15645 Database systems: Hash Tables
Lec7 哈希表
背景
数据库管理系统中的数据结构:内部元数据、核心数据存储、临时数据结构、表索引
设计决策:数据组织(我们如何在内存/页面中布局数据以及存储哪些信息以支持高效访问)和 并发性(使多个线程能够同时访问数据结构)
哈希表:无序关联数组,将键映射到值;空间复杂度为 O(n),时间复杂度平均为 O(1),最坏情况为 O(n)。
不切实际的假设:元素数量是事先已知且固定的;每个键是唯一的;完美的哈希函数保证没有冲突。
哈希函数
我们关心如何将一个大的键空间映射到一个较小的域,主要目标是速度与冲突率之间的权衡。
示例:CRC-64 (1975)、MurmurHash (2008)、Google CityHash (2011)、Facebook XXHash (2012,最先进)、Google FarmHash (2014)、RapidHash (2019)
静态哈希方案
线性探测哈希
单个固定长度槽的巨大表。
通过线性搜索表中下一个空槽来解决冲突。
- 要确定元素是否存在,哈希到表中的一个位置并进行扫描。
- 在表中存储键以知道何时停止扫描。
- 插入和删除是查找的推广。
表的负载因子决定何时变得过满并应进行调整大小。
负载因子 = 活跃键 / 槽数量;分配一个新表,大小是原来的两倍,并重新哈希条目。
键值条目:
- 固定长度:内联存储或可选择与键一起存储键的哈希以加快比较。
- 可变长度:将kv数据插入单独的私有临时表,并存储哈希 + RecordId。
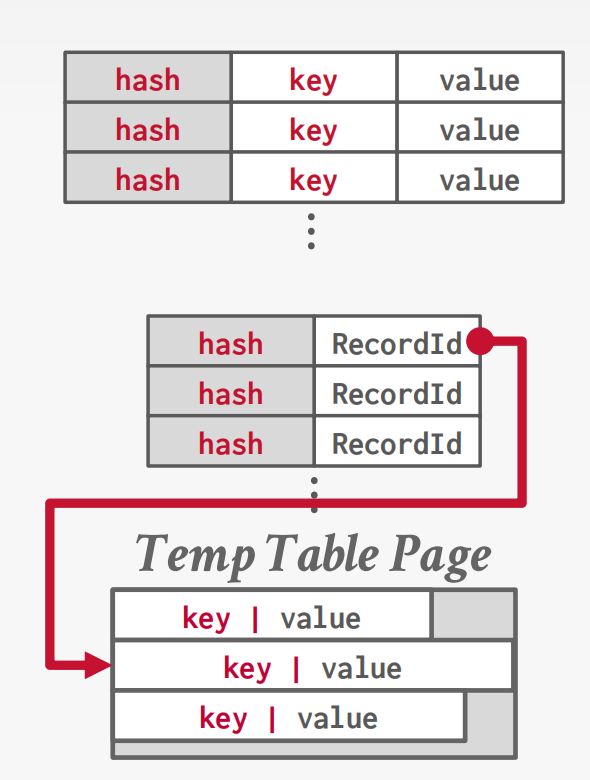
删除策略:
- 移动:删除后,向前扫描并重新哈希每个键,直到遇到空槽以填补空缺。代价高昂;没有DBMS使用此方法。
- 墓碑:将槽标记为已删除。查找跳过它;插入可以重用它。需要定期垃圾回收。这是大家都在使用的方法。
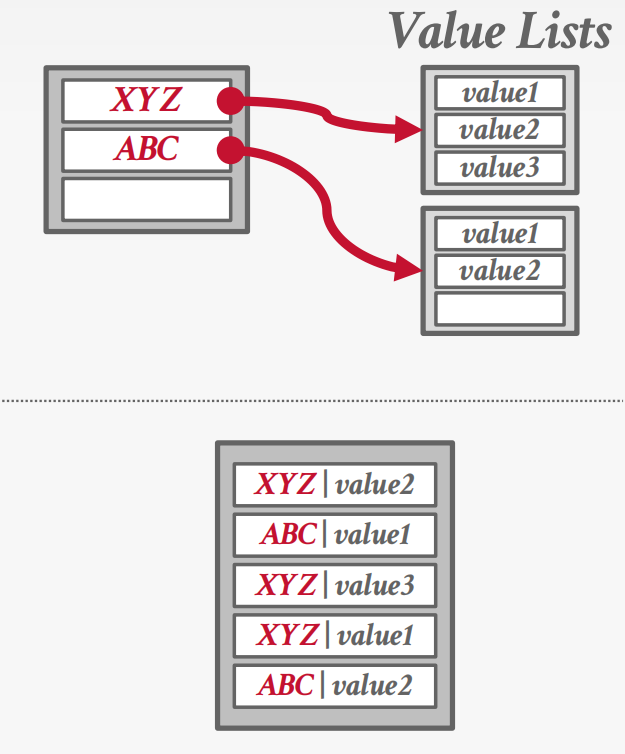
非唯一键:
- 分离链表
- 冗余键
优化:
- 按键类型/大小专业化:使用不同的哈希表实现,针对不同的键大小(例如,短字符串与长字符串)进行优化,以实现更快的比较。
- 单独存储元数据:单独存储一个打包的位图以跟踪槽状态(空/墓碑/占用)。扫描位图比触碰每个满槽更具缓存友好性。
- 表 + 槽版本控制:每个槽在写入时记录表版本。要清除整个表,只需递增全局版本——任何具有过时版本的槽都视为空。O(1) 批量失效。
布谷鸟哈希
使用多个哈希函数在哈希表中查找多个位置以插入记录。
- 在插入时,检查多个位置并选择一个空的。
- 如果没有可用位置,驱逐其中一个元素,然后重新哈希以找到新位置。
动态哈希方案
之前的哈希表要求DBMS知道它想要存储的元素数量。否则,如果需要增大/缩小大小,它必须重建表。
动态哈希表根据需要逐步调整大小。
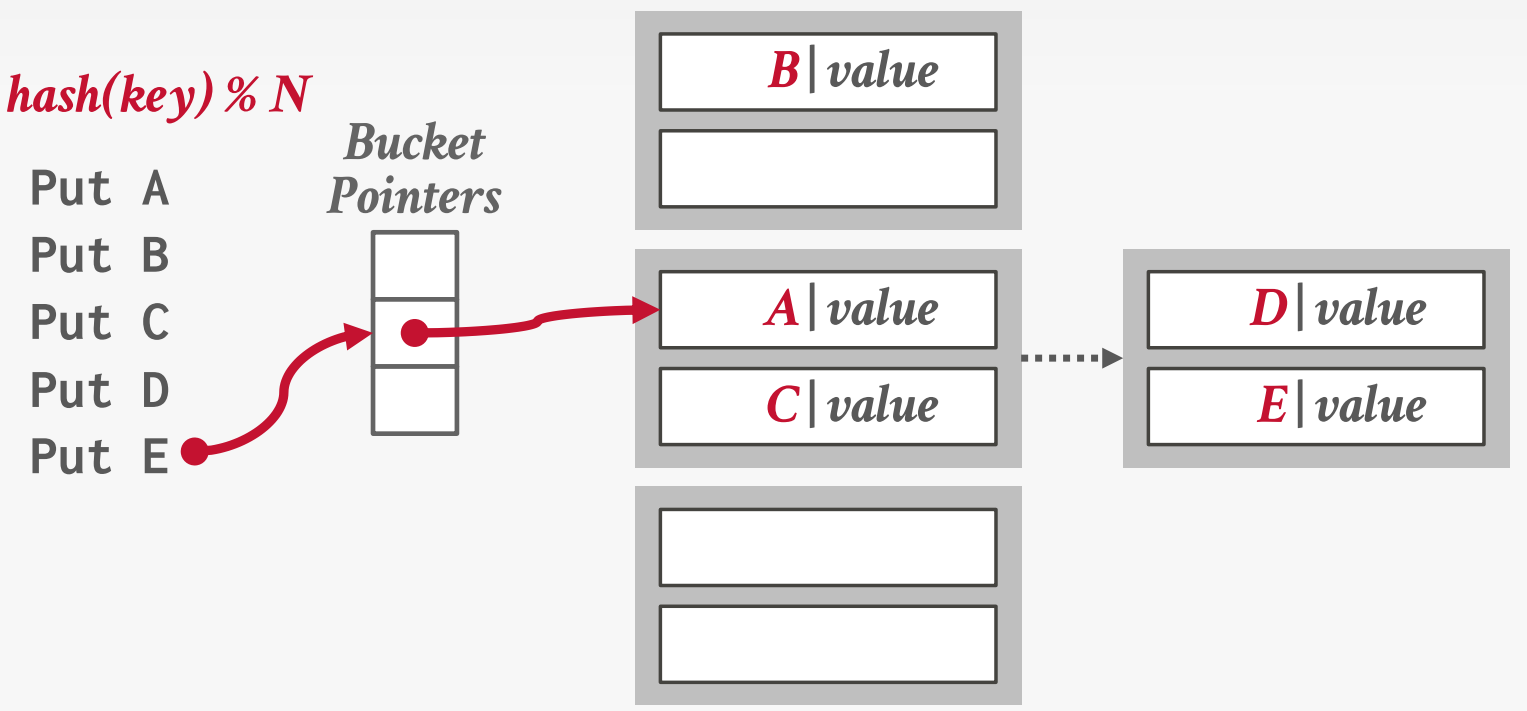
链式哈希
为哈希表中的每个槽维护一个桶的链表。
通过将所有具有相同哈希键的元素放入同一个桶来解决冲突。
我们可以添加布隆过滤器来帮助过滤不存在的键。
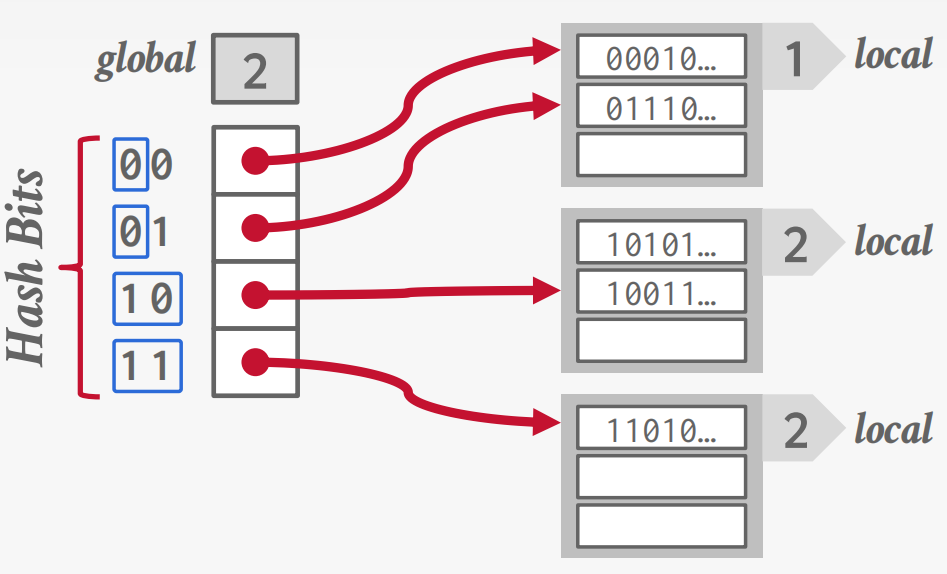
可扩展哈希
链式哈希方法,逐步拆分桶,而不是让链表无限增长。
多个槽位置可以指向同一个桶链。
在拆分时重新排列桶条目,并增加要检查的位数。
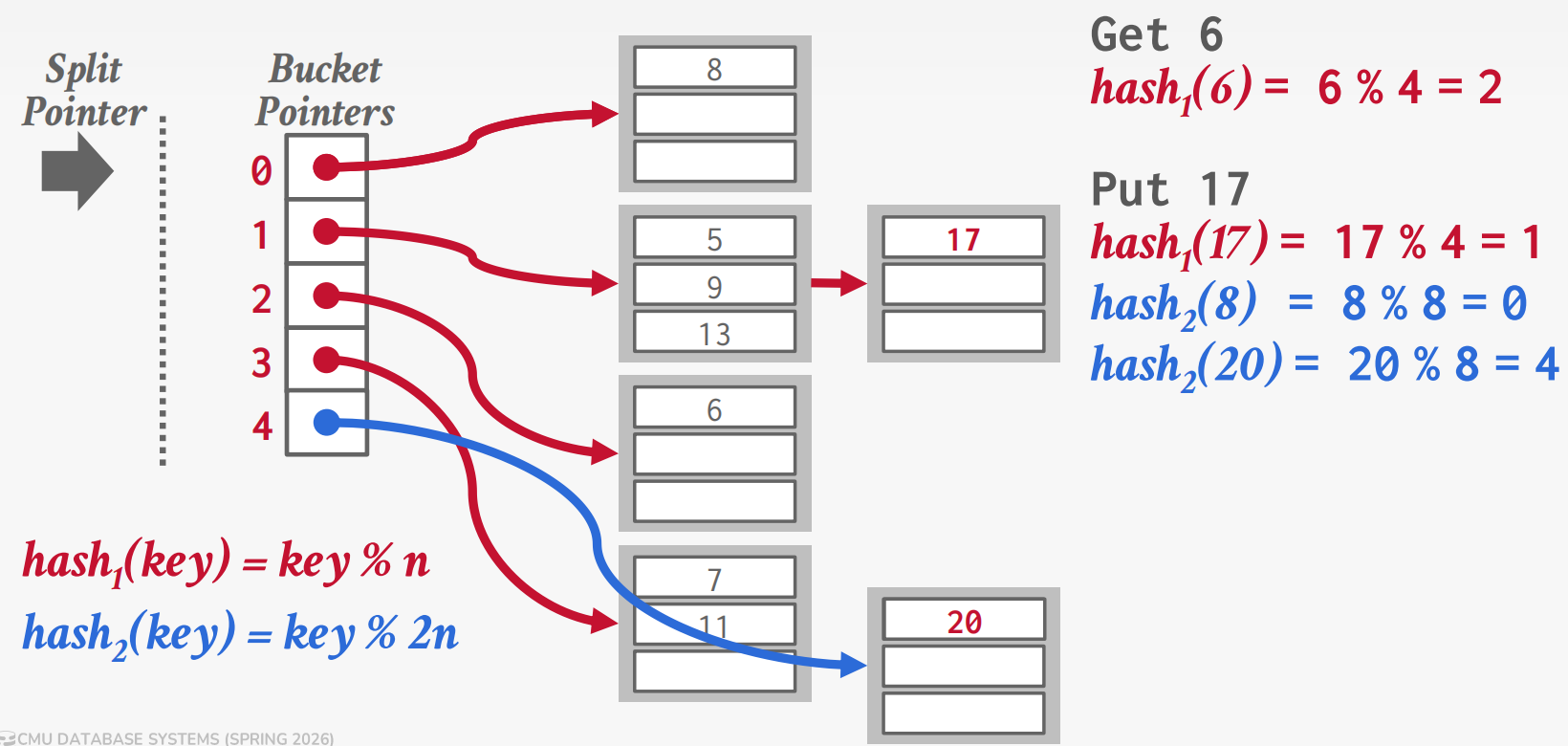
线性哈希
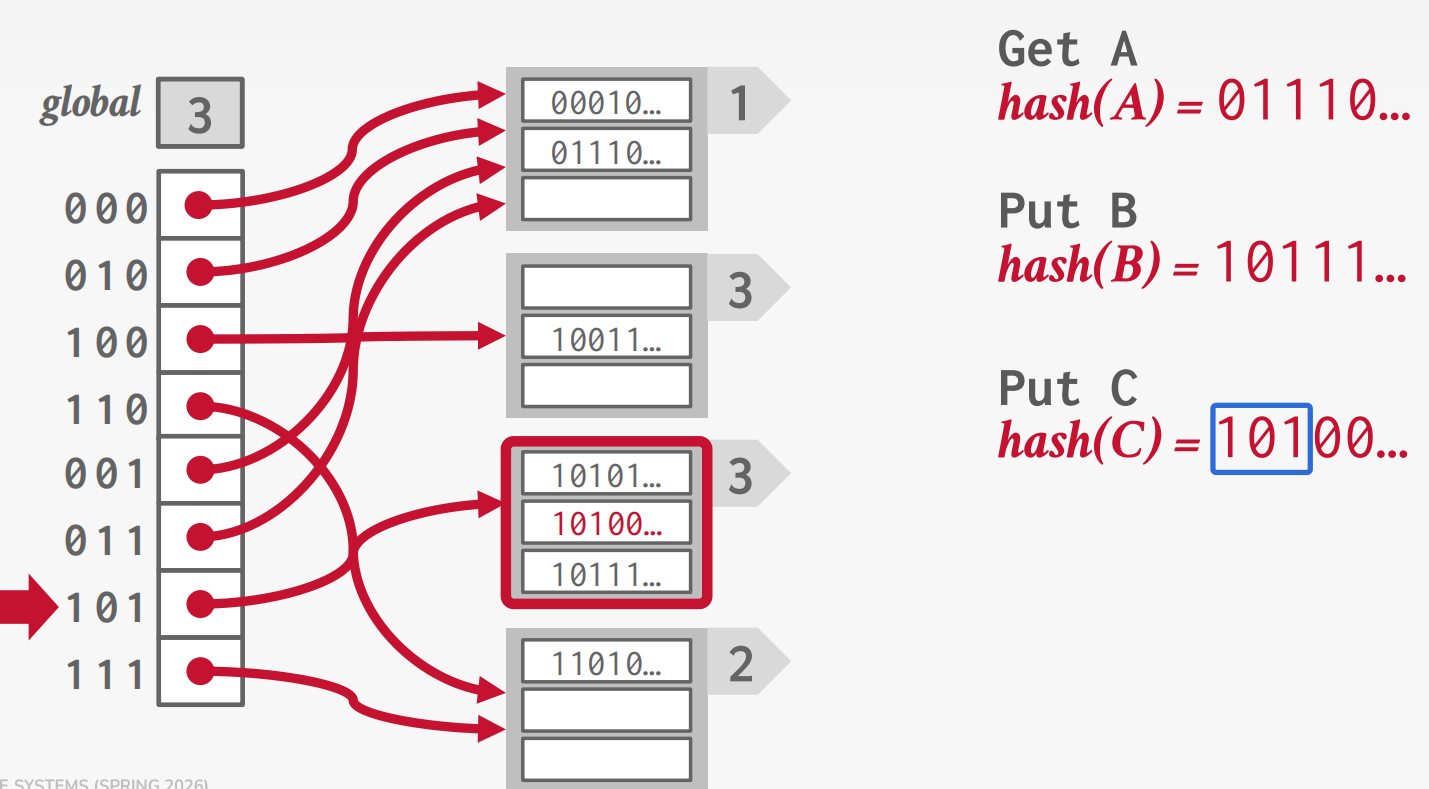
线性哈希:维护一个顺序推进的拆分指针。当任何桶溢出时,在拆分指针处拆分桶(而不是溢出的那个),使用
hash2 = key % 2n 将其条目重新分配到旧桶和新桶之间。
查找规则:计算 hash1(key)。如果结果
< 拆分指针,则该桶已被拆分,因此使用
hash2(key)。如果结果 ≥ 拆分指针,则 hash1
是正确的。
轮次完成:当拆分指针到达末尾时,所有桶都已拆分。丢弃
hash1,将 hash2 提升为新的
hash1,创建 hash2 = key % 4n,将指针重置为
0。任何时候最多只有两个哈希函数共存。