11711 Advanced NLP: Architectures
Lec4 循环神经网络
动机: N-gram 和前馈模型的上下文有限(N-1 个标记)。RNN 理论上提供无限的上下文。
三种序列模型
- 递归: 基于历史编码条件表示
- 卷积: 基于局部上下文条件表示
- 注意力: 基于所有标记的加权平均条件表示
基本 RNN (Elman, 1980)
一个序列模型 \(f_\theta(x_1, \ldots, x_{|x|}) \rightarrow h_1, \ldots, h_{|x|}\),在每一步转换隐藏状态:
\[h_t = \sigma(W_h h_{t-1} + W_x x_t + b)\]
其中 \(\sigma\) 是激活函数(tanh, relu),\(h_t \in \mathbb{R}^d\) 是隐藏状态,参数 \(\theta = \{W_h \in \mathbb{R}^{d \times d}, W_x \in \mathbb{R}^{d \times d_{in}}, b \in \mathbb{R}^d\}\)
用于语言建模: \(p_\theta(\cdot \mid x_{<t}) = \text{softmax}(W h_t)\)
RNN 训练
时间反向传播 (BPTT): 将 RNN 展开为 DAG 计算图,运行标准反向传播。
- 每一步使用相同的参数;梯度被累积
- 训练目标(最大似然估计):\(\min -\sum_{x \in D_{train}} \sum_t \log p_\theta(x_t \mid x_{<t})\)
- 并行化困难: 在步骤 \(t\) 计算损失需要 \(h_t\),这依赖于 \(h_{t-1}, h_{t-2}, \ldots\)
RNN 推理
生成一个标记 → 使用新的隐藏状态 → 重复直到 [EOS]
- 优点: 只需存储上一个隐藏状态(常量内存),每步 \(O(1)\),总长度 \(T\) 为 \(O(T)\)
- 缺点: 顺序处理,无法并行化
消失梯度
梯度在反向传播时减小:\(\frac{\partial L}{\partial h_0}\) 变得微小。
为什么? \(\frac{\partial h_T}{\partial h_t} = \prod_{t'=t}^{T} \frac{\partial h_{t'+1}}{\partial h_{t'}}\),其中 \(\frac{\partial h_{t'+1}}{\partial h_{t'}} = \text{diag}(\tanh'(\cdot)) W\)
当 \(W\) 的主特征值 \(< 1\) 时,梯度指数消失。影响: 无法建模长距离依赖关系!
门控:解决方案
基本思想: 通过学习的门在时间步之间传递信息。
\[h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t\]
其中 \(z_t = \sigma(W_z x_t + U_z h_{t-1})\) 是更新门,\(\tilde{h}_t\) 是候选状态。
- 当 \(z \to 0\):保留长期信息(\(\frac{\partial h_{t_2}}{\partial h_{t_1}} = 1\))
- 当 \(z > 0\):结合新的隐藏状态
GRU (Cho et al., 2014)
2-门架构: - 更新门 \(z_t\):我应该更新上一个隐藏状态吗? - 重置门 \(r_t = \sigma(W_r x_t + U_r h_{t-1})\):我应该在更新中使用隐藏状态吗?
\[\hat{h}_t = \tanh(W_h x_t + U_h(r_t \odot h_{t-1})), \quad h_t = (1-z_t) \odot h_{t-1} + z_t \odot \hat{h}_t\]
LSTM (Hochreiter & Schmidhuber, 1997)
4-门架构,带有额外的上下文向量。在实践中,GRU/LSTM 是对普通 RNN 的替代。
编码器-解码器
动机: 条件生成 \(p_\theta(y_1, \ldots, y_T \mid x)\)(例如,翻译、摘要)
架构: 将输入 \(x\) 编码为上下文向量 \(c \in \mathbb{R}^d\),在解码器中使用: - 初始化解码器隐藏状态 - 包含在递归更新中:\(W[h_t; x_t; c]\) - 包含在输出层:\(\text{softmax}(W[h_t; c])\)
训练: \(\min_\theta \sum_{(x,y) \in D} \sum_t -\log p_\theta(y_t \mid y_{<t}, x)\)
局限性: 所有标记只有一个上下文向量——我们能做得更好吗?
注意力 (Bahdanau et al., 2015)
关键思想: 在每个解码器步骤计算不同的上下文向量,作为编码器状态的加权和。
- 键: 编码器状态 \(h_1^{enc}, \ldots, h_N^{enc}\)
- 查询: 当前解码器隐藏状态 \(h\)
- 注意力分数: \(\alpha_n = \text{score}(h, h_n^{enc})\)
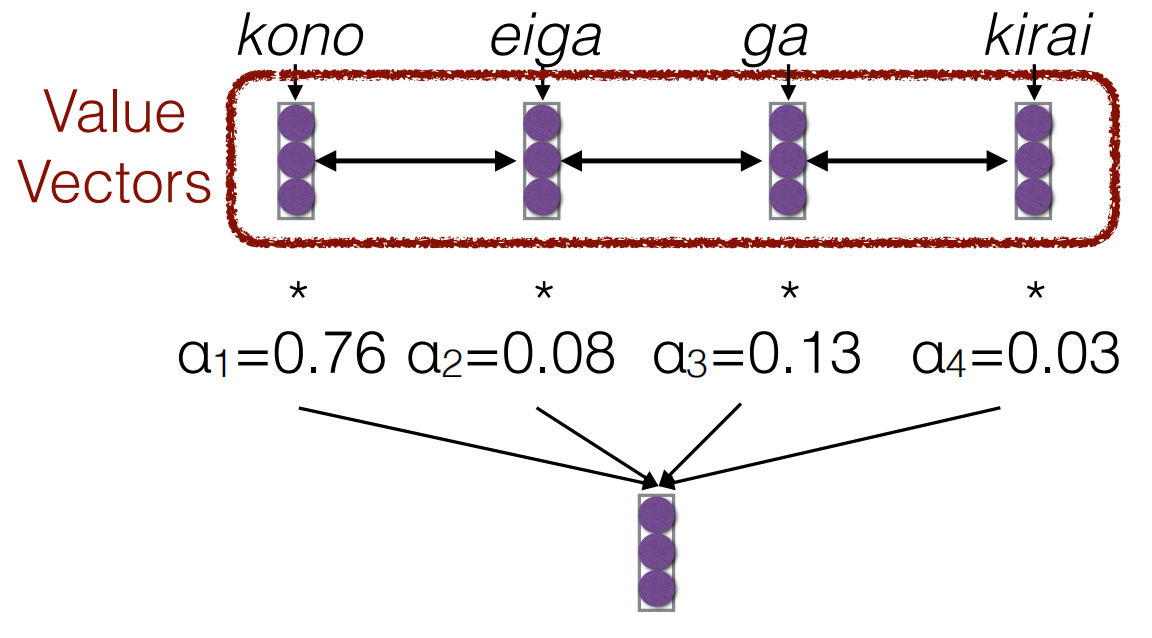
- 上下文向量: \(c = \sum_{n=1}^{N} \alpha_n h_n^{enc}\)
分数函数: - 点积:\(\text{score}(q, k) = q^\top k\) - 双线性:\(\text{score}(q, k) = q W k\) - 非线性:\(\text{score}(q, k) = w^\top \tanh(W[q; k])\)
用法: \(\text{logits} = \tanh(W_{out}[c_t; h_t])\)
关键要点
- RNN:具有递归隐藏状态的序列模型(理论上无限上下文)
- 普通 RNN 遇到消失梯度问题 → 使用 GRU/LSTM
- 编码器-解码器用于条件生成
- 注意力:通过编码器状态的加权和动态上下文向量
- RNN 训练是顺序的(难以并行化)→ 激励变换器(下一讲)
Lec5 变换器
此内容类似于 CS336-Lec3 架构与超参数
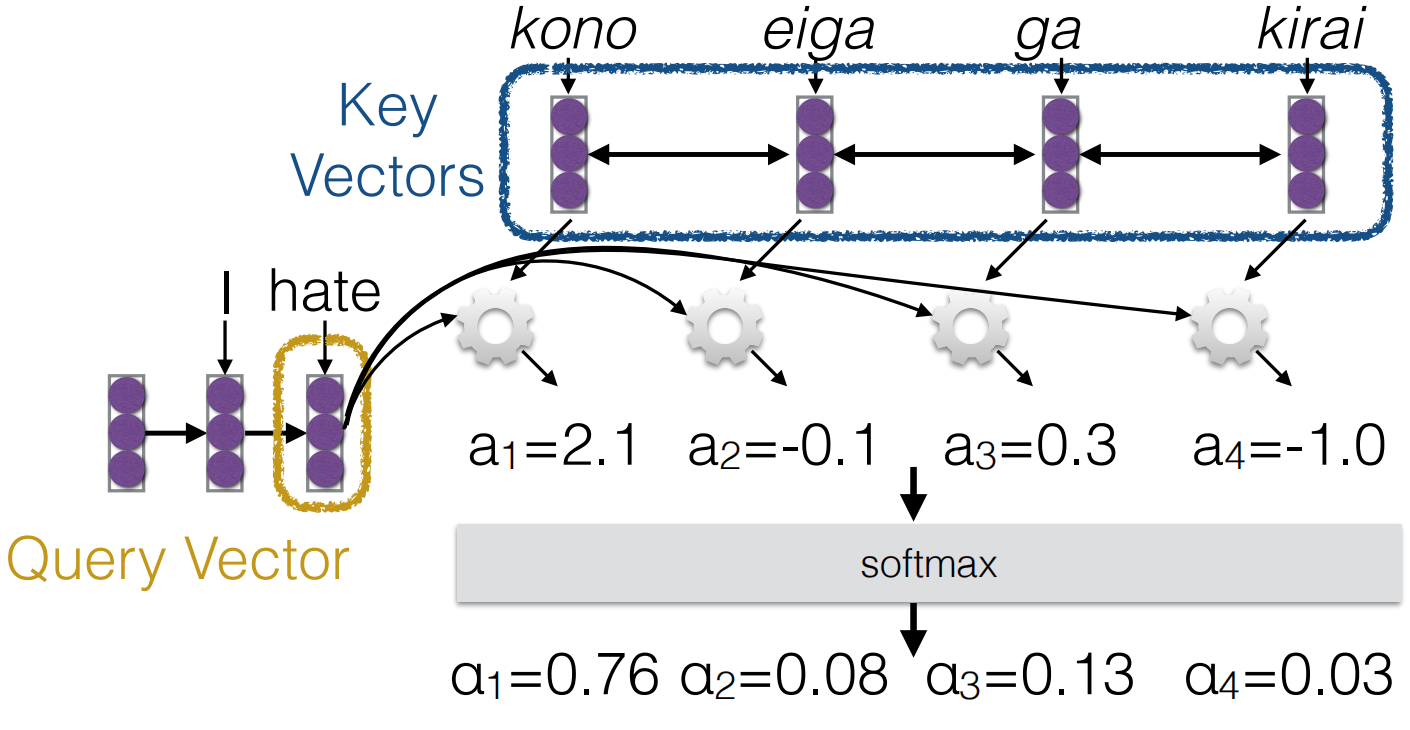
注意力分数函数:最常用的函数是
缩放点积。这解决了点积的规模随着维度增大而增加的问题。
\[
a(q, k) = \frac{q^\top k}{\sqrt{|k|}}
\]
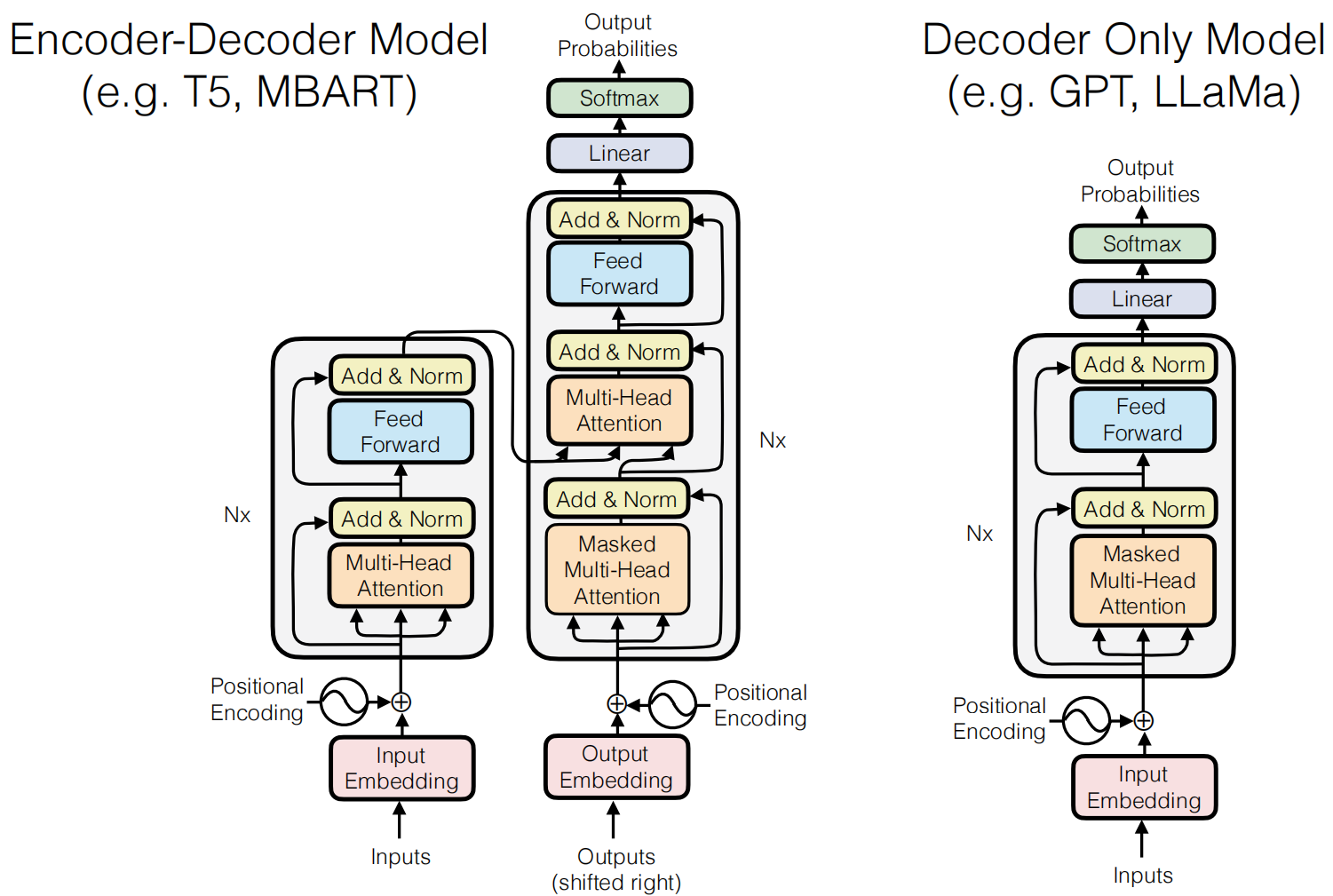
多头的直觉:句子不同部分的信息可以以不同方式帮助消歧。