
11711 Advanced NLP: Learning & Inference
Lec6 预训练
基本思想
预训练的基础模型将适应下游任务。

迁移学习:从一个任务中获取“知识”并应用于另一个任务
• 更少的任务数据:使用更少的数据达到给定的性能水平
• 更好的任务性能:达到比从头开始训练更高的性能
• 一个模型,多种任务:方便,摊薄成本,许多用途的起点,…
主要因素
每个模型受以下四个主要因素的影响:
• 架构: 神经网络架构
• 任务: 模型预测的内容(例如,下一个标记)
• 数据: 用于训练模型的数据
• 超参数:例如,学习率,批量大小
掩码语言建模
掩码语言建模(MLM)训练语言模型以根据剩余可见上下文预测掩码标记。这个目标在双向模型(如BERT)中被广泛使用。
MLM损失定义为:
\[ \mathcal{L}_{\text{MLM}}(\theta; D) = -\frac{1}{|D|} \sum_{x \in D} \;\mathbb{E}_{M \sim \text{corrupt}(x)} \sum_{t \in M} \log p_\theta(x_t \mid x_{-M}) \]
\(x \in D\):来自数据集的输入序列(句子)
\(M\):随机抽样的掩码标记位置集合
\(\text{corrupt}(x)\):应用于\(x\)的掩码(损坏)过程
\(x_{-M}\):序列中所有未掩码的标记
\(x_t\):位置\(t\)的真实标记
\(p_\theta(x_t \mid x_{-M})\):给定可见上下文预测\(x_t\)的模型概率
去噪视角:MLM可以被视为去噪自编码器:输入通过掩码标记被损坏,模型学习重建原始序列。
伪似然目标:MLM最大化给定序列其余部分的掩码标记的条件对数概率之和,而不是建模序列的完整联合似然。这对应于最大化伪似然而不是真实的联合似然。
自回归语言建模
给定所有先前的标记\(x_{<t}\)预测下一个标记\(x_t\)。 [ {}(; D) = - {x D}
{t=1}^{|x|} p(x_t x_{<t}) ] 关键特性 -
最大化训练数据的似然
- 拟合真实数据分布\(p_*\)
- 等价于具有单热目标分布的交叉熵
- 可以解释为学习压缩由\(p_*\)生成的数据

评估模型
- 损失(训练、验证、测试)
- 诊断训练轨迹,比较同一家族的模型
- 少量提示
- 微调
数据
- 数量:我有多少数据?
- 质量:对训练是否有益?(提取、过滤、去重)
- 覆盖率:数据是否覆盖我关心的领域,并且比例正确?
- 我们可以训练一个分类器过滤,以帮助我们检测内容
Lec7 规模法则与上下文学习
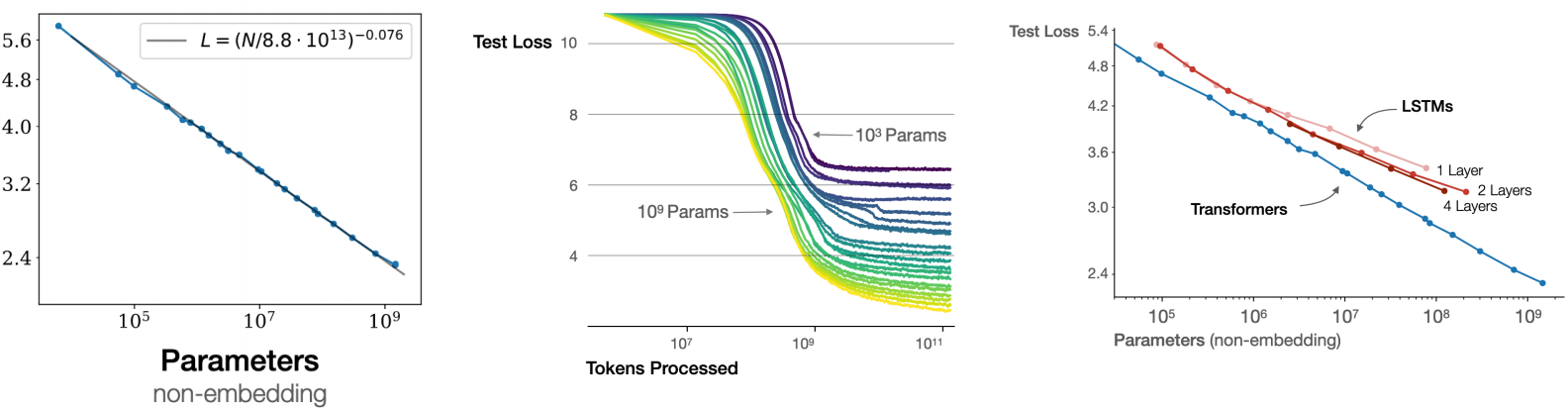
规模法则
训练 = 花费计算
在固定的预训练预算下,我们应该如何分配预算以实现最佳模型?

变压器LM的核心近似(Kaplan et al. 2020): \[ C \approx 6ND \]
- N = 参数数量,D = 标记数量,C = FLOPs
- 示例:Llama 2 7B在2T标记上 → C ≈ 8.4 × 10²² FLOPs
核心问题:在固定的C下,如何在N和D之间进行拆分?
幂律
\[ L = a \cdot x^{b} \quad \Rightarrow \quad \log L = \log a + b \cdot \log x \]
将x加倍 → L变为L · 2ᵇ。当b = −0.095时,加倍数据仅减少损失约6.4%。收益递减非常严重——线性损失改善需要指数级更多资源。

数据规模
\[ L = (D / D_c)^{-b} \]
- 三个区域:小数据 → 幂律区域 → 不可减少的误差(受数据熵限制)
- 重复数据:4个周期≈新数据;40个周期→毫无价值(Muennighoff+ 2025)
- 不同领域(维基百科、书籍、公共抓取)具有不同的规模曲线

模型大小规模
\[ L = (N / N_c)^{-b} \]
- 更大的模型更样本高效(用更少的标记达到更低的损失)
- 变压器的扩展性显著优于LSTM
计算最优训练
| 论文 | N_opt | D_opt | 含义 |
|---|---|---|---|
| Kaplan et al. 2020 | ∝ C⁰·⁷³ | ∝ C⁰·²⁷ | 优先考虑更大的模型 |
| Chinchilla (Hoffmann et al. 2022) | ∝ C⁰·⁵ | ∝ C⁰·⁵ | N和D同等扩展 |
∝表示成比例

Chinchilla的洞察:许多现有的LLM(例如,Gopher 280B)被训练不足。这直接影响了LLaMA的设计——较小的模型在更多数据上进行训练。
进行小规模实验 → 适应规模法则 → 推断目标运行的最佳超参数(模型大小、标记、批量大小、学习率)。
提示与上下文学习
三种提示策略
| 策略 | 格式 | 关键问题 |
|---|---|---|
| 无提示 | 原始文本补全 | 不可控 |
| 零-shot | 指令 + 输入 | 输出格式不稳定;对措辞敏感 |
| 少量-shot (ICL) | 指令 + K个示例 + 输入 | 示例定义格式和任务;无参数更新 |
ICL现象(Agarwal et al. 2024)
- 任务检索:有时仅输入示例的效果与(输入,输出)对一样好——ICL部分“检索”预训练模式而不是学习新的映射

预训练偏差:默认标签需要少量示例;翻转/抽象标签需要更多示例以克服内置关联

敏感性:示例顺序、标签平衡和标签覆盖率都会显著影响性能(Lu et al. 2021;Zhang et al. 2022)

模型变异:从多次示例中受益的能力差异很大(Gemini 1.5 Pro在1024-shot时提升;GPT-4-Turbo早期达到饱和)

聊天提示
消息格式为系统 / 用户 / 助手角色 → 分词器将其转换为带有特殊标记的字符串。系统提示定义模型行为(推理策略、安全规则、输出格式等)。
思维链(CoT)
- 少量-shot CoT(Wei et al. 2022):在示例中包含推理步骤
- 零-shot CoT(Kojima et al. 2022):附加“让我们一步一步思考”
- 关键洞察:CoT为模型提供自适应计算时间——每个推理标记是额外的前向传递
提示链
顺序链多个LLM调用(使用不同的提示/外部工具):
1 | 输入 → LLM₁ → 中间结果 → LLM₂ → 中间结果 → ... → 输出 |
实现问题分解、工具使用(搜索、代码执行)和多步骤推理。
Lec8 微调
什么是微调?
在任务特定数据上继续基于梯度的训练预训练模型。给定预训练参数θ₀和数据集D = {(x, y)ₙ}: \[ \theta^* = \arg\min_\theta \mathbb{E}_{(x,y)\sim D} [\mathcal{L}(f_\theta(x), y)] \] 也称为监督微调(SFT)。使用正则化/丢弃以防止过拟合。
两种微调范式
分类微调:在最后的隐藏状态上添加线性头。 \[ p_\theta(y \mid x) = \text{softmax}(Wh + b), \quad W \in \mathbb{R}^{K \times d}, \; b \in \mathbb{R}^K \]
- 损失:交叉熵 \(\mathcal{L} = -\log p_\theta(y \mid x)\)
- 更新所有参数 \(\theta = (\theta_0, W, b)\)
语言模型微调:保持LM架构,在(输入,输出)对上训练。
保持LM架构,在(输入,输出)对上训练。连接为[start] x [sep] y [end],仅对输出标记计算损失:
\[ \mathcal{L}_{\text{MLE}} = -\sum_{t=1}^{T} \log p_\theta(y_t \mid x, y_{<t}) \] 不需要额外的头——使用现有的LM头。
更新哪些参数?
| 选项 | 更新内容 | 成本 | 权衡 |
|---|---|---|---|
| 仅头部 | \(K \times d + K\)参数 | 最便宜 | 假设预训练表示已经是线性可分的 |
| 完全微调 | 所有 | \(\theta\) | 可能导致过拟合 |
| PEFT | 小子集 | \(\theta\) | 可以改变表示 |
LoRA(低秩适应)[Hu et al. 2021]
关键思想:用低秩矩阵近似权重更新。
对于权重\(W_0 \in \mathbb{R}^{d \times d'}\),将更新分解为:
\[ \Delta W = BA, \quad B \in \mathbb{R}^{d \times r}, \; A \in \mathbb{R}^{r \times d'}, \; r \ll \min(d, d') \]
- 冻结\(W_0\),仅训练\(A\)和\(B\)
- 最终权重:\(W = W_0 + \frac{\alpha}{r} \cdot BA\)
- 通常应用于注意力层中的\(W_q\)和\(W_v\)
- 训练后,将\(\Delta W\)合并到\(W_0\)中 → 没有额外的推理成本

微调的效果
数据效率:预训练模型在比从头开始训练少得多的示例下达到良好性能(Howard & Ruder 2018 — ULMFiT)。
分布收敛:微调最小化\(D_{\text{KL}}(p_{\text{finetune}} \| p_\theta)\)而不是\(D_{\text{KL}}(p_{\text{data}} \| p_\theta)\)。模型的分布变得更窄且专业化。
副作用:
- 摘要模型在翻译时失败(失去了通用性)
- 模型变得依赖于训练期间使用的确切提示格式
- 微调后少量学习能力可能下降
指令微调
在多个任务上对(指令 + 输入,输出)对进行微调,使其学习通用地遵循指令。

聊天微调
聊天只是具有对话格式的指令微调:
- 系统提示 + [用户,助手,用户,助手,…]
- 特殊标记标记角色边界(例如,
<|start_header_id|>user<|end_header_id|>) - 指令 + 输入隐式嵌入在对话中
数据来源:OpenOrca(16个手写系统提示,GPT-4输出,2.9M示例),LMSys-1M(来自在线LLM服务的真实用户对话)

知识蒸馏
使用强大的教师模型训练一个较小的学生模型。两种方法都最小化教师\(q\)与学生\(p_\theta\)之间的\(D_{\text{KL}}(q \| p_\theta)\)。
标记级蒸馏 [Hinton et al. 2015]
学生在每个标记位置模仿教师的完整概率分布:
\[ \mathcal{L}_{\text{distill}} = -\sum_{y_t \in V} q(y_t \mid y_{<t}, x) \cdot \log p_\theta(y_t \mid y_{<t}, x) \]
- 使用软标签(教师的分布)而不是硬的单热标签
- 需要访问教师的logits
- 比标准交叉熵提供更丰富的信号(仅使用正确的标记)

序列级蒸馏 [Kim & Rush 2016]
教师生成完整输出;学生在其上进行微调:
\[ \mathcal{L}_{\text{seq}} = \mathbb{E}_{y \sim q(y|x)} \left[-\log p_\theta(y \mid x)\right] \]
- 只需要教师生成的文本,而不是logits(黑箱友好)
- 示例:DeepSeek-R1-Distill-Qwen-7B = 在DeepSeek-R1的输出上微调的Qwen-7B
- 数学上也最小化\(D_{\text{KL}}(q \| p_\theta)\),只是使用蒙特卡洛近似

增强教师 [West et al. 2022]
教师可以是一个增强的LLM:
\[ q \propto p_{\text{LLM}}(y \mid x) \cdot A(x, y) \] 其中\(A\)是分类器/验证器。如果增强的教师优于单独的\(p_{\text{LLM}}\),则蒸馏的学生可以超越\(p_{\text{LLM}}\)——学生通过过滤/验证的数据变得比其基础教师更好。
Lec9 解码算法
基本设置
自回归语言模型
\[ p_\theta(y_{1:T} | x) = \prod_{t=1}^{T} p_\theta(y_t | y_{<t}, x) \]
下一个标记分布
每个项\(p_\theta(y_t | y_{<t}, x)\)为下一个标记提供概率分布。
解码:选择下一个标记,以便我们最终得到输出\(y_{1:T}\)。
解码作为优化
目标:MAP解码
找到最可能的输出: \[ \hat{y} = \arg\max_{y \in \mathcal{Y}} p_\theta(y | x) \]
- 也称为模式寻求或最大后验(MAP)
- 关键挑战:输出空间\(\mathcal{Y}\)非常大

方法1:贪婪解码
对于\(t = 1 \ldots \text{结束}\): \[ \hat{y}_t = \arg\max_{y_t \in V} p_\theta(y_t | \hat{y}_{<t}, x) \]
局限性:不保证最可能的序列。

方法2:束搜索
- 宽度限制的广度优先搜索
- 在每一步保持\(B\)个可能路径
- \(B = 1\):贪婪解码
- \(B = |V|^{T_{\max}}\):精确MAP(不可处理)
- 实际上:\(B = 16\)(超参数)

HuggingFace接口: 1
2
3
4
5# 贪婪
model.generate(do_sample=False, num_beams=1)
# 束搜索
model.generate(do_sample=False, num_beams=16)
MAP解码的陷阱
1. 退化 - 重复陷阱:模型对重复循环分配高概率 - 短序列:最高概率序列可能为空 - 补救:长度归一化
2. 非典型性 - 最可能的结果 ≠ 典型结果 - 示例:偏置硬币\(\Pr[H] = 0.6\),100次翻转的最可能结果是全是正面(非典型!)
3. 概率分布 - 当存在多种方式表达相同事物时,概率在变体之间分散 - 最高概率输出可能不是“最佳”

采样
祖先采样
对于\(t = 1 \ldots \text{结束}\): \[ \hat{y}_t \sim p_\theta(y_t | \hat{y}_{<t}, x) \]
- 等同于序列采样:\(y_{1:T} \sim p_\theta(y_{1:T} | x)\)
- 通过分类采样实现(PyTorch等)
HuggingFace接口:
1 | model.generate(do_sample=True) |
祖先采样的问题
重尾问题:
- 即使每个坏标记的概率很小,坏标记的总和也具有非平凡的概率
- 导致不连贯
复合错误: - 采样没有坏标记的概率:\((1 - \epsilon)^T\) - 示例:\(\epsilon = 0.01, T = 128 \Rightarrow p(\text{没有坏标记}) = 0.276\)
解决方法:截断尾部
Top-k采样:仅从\(k\)个最可能的标记中采样 \[ \hat{y}_t \sim \begin{cases} p_\theta(y_t | y_{<t}, x) / Z_t & \text{如果 } y_t \text{ 在 top-}k \\ 0 & \text{否则} \end{cases} \]
Top-p采样:仅从前\(p\)概率质量中采样
温度采样:使分布更加尖锐 \[ \text{softmax}(x, \tau) = \frac{\exp(x/\tau)}{\sum_i \exp(x_i/\tau)} \]
| 温度 | 参数 | 优点 | 缺点 |
|---|---|---|---|
| 高 | \(\tau \geq 1\) | 多样化 | 不连贯 |
| 低 | \(\tau < 1\) | 连贯 | 重复 |
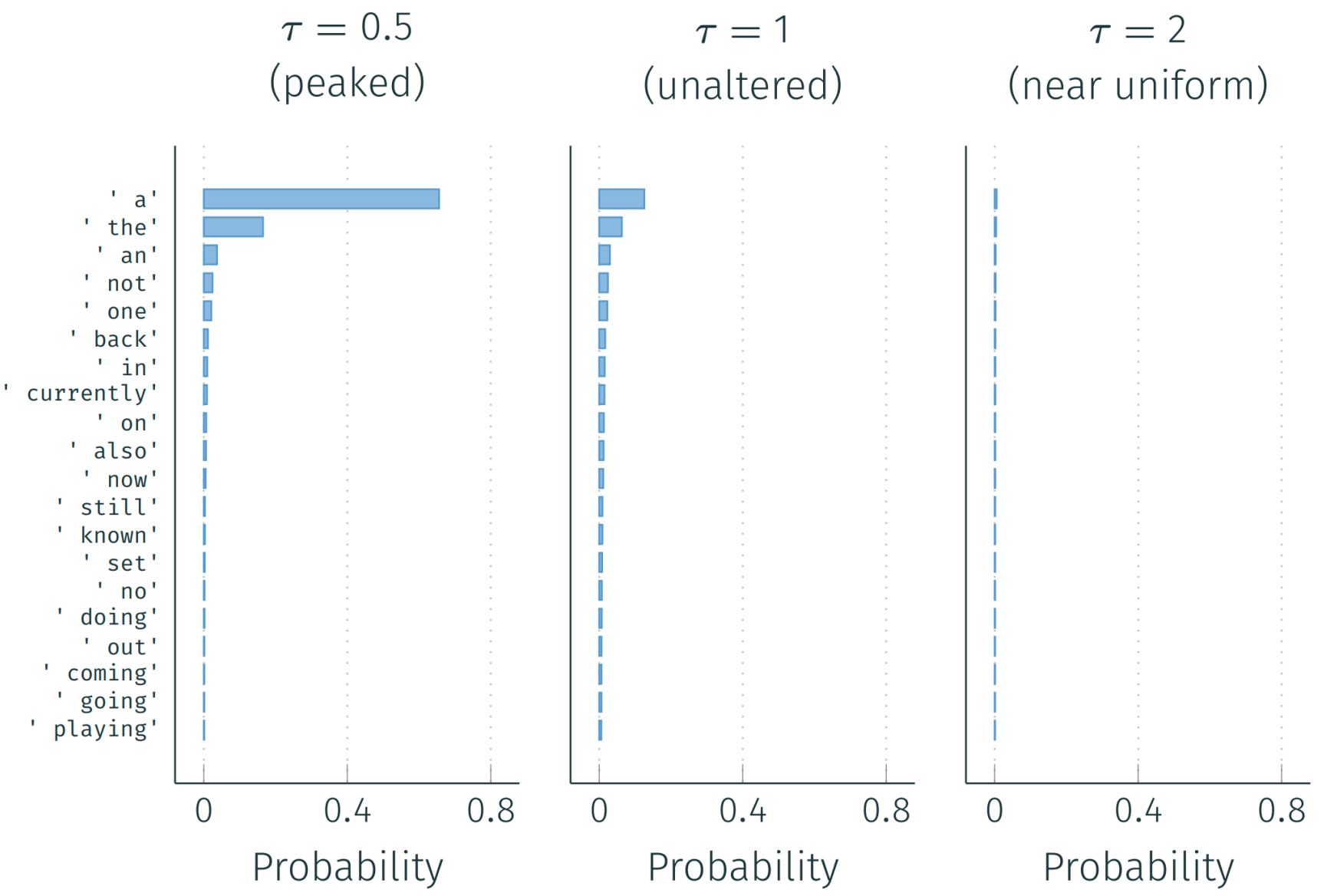
HuggingFace接口:
1 | # Top-k |
其他截断策略
| 方法 | 阈值策略 |
|---|---|
| Top-\(k\) | 从\(k\)个最可能的中采样 |
| Top-\(p\) | 累计概率最多为\(p\) |
| \(\epsilon\) | 概率至少为\(\epsilon\) |
| \(\eta\) | 最小概率与熵成比例 |
| Min-\(p\) | 概率至少为\(p_{\min}\),按最大标记概率缩放 |
加速解码
为什么解码慢?
时间瓶颈: \[ \text{时间} = \max\left(\frac{\text{操作FLOPs}}{\text{设备FLOP/s}}, \frac{\text{传输数据(GB)}}{\text{内存带宽(GB/s)}}\right) \]
- 计算限制:例如,\(A = BC\)(矩阵乘法)
- 内存限制:例如,\(a = Bx\)(矩阵-向量乘法)
- 解码一个标记通常是内存限制的
指标
延迟:用户等待多久? - 第一个标记的时间,每个请求的时间
吞吐量:每秒完成多少请求? - 每秒标记数,每秒请求数
键值缓存
问题:没有缓存,计算注意力需要\(O(T^2)\)的重新计算。
解决方案:存储先前计算的键和值。
在解码的第\(t\)步(1层,1头): \[ \begin{align} q_t &= h_t W_q \in \mathbb{R}^{1 \times d_k} \\ k_t &= h_t W_K \in \mathbb{R}^{1 \times d_k} \\ v_t &= h_t W_V \in \mathbb{R}^{1 \times d_v} \end{align} \]
缓存:\(K_{1:t-1} \in \mathbb{R}^{(t-1) \times d_k}\),\(V_{1:t-1} \in \mathbb{R}^{(t-1) \times d_v}\)
将\(k_t\)附加到\(K_{1:t-1}\),将\(v_t\)附加到\(V_{1:t-1}\): \[ z_t = \text{softmax}\left(\frac{q_t K_{1:t}^T}{\sqrt{d_k}}\right) V_{1:t} \]
加速:将\(O(T^2)\)减少到\(O(T)\)计算。
加速单个标记
| 目标 | 策略 | 示例 |
|---|---|---|
| 减少内存带宽 | 量化、蒸馏、架构 | GPTQ、AWQ、GQA/MQA |
| 增加FLOP/s | 在硬件上优化操作 | FlashAttention、torch.compile |
| 减少FLOPs | 在架构中减少FLOPs | 专家混合、Mamba |
加速完整序列
| 策略 | 思路 | 示例 |
|---|---|---|
| 在时间上并行化 | 便宜地草拟标记,进行并行验证 | 投机解码 |
| 在时间上并行化 | 并行生成多个标记 | 非自回归模型 |
投机解码: 1. 使用小型草拟模型\(q\)提前生成标记 2. 大模型\(p\)并行处理草拟的标记 3. 以概率接受:\(\alpha_i = \min\left(1, \frac{p(\text{标记} | \ldots)}{q(\text{标记} | \ldots)}\right)\)
加速多个序列
| 策略 | 思路 | 示例 |
|---|---|---|
| 状态重用 | 共享前缀\(\Rightarrow\)共享KV缓存 | PagedAttention、RadixAttention |
| 改进批处理 | 更好的调度 | 连续批处理 |
| 程序级优化 | 优化完整生成图 | SGLang、DSPy |
总结
- 解码作为优化:贪婪、束搜索、MAP(固定路线最大化概率)
- 陷阱:退化、非典型性、概率分布
- 采样:祖先、top-k、top-p、温度。(改变后续采样的概率分布)
- 解决尾部概率和多样性问题
- 高效推理:KV缓存、投机解码、批处理
- 对于大规模部署至关重要
一个关键的收获是,束搜索或贪婪是基于搜索的,它希望获得一个固定的优化输出,但采样引入了多样性或变异,以生成更具创造性的答案,并可能得到不同的答案。

