计算这些分割的注意力
- 对所有分割的结果进行归约
性能表现
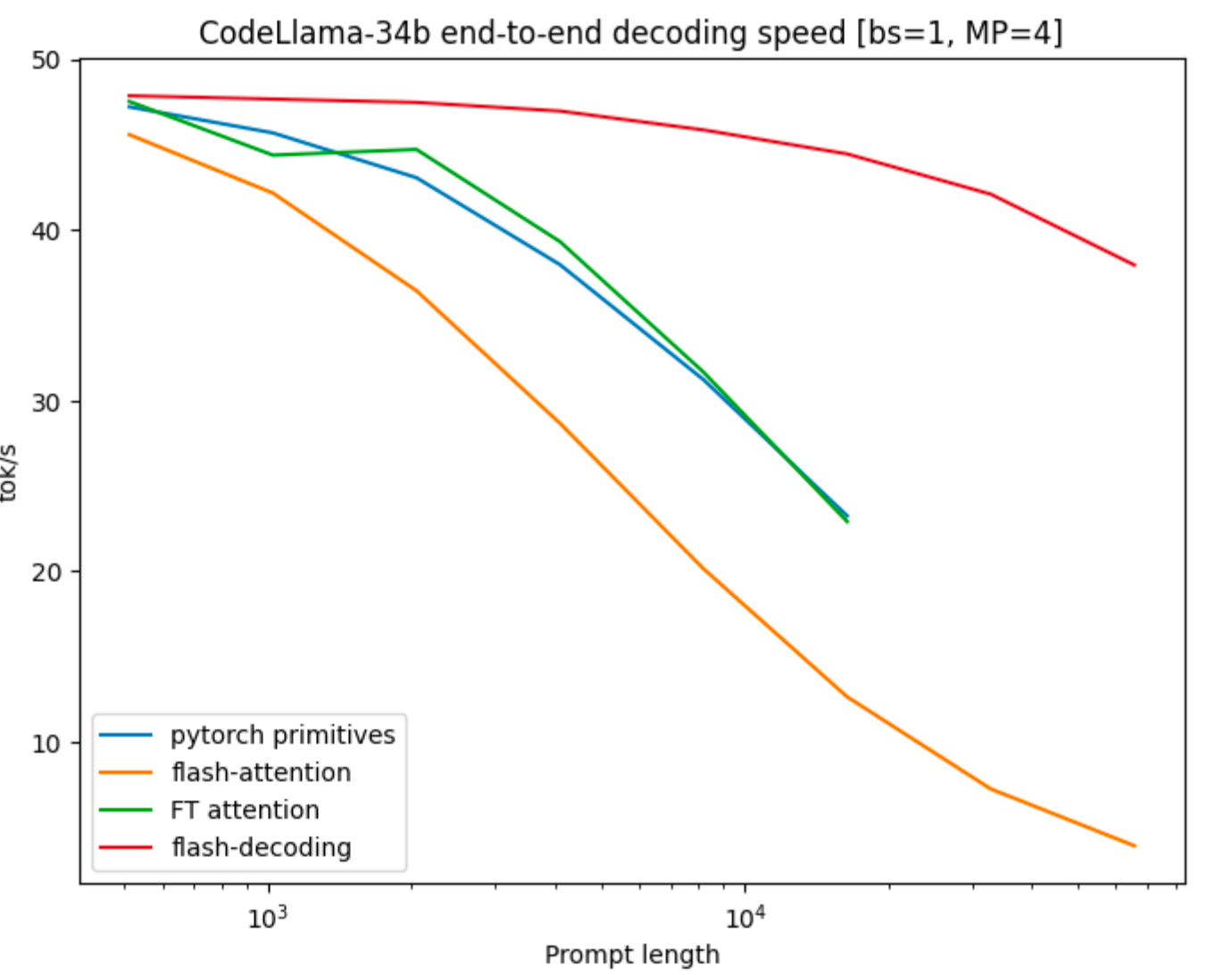
Flash-Decoding 对于长上下文比先前工作快达 8 倍
示例(CodeLlama-34b,bs=1,MP=4): - 序列长度 1K:~47 tok/s(与其他方法相似) - 序列长度 16K:~38 tok/s vs ~5 tok/s(FlashAttention) - 即使对于非常长的序列也能保持高吞吐量
总结
- 注意力机制是 Transformer 模型的核心,具有 \(O(N^2)\) 复杂度
- 多头注意力提供并行性和表示多样性
- FlashAttention 使用分块和重计算来实现 IO 效率:
- 快 2-4 倍,内存减少 10-20 倍
- 支持更长的序列长度
- LLM 推理有两个具有不同计算模式的阶段:
- 预填充:多个查询(批处理)
- 解码:单个查询(顺序)
- Flash-Decoding
跨键/值并行化以实现高效的长上下文解码:
- 对于长序列快达 8 倍
- 对于需要大上下文窗口的应用至关重要
参考文献
- Vaswani et al., “Attention is All You Need”, NeurIPS 2017
- Dao et al., “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”, NeurIPS 2022
- Dao, “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning”, 2023
- Shazeer, “Flash-Decoding for Long-Context Inference”, 2023


