
15645 Database systems: Storage
Lec3 数据库存储:文件与页面
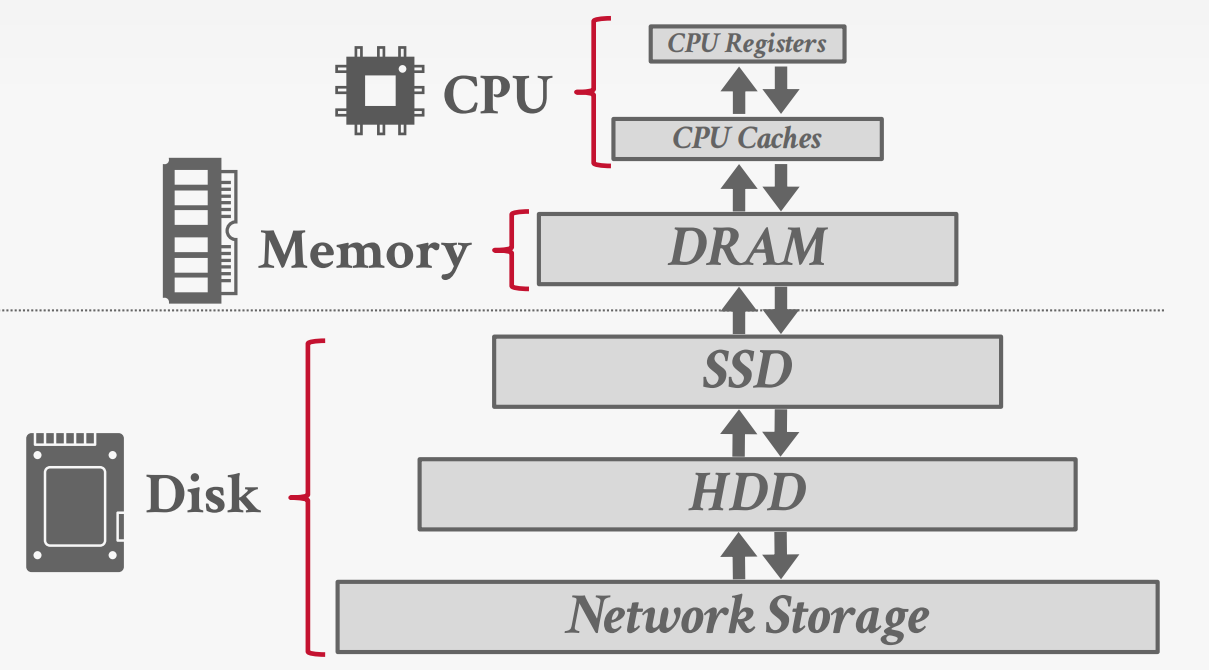
存储层次
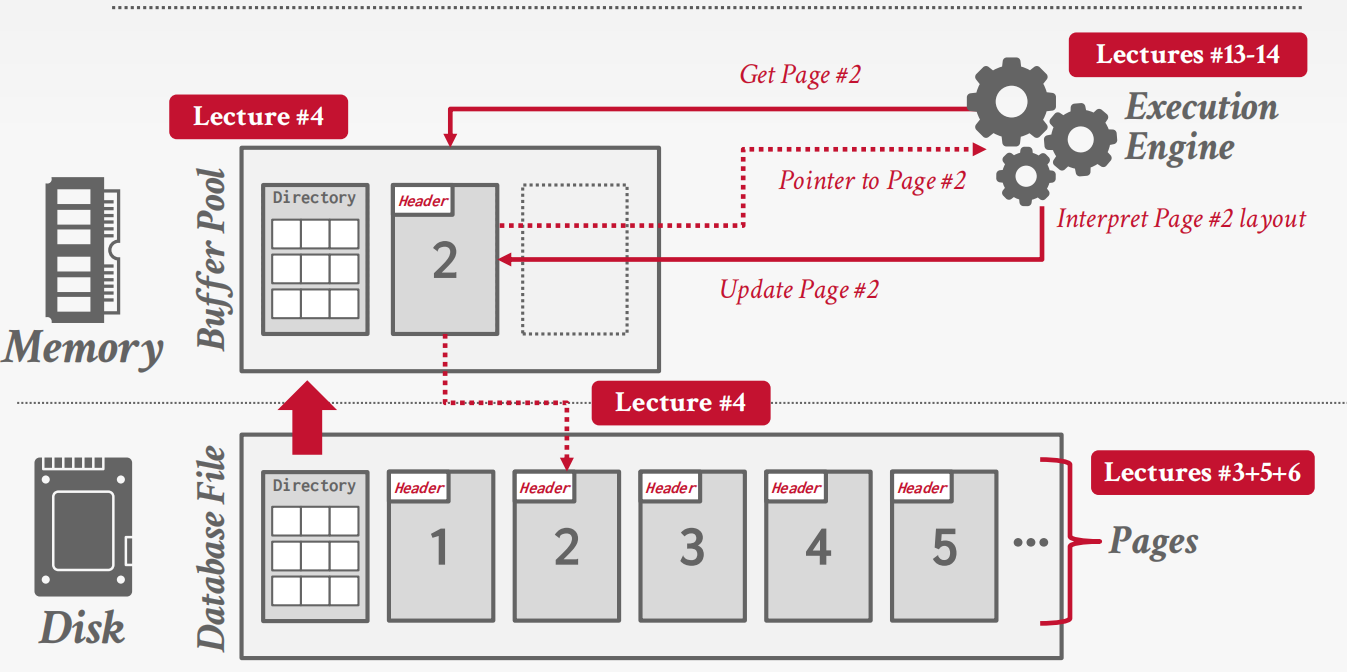
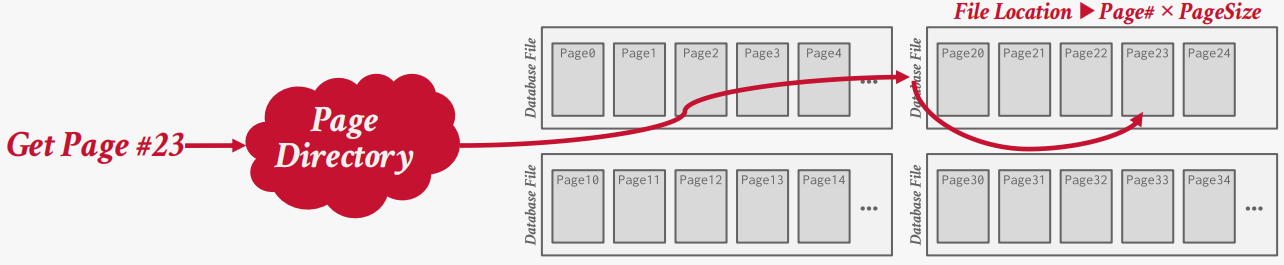
堆文件
堆文件是一个无序的页面集合,元组以随机顺序存储。
需要额外的元数据来跟踪文件的位置和空闲空间的可用性。
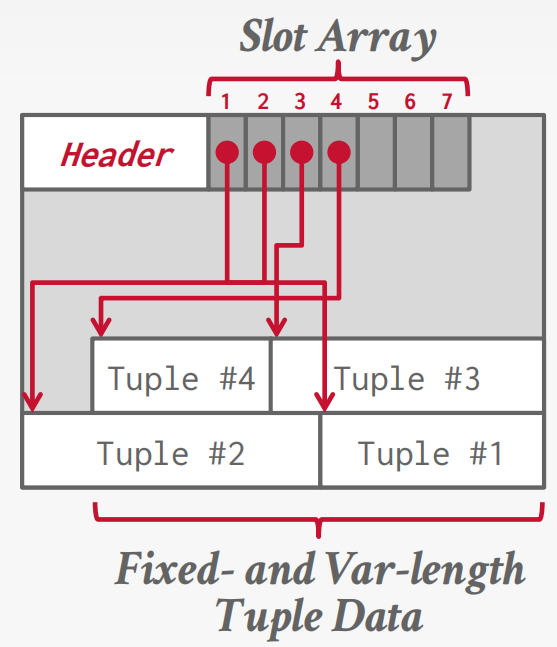
页面布局
页面头部
每个页面包含关于页面内容的元数据头部。
页面大小;校验和;DBMS版本;事务可见性;压缩/编码元数据;模式信息;数据摘要/草图
方法:
方法 #1:元组导向存储
方法 #2:日志结构存储
方法 #3:索引组织存储
元组导向存储
最常见的布局方案称为插槽页面。
记录ID
DBMS为每个逻辑元组分配一个唯一的记录标识符,表示其在数据库中的物理位置。
→ 示例:文件ID,页面ID,插槽#
元组布局
元组本质上是一个字节序列,前面带有一个包含其元数据的头部。
元组头部
每个元组前面都有一个包含其元数据的头部。
→ 可见性信息(并发控制)
→ NULL值的位图。
我们不需要存储关于模式的元数据。
元组数据
属性通常按照创建表时指定的顺序存储。然而,以不同的方式布局可能更高效。
Lec4 缓冲池内存管理
本讲将解决DBMS如何管理其内存以及如何在磁盘之间来回移动数据。
磁盘导向DBMS模型
现代DBMS是磁盘导向的:磁盘是真相的来源,而内存用于性能优化。
数据移动受两个维度的控制:
- 空间控制:页面在磁盘上的放置位置,旨在保持频繁共同访问的页面物理上接近。
- 时间控制:页面何时被引入内存,以及何时修改的页面被写回磁盘。
缓冲池是实现时间控制的核心机制。
缓冲池元数据
为了管理缓存页面,DBMS在内存中维护元数据:
页面表
- 映射
page_id → frame_id - 通常实现为哈希表
- 由锁保护以确保线程安全
- 不持久化到磁盘
每页元数据
每个缓存页面跟踪:
- 脏标志:页面是否已被修改
- 固定(引用)计数:活跃用户的数量;固定页面不能被驱逐
- 访问历史:由替换策略使用
锁与锁存器
缓冲池使用锁存器,而不是锁。
- 锁保护逻辑数据库内容,并在事务持续期间持有
- 锁存器保护内部DBMS数据结构,并短暂持有
锁存器不需要回滚支持,更接近于互斥锁。
页面目录与页面表
这两个结构常常被混淆:
- 页面目录:将页面映射到磁盘位置,持久化到磁盘
- 页面表:将页面映射到内存帧,仅存在于内存中
目录在重启后支持恢复;页面表则不支持。
缓冲替换策略
当缓冲池满时,必须加载新页面,DBMS必须驱逐现有页面。替换策略旨在平衡正确性、准确性和低开销。
LRU与时钟
- 驱逐最近最少访问的页面
- 时钟使用引用位近似LRU
两者都容易受到顺序洪水的影响,即大规模扫描驱逐即将被重用的有用页面。
LRU-K
LRU-K考虑第K次最近访问,而不仅仅是最后一次。
- 访问次数少于K的页面被视为低价值
- 有助于区分一次性扫描和真正热门的页面
- 需要更多元数据和更高的实现复杂性
ARC
自适应替换缓存动态平衡新近性和频率。
- 为最近和频繁的页面维护单独的列表
- 使用幽灵列表从最近的驱逐中学习
- 根据工作负载自动调整行为
ARC更复杂,但对混合工作负载适应良好。
Lec5 日志结构存储
传统的页面导向存储假设数据可以就地覆盖。然而,这一假设在现代存储系统中失效,因为随机写入成本高昂或根本不支持。
日志结构存储采取不同的方法:DBMS将所有更改记录为日志记录,而不是修改页面内的元组。
日志记录与内存更新
对元组的每次修改都表示为日志记录:
- PUT(key, value) 插入或更新一个元组
- DELETE(key) 将元组标记为已删除
DBMS不会立即将这些记录写入磁盘。相反,更新首先应用于一个称为MemTable的内存数据结构。
MemTable保持键的排序,并始终反映数据库的最新状态。
将MemTable刷新到磁盘
当MemTable变满时,DBMS将其内容刷新到磁盘作为排序字符串表(SSTable)。
SSTable的关键属性:
- 作为新文件存储在磁盘上
- 包含按键排序的记录(低→高)
- 一旦写入即不可变
这个刷新后的SSTable被放入级别0。
在此阶段,可能存在多个SSTable,按最新到最旧排序,并且它们的键范围可能重叠。
多级组织
随着生成更多SSTable,DBMS将它们组织成多个级别:
- 级别0
- 直接从内存刷新到的SSTable
- 键范围可能重叠
- 按创建时间排序(最新→最旧)
- 较低级别(级别1,级别2,…)
- SSTable具有不重叠的键范围
- 数据逐渐变得更旧且更紧凑
这种层次结构允许DBMS在顶部快速吸收写入,同时在后台逐渐组织数据。
读取数据(GET)
为了处理GET(key)请求,DBMS搜索键的最新版本:
- MemTable
- 首先检查,因为它包含最新的更新
- SummaryTable
- 存储元数据,例如:
- 每个SSTable的最小/最大键
- 每个级别的键过滤器
- 用于消除无法包含该键的SSTable
- 存储元数据,例如:
- 磁盘级别
- 从最新到最旧的SSTable搜索级别0
- 使用键范围约束搜索较低级别
一旦找到键,搜索就停止。

日志结构压缩
随着时间的推移,SSTable会累积过时的版本和已删除的条目。为了回收空间并提高读取性能,DBMS定期执行压缩。
压缩:
- 使用排序合并算法合并多个SSTable
- 仅保留每个键的最新版本
- 丢弃过时的条目和墓碑
这个过程在较低级别生成新的SSTable,同时删除旧的。

压缩策略
PPT介绍了两种压缩策略:
- 分级压缩
- 将数据组织成多个级别
- 同一级别内的SSTable不重叠(级别0除外)
- 针对读取密集型工作负载进行了优化

- 通用压缩
- 维护单个逻辑级别
- 允许重叠的键范围
- 针对写入密集型工作负载进行了优化

Lec6 数据库存储 + 列存储 + 数据压缩
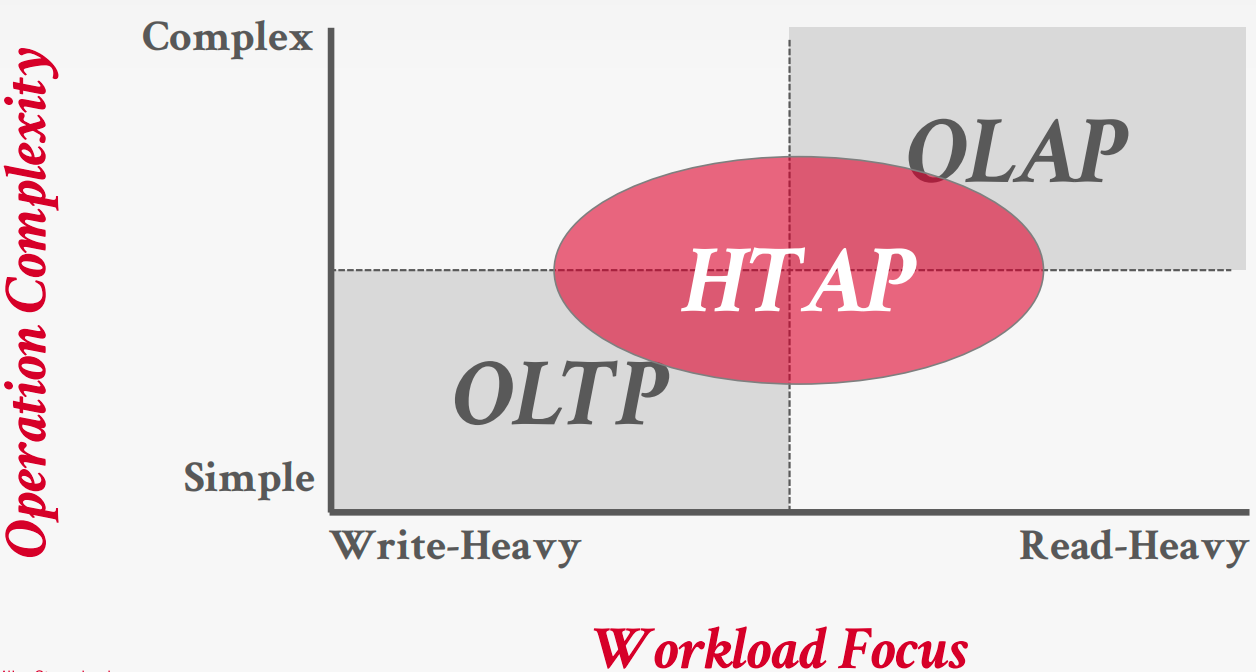
数据库工作负载
- 在线事务处理(OLTP):快速操作,仅读取/更新少量数据
- 在线分析处理(OLAP):复杂查询,读取大量数据以计算聚合
- 混合事务 + 分析处理:OLTP + OLAP
存储模型
DBMS的存储模型指定其在磁盘和内存中如何物理组织元组。
根据目标工作负载可能具有不同的性能特征,并影响DBMS其余部分的设计选择
- N元存储模型(NSM)
- 分解存储模型(DSM)
- 混合存储模型(PAX)
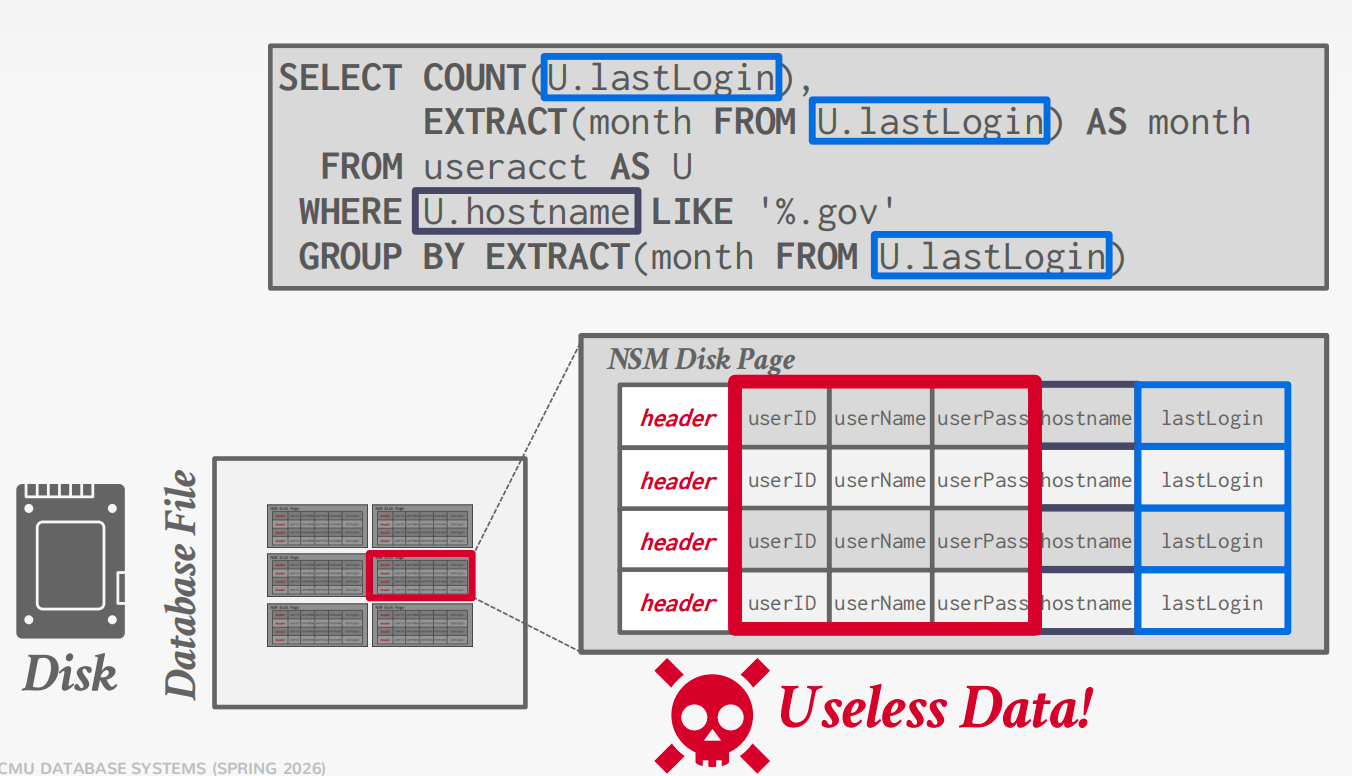
NSM
磁盘导向的NSM系统将元组的固定长度和可变长度属性连续存储在单个插槽页面中。
元组的记录ID(页面#,插槽#)是DBMS唯一标识物理元组的方式
优点
- 快速插入、更新和删除。
- 适合需要整个元组的查询(OLTP)。
- 可以使用面向索引的物理存储进行聚类。
缺点
不适合扫描表的大部分和/或属性的子集。
访问模式中的内存局部性差。
由于单个页面内存在多个值域,不适合压缩。
DSM
为所有元组连续存储单个属性的数据块。也称为“列存储”
理想用于OLAP工作负载,其中只读查询对表的属性子集执行大规模扫描。
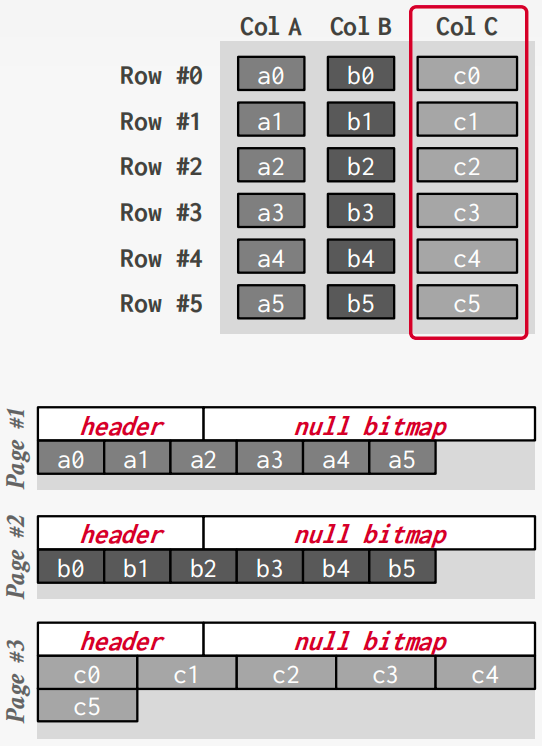
元组识别
- 固定长度偏移
- 嵌入元组ID
优点
减少每个查询浪费的I/O量,因为DBMS仅读取所需的数据。
由于局部性增加和缓存数据重用,查询处理速度更快(第14讲)。
更好的数据压缩,因为来自同一域的数据物理上聚集在一起。
缺点
- 由于元组拆分/拼接/重组,点查询、插入、更新和删除速度较慢。
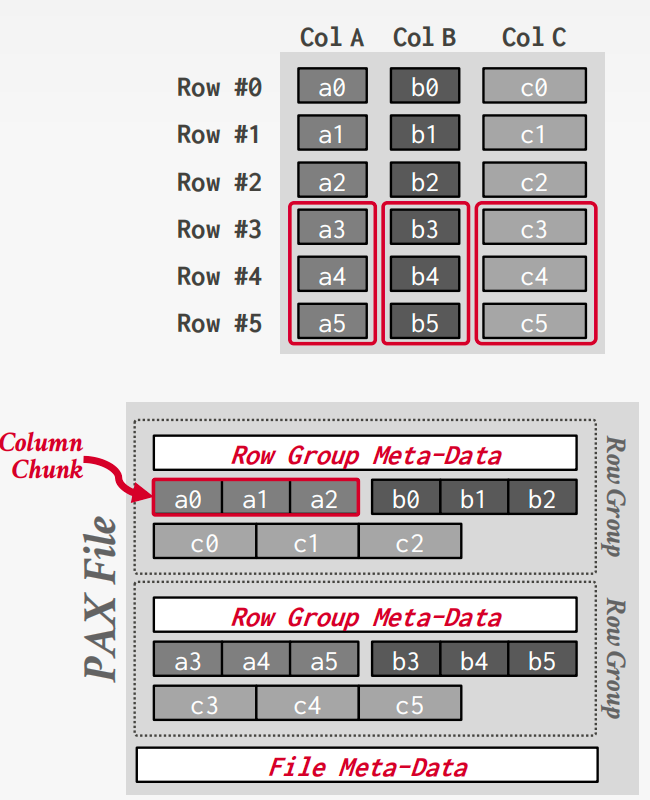
PAX
属性跨分区(PAX)是一种混合存储模型,在数据库页面内垂直分区属性。
将数据水平分区为行组。然后将它们的属性垂直分区为列块。
数据库压缩
目标:
#1: 必须生成固定长度的值。唯一的例外是存储在单独池中的可变长度数据。
#2: 在查询执行期间尽可能推迟解压缩。这也称为延迟物化。
#3: 必须是无损方案。人们(通常)不喜欢丢失数据。任何有损压缩必须由应用程序执行
压缩粒度
- 块级:压缩同一表的元组块。
- 元组级:压缩整个元组的内容(仅限NSM)。
- 属性级:压缩一个元组内的单个属性(溢出)。可以针对同一元组的多个属性。
- 列级:压缩为多个元组存储的一个或多个属性的多个值(仅限DSM)。
天真压缩
使用通用算法压缩数据。压缩范围基于提供的输入。

理想情况下,DBMS可以在< u>不先解压缩的情况下对压缩数据进行操作。
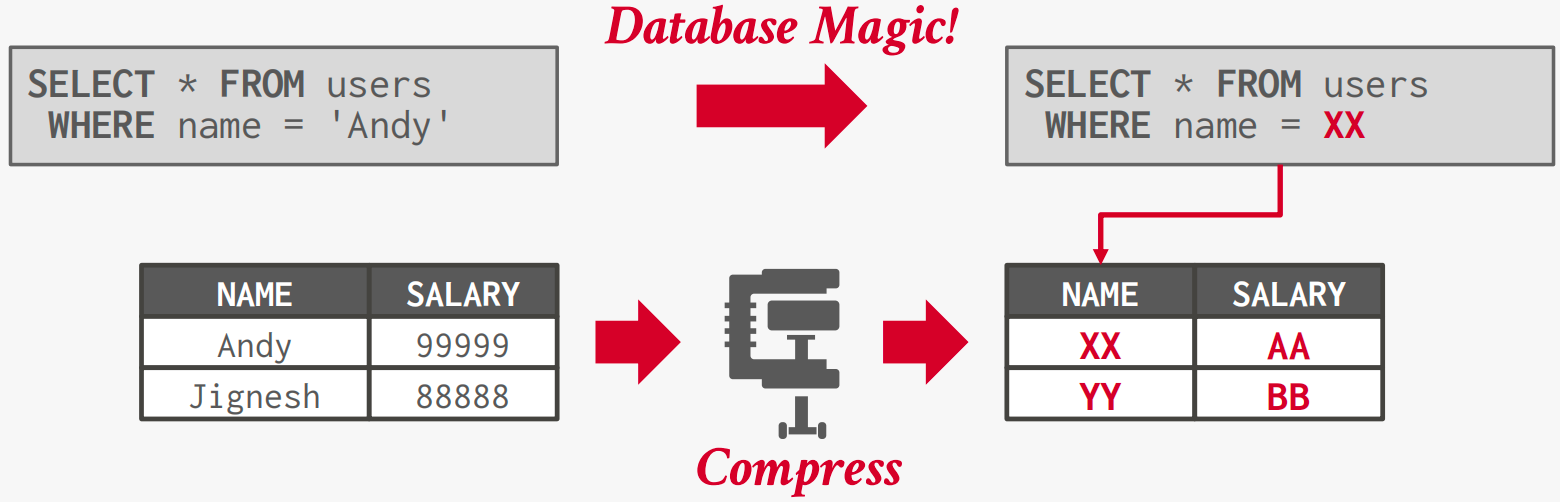
列式压缩
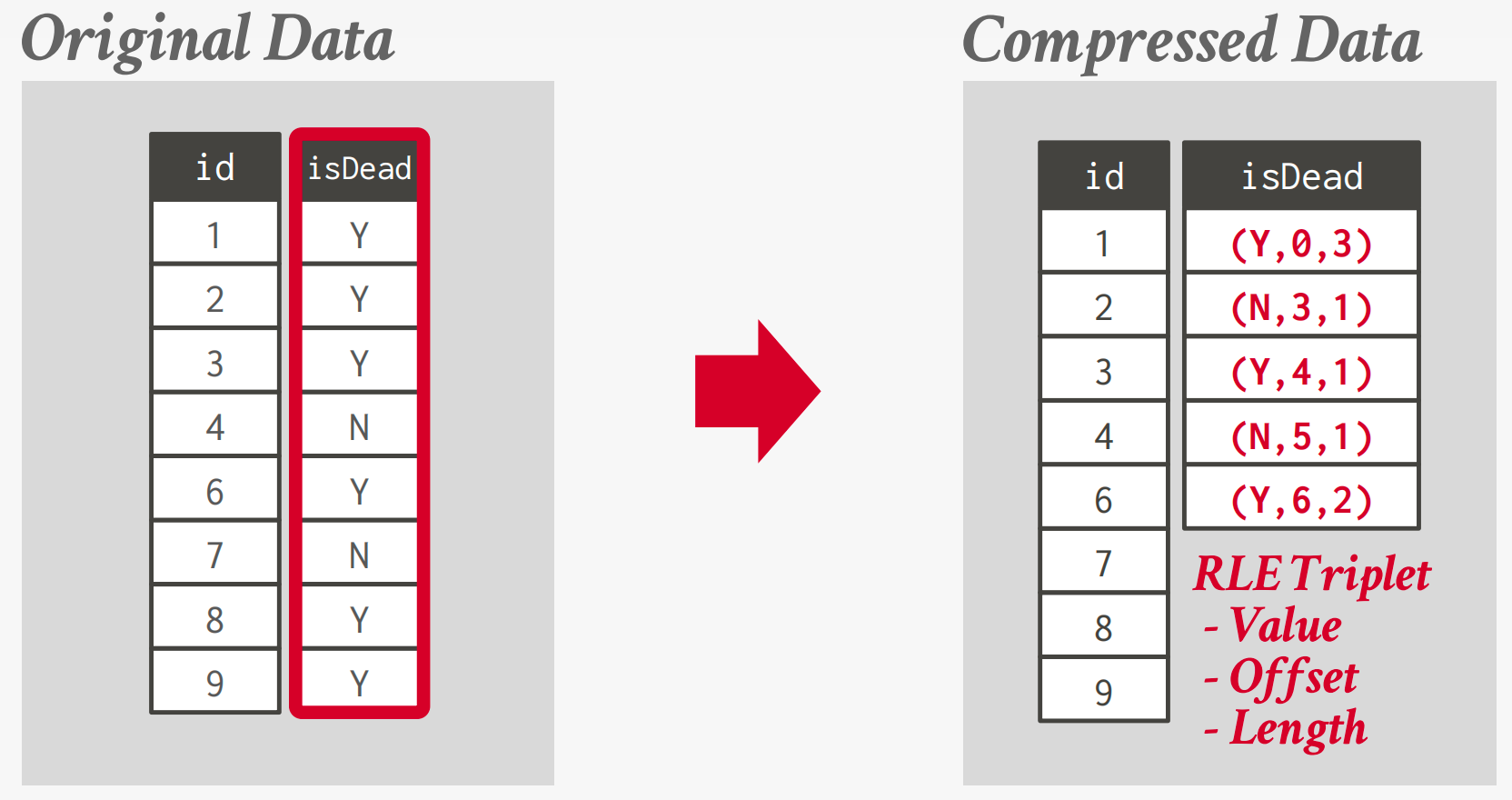
游程编码
将单列中相同值的运行压缩为三元组:
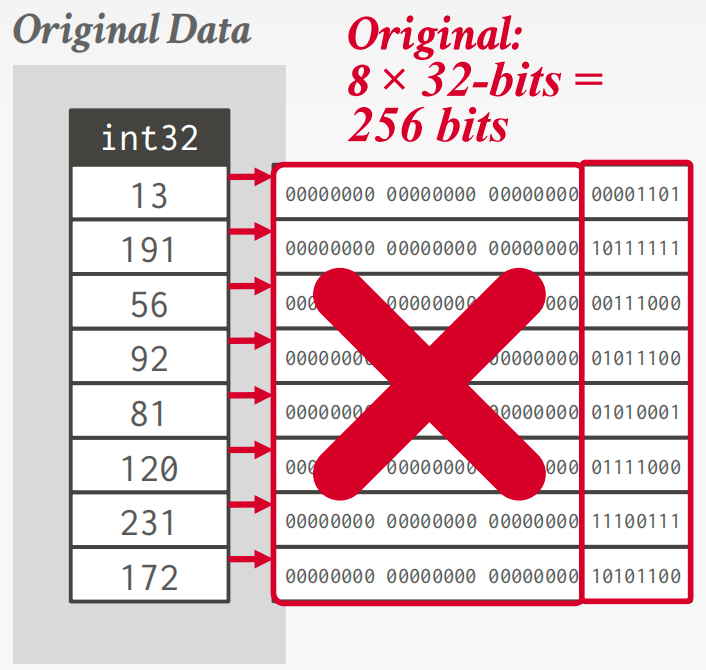
位打包编码
如果整数属性的值小于其给定数据类型大小的范围,则减少表示每个值所需的位数。
补丁/大多数编码:一种位打包的变体,当属性的值“主要”小于最大大小时,用较小的数据类型存储它们。

位图编码
为每个属性的唯一值存储一个单独的位图,其中向量中的偏移量对应于一个元组。
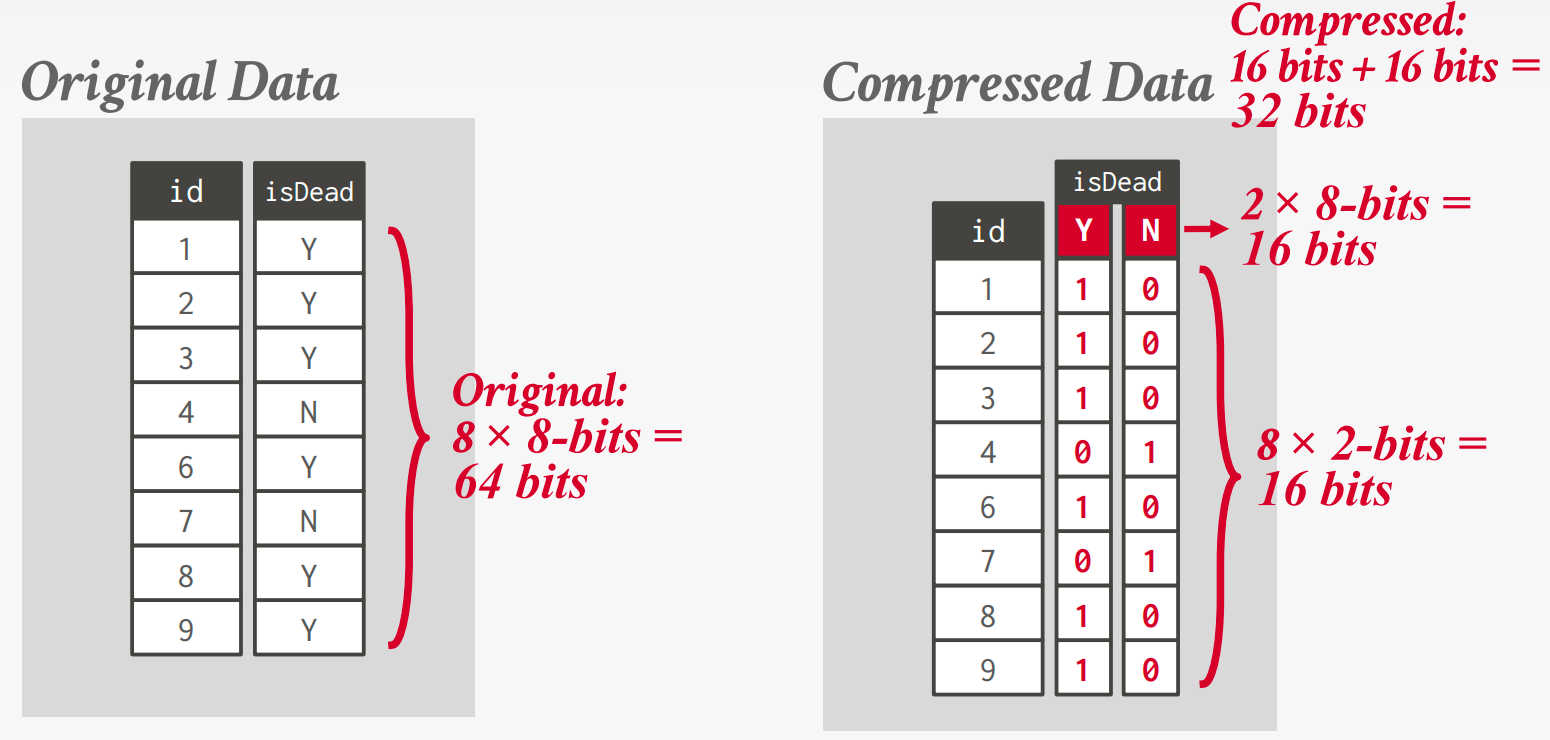
但这种方法存在一些缺陷。
假设我们有1000万个元组。美国有43,000个邮政编码。
→ 10000000 × 32位 = 40 MB(原始)
→ 10000000 × 43000 = 53.75 GB(使用位图)
每次应用程序插入新元组时,DBMS必须扩展43,000个不同的位图。
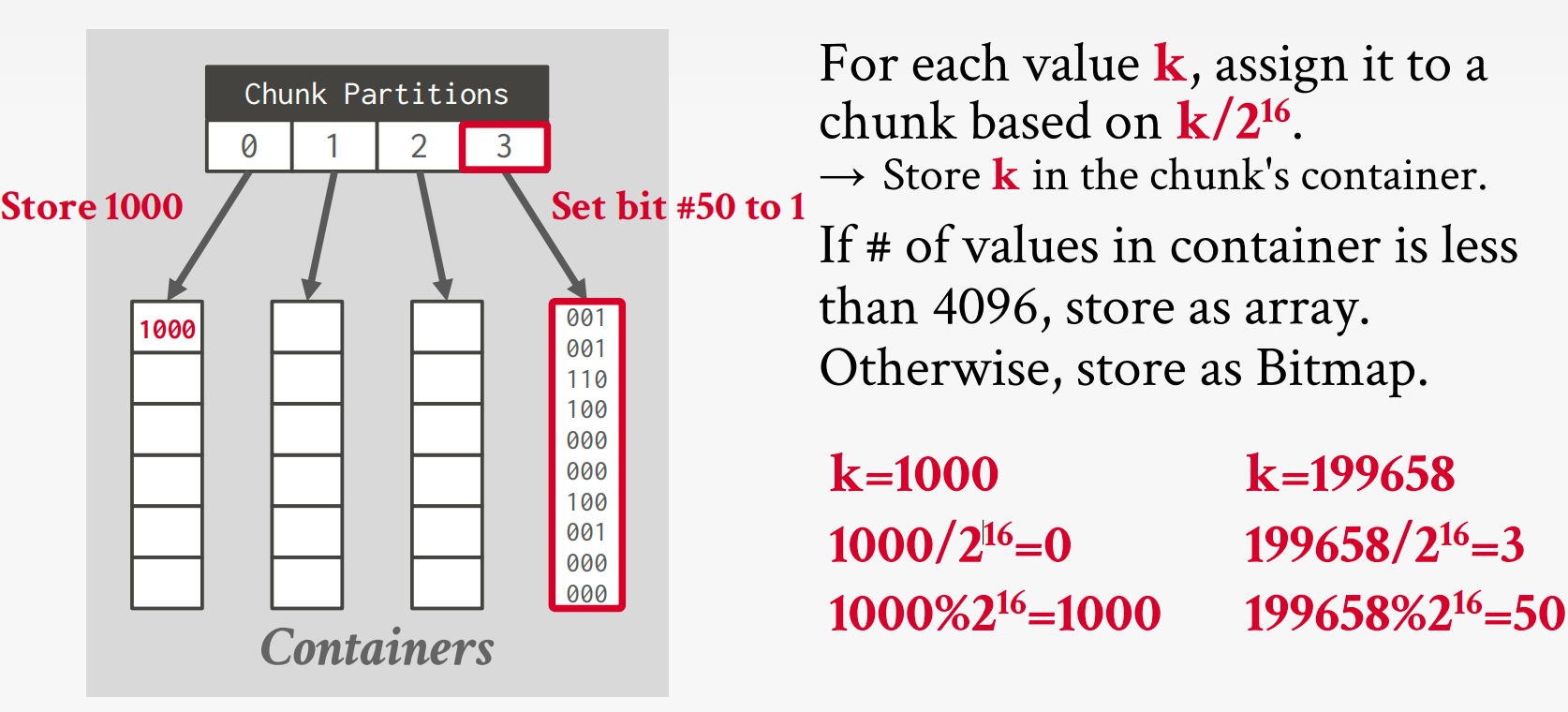
Roaring位图
位图索引根据位的局部密度切换使用哪种数据结构来处理一系列值
- 密集块使用未压缩的位图存储。(可以进一步使用RLE压缩)
- 稀疏块使用16位整数的位打包数组。
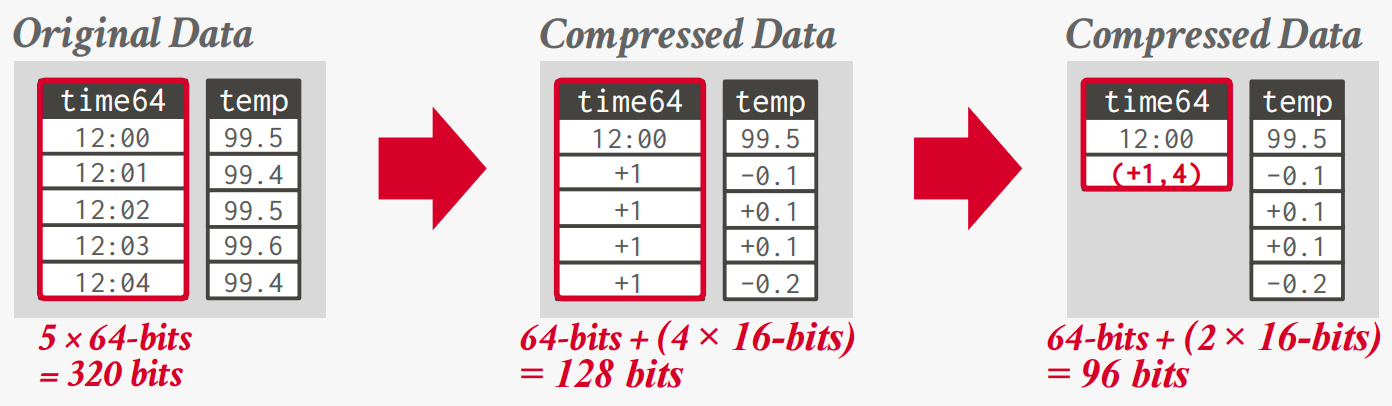
增量/参考帧编码
记录同一列中相邻值之间的差异。
结合RLE可以获得更好的压缩比。
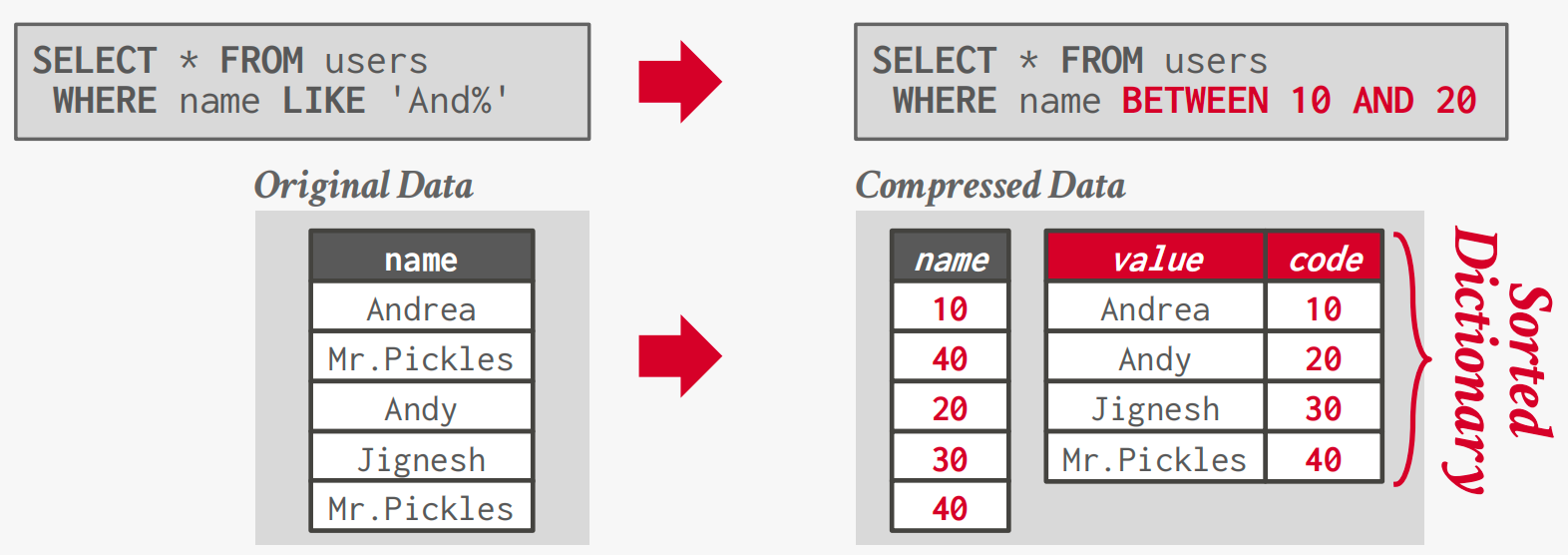
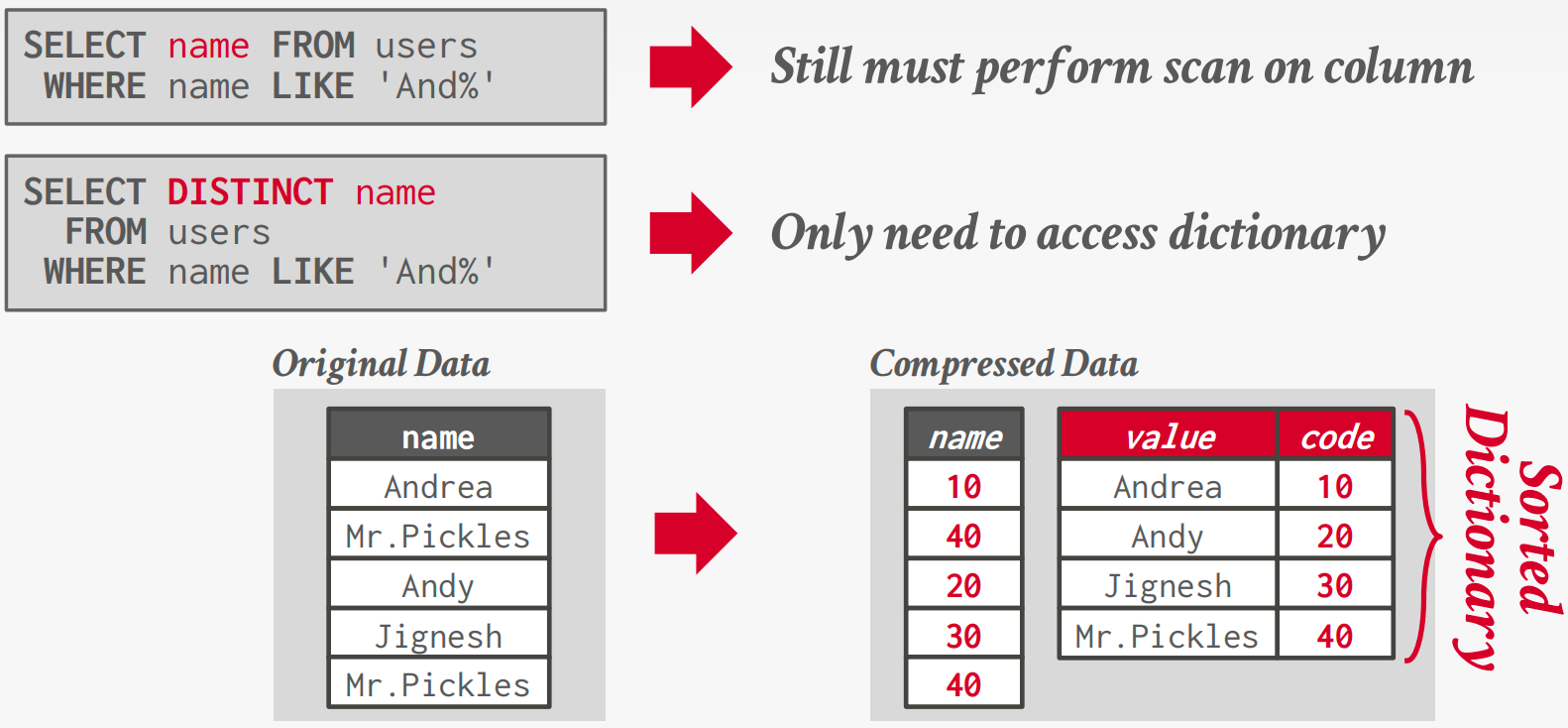
字典编码
用较小的固定长度代码替换频繁的值,然后维护从代码到原始值的映射(字典)。(通常,每个属性值一个代码。)
分叉环境
分叉环境将OLTP和OLAP系统分开,通过ETL或ELT管道在它们之间移动数据。
混合存储模型
使用分别针对NSM或DSM数据库优化的执行引擎。
- 在NSM中存储新数据以实现快速OLTP。
- 将数据迁移到DSM以实现更高效的OLAP。

破碎镜像
示例:Oracle,IBM DB2 Blu,Microsoft SQL Server
DBMS自动维护数据库的第二份副本,采用DSM布局。
- 所有更新首先输入NSM,然后最终复制到DSM镜像中。
- 如果DBMS支持更新,则必须使DSM镜像中的元组失效。
增量存储
示例:SAP HANA,Vertica,SingleStore,Databricks,Google Napa
后台线程将增量存储中的更新迁移并应用于DSM数据。
- 批量处理大块数据,然后将其写出为PAX文件。
- 一旦它们进入列存储,就在增量存储中删除记录。
增量存储是一个面向行的写缓冲区,吸收更新,并定期批量合并到列存储中。

