
11868 LLM Sys: GPU Programming & Acceleration
GPU 编程
神经网络层和低级操作
一个简单的前馈神经网络用于文本分类,由一系列标准层组成。输入文本首先通过 嵌入层 映射为向量,然后是带有 ReLU 激活 的 线性层。一个 平均池化 操作将标记表示聚合为一个单一向量,最后一个 softmax 层 生成最终的类别概率。
在更低的层面,这些神经网络层是通过一小组基本操作实现的。矩阵乘法 用于线性层,逐元素操作 处理激活,而 归约操作(如平均)用于池化。这些操作的高效执行在很大程度上依赖于 GPU。
GPU 服务器的组成
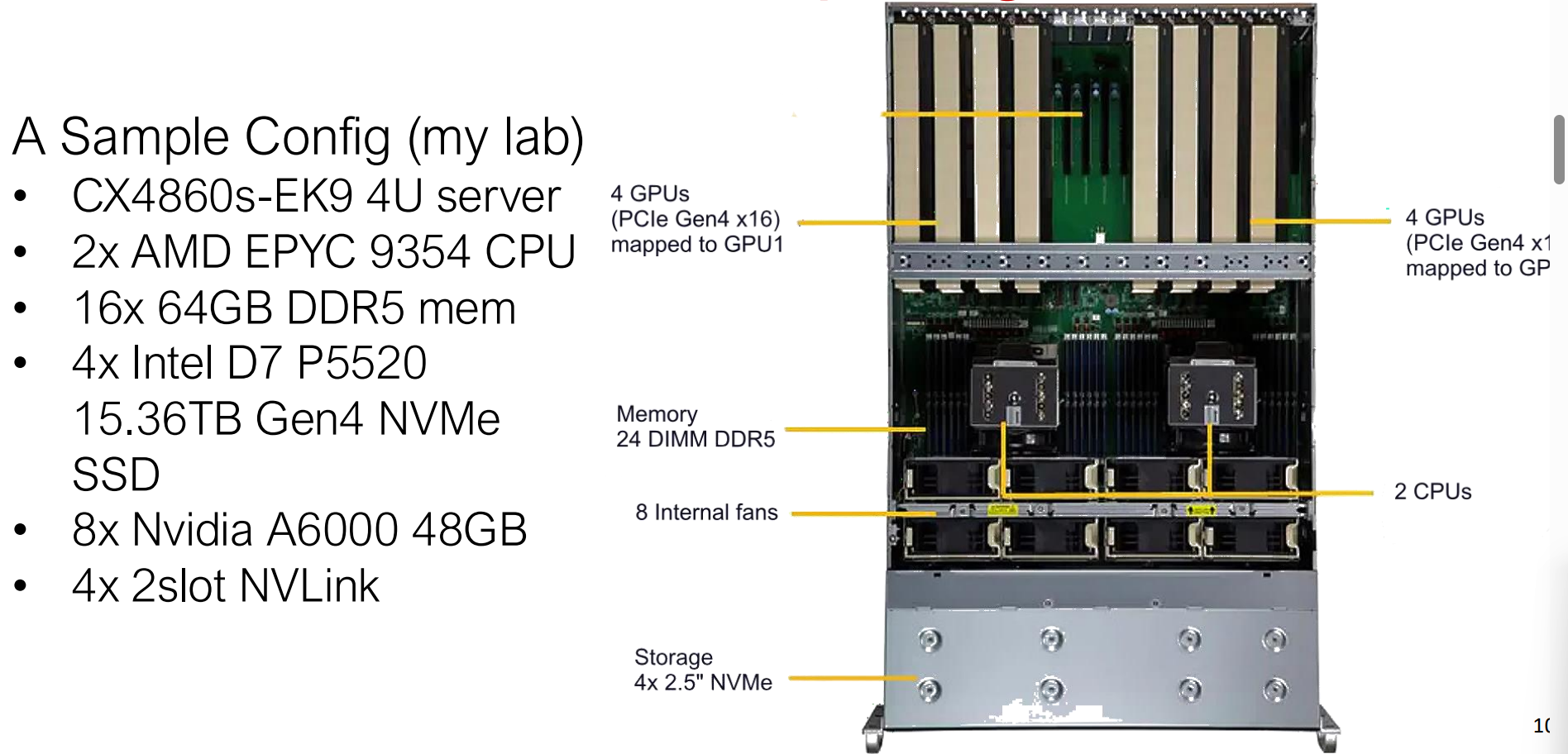
该图展示了一台现代的 4U 计算服务器,旨在处理高性能和 AI 工作负载。它结合了双 AMD EPYC CPU 和 多个通过 PCIe 和 NVLink 连接的 NVIDIA GPU,以及高带宽的 DDR5 内存和 NVMe 存储,以支持大规模并行计算。
GPU 架构
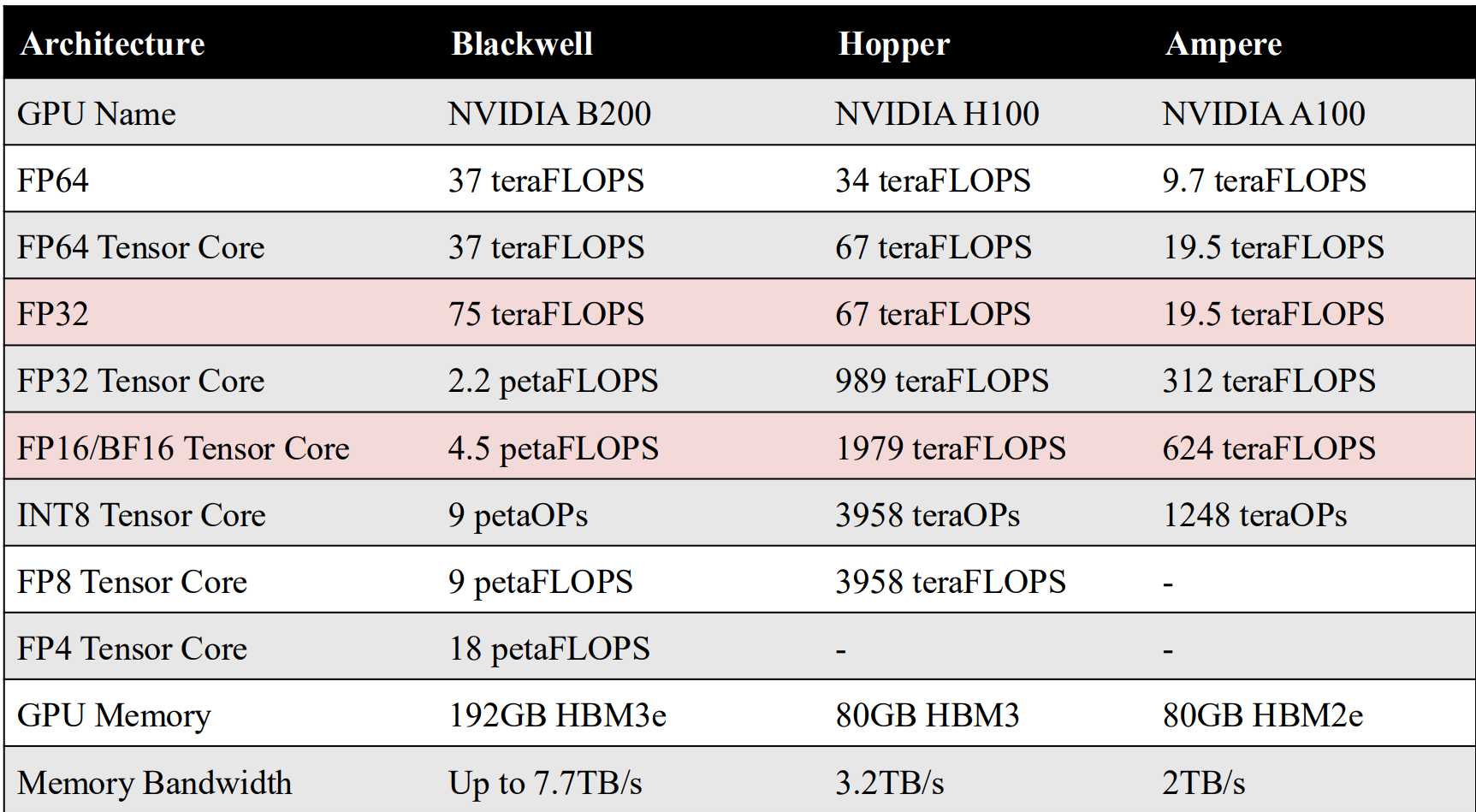
现代 GPU 通过优先考虑 面向吞吐量的并行性 而非单线程延迟来实现高性能。与 CPU 的少数复杂核心不同,GPU 由许多 流式多处理器(SMs) 组成,每个 SM 包含大量简单的计算核心,旨在并行执行相同的操作。
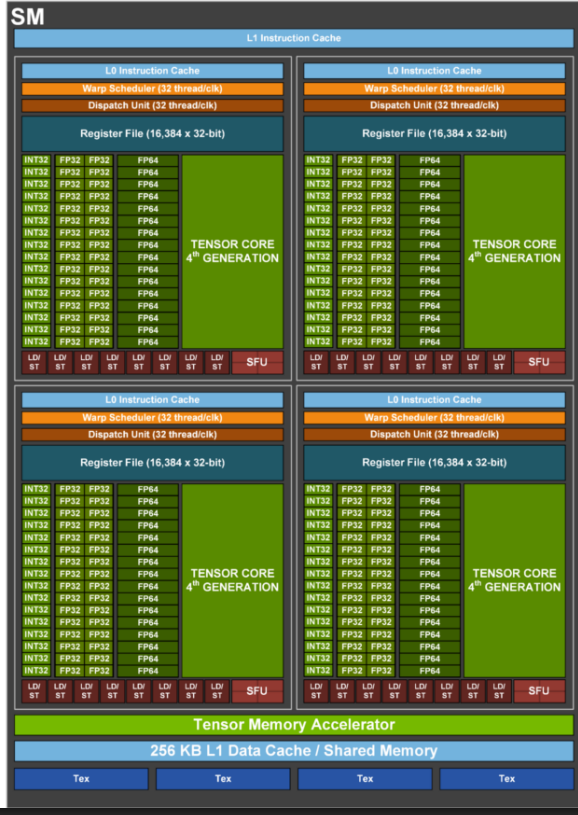
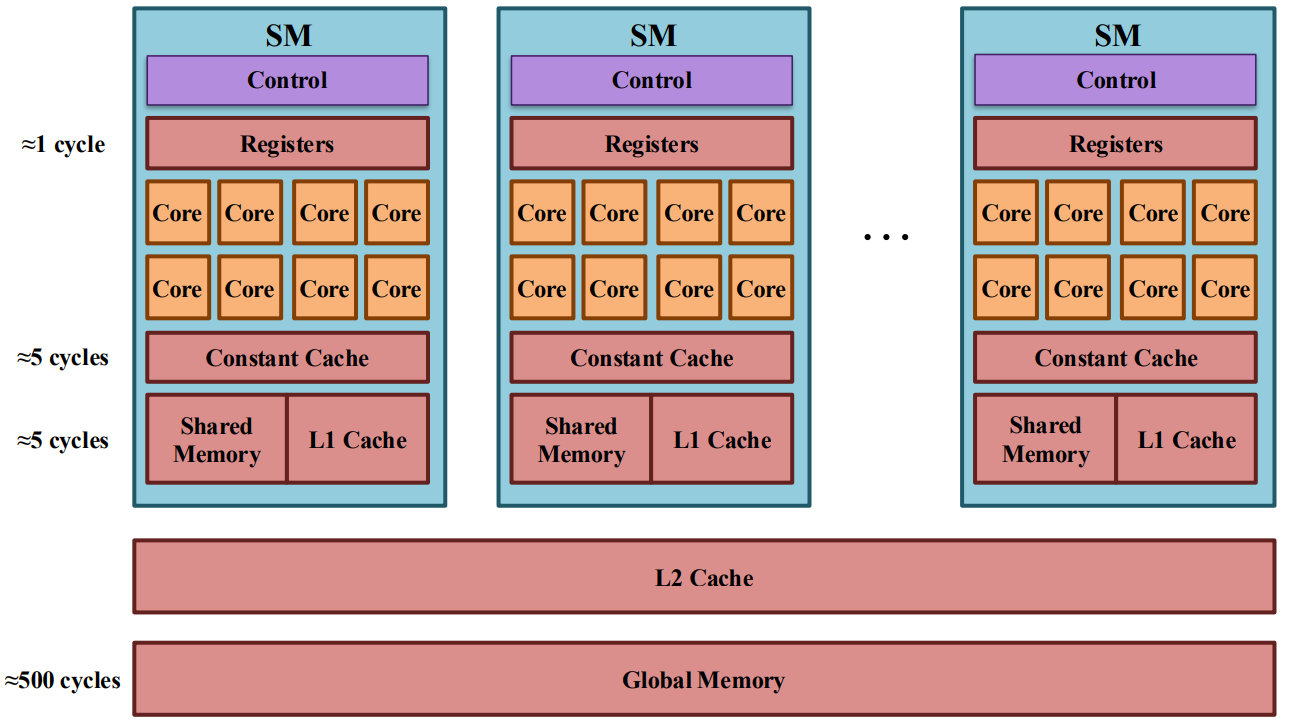
SM 是 GPU 的基本执行单元。每个 SM 被分为 四个分区,每个分区包含 32 个 CUDA 核心,与 warp 的大小相匹配,warp 是 NVIDIA GPU 中的基本调度和执行单元。一个 warp 由 32 个线程在锁步中执行相同的指令(SIMT:单指令,多线程)。因此,单个 SM 包含 128 个核心,在理想条件下每个周期可以执行多达 128 个 FP32 操作。
在每个分区内,warp 调度器 每个周期选择一个准备好的 warp,而 调度单元 将其指令发给适当的执行单元(例如,FP32 核心、张量核心或加载/存储单元)。GPU 不调度单个线程;相反,它们调度 warp。当一个 warp 因内存访问而停滞时,调度器可以立即切换到另一个准备好的 warp,几乎没有开销,从而使 GPU 能够通过大规模并发有效地 隐藏内存延迟。
每个 SM 还包含一个大的 寄存器文件(最快的片上存储)和一个共享的 L1 缓存/共享内存,这使得线程之间能够快速重用数据和通信。像 NVIDIA H100 这样的新架构显著增加了 L1/共享内存的容量,并增强了张量核心,进一步优化了 SM 以满足深度学习工作负载中常见的大规模矩阵和张量计算。
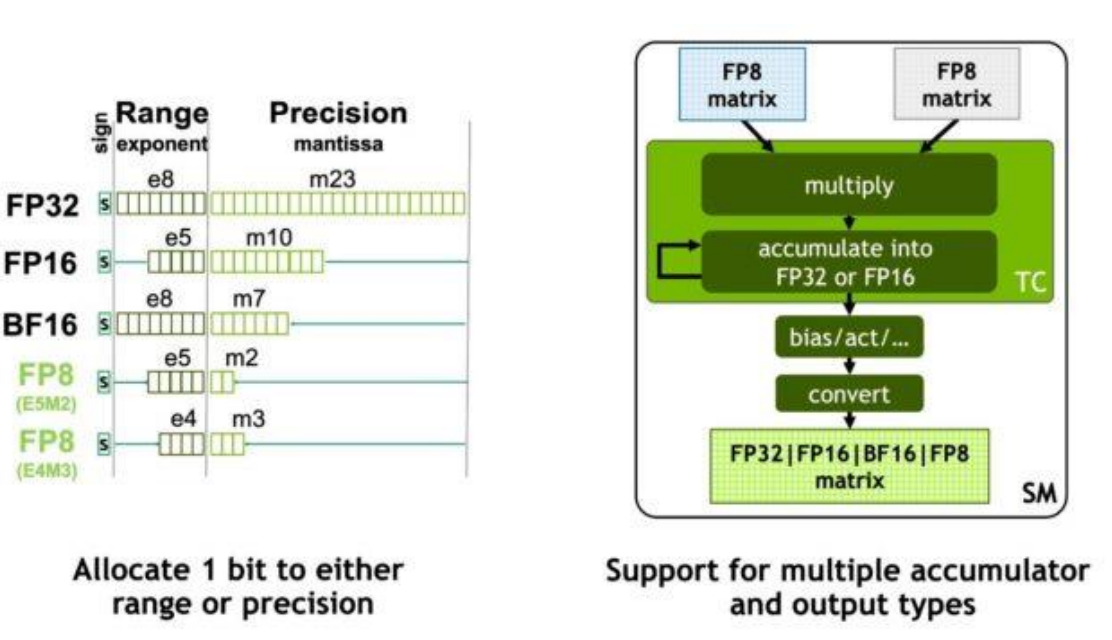
H100 引入了 FP8,以进一步提高吞吐量并减少大规模 AI 工作负载的内存带宽需求。通过 支持多种 FP8 格式并以更高精度累积结果,该架构实现了高性能和数值稳定性。
Transformer Engine 是 H100 中的一个硬件-软件协同设计系统,自动管理精度、缩放和累积,以安全地使用 FP8 进行 Transformer 工作负载。
CPU 与 GPU
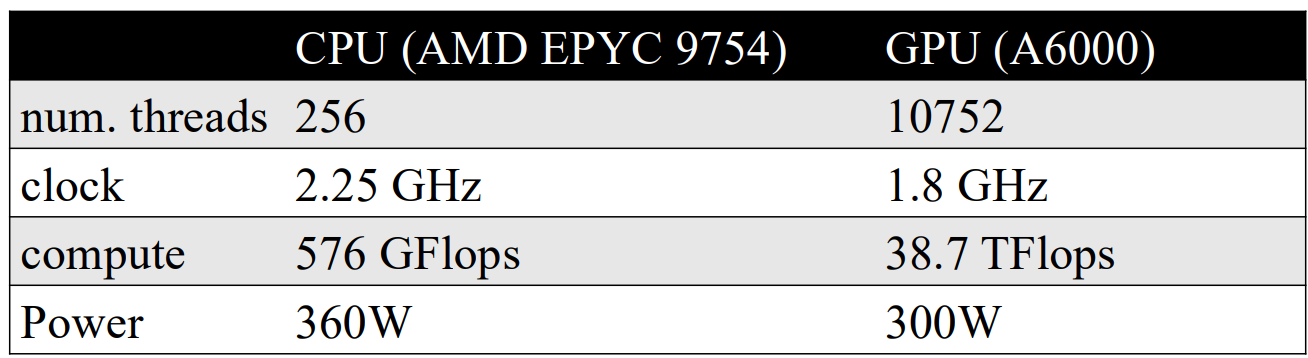
在 GPU 上执行程序
在 CUDA 编程模型中,CPU 作为主机控制执行并启动 GPU 内核,而 GPU 作为优化的大规模并行计算设备。内核使用 SIMT 模型执行,其中线程被组织成块和网格,并映射到多个 SM 进行并行执行。
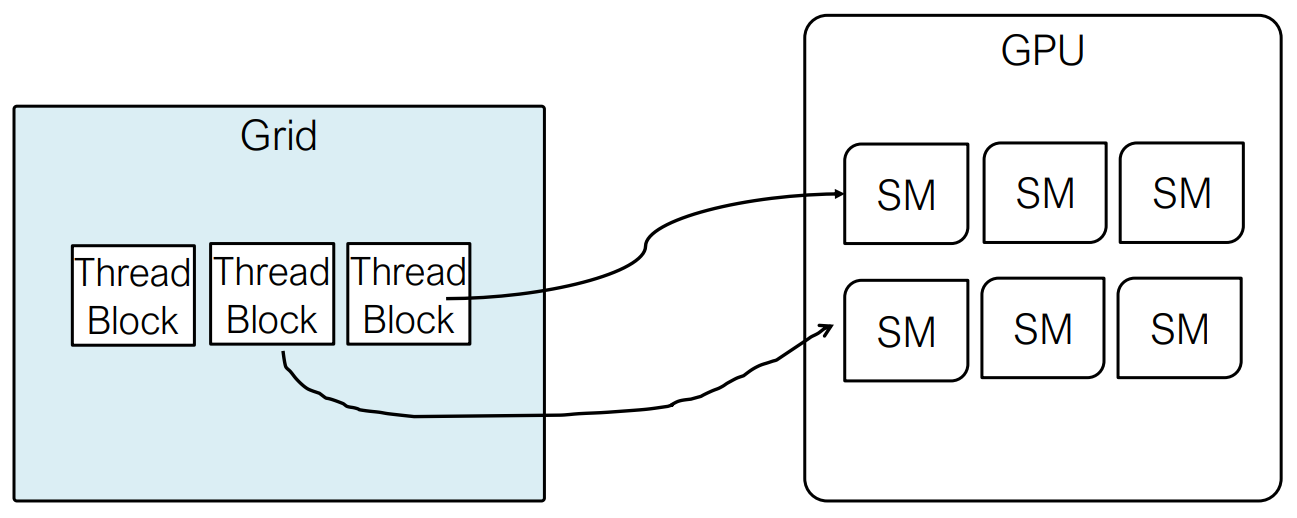
内核线程的执行方式
当启动 CUDA 内核时,线程首先被组织成 线程块,然后分配给 流式多处理器(SMs)。在一个 SM 内,每个线程块进一步 划分为 warp,warp 是 GPU 用于创建、管理、调度和执行线程的基本单元。
一个 warp 由 32 个线程 组成。所有线程在同一程序地址开始执行,但 每个线程维护自己的 程序计数器和寄存器状态。在任何给定周期,warp 在所有 32 个线程中执行 一个共同的指令,遵循 SIMT(单指令,多线程)执行模型。尽管 warp 内的线程由于分支可以采取不同的控制流路径,但硬件会对分歧路径进行串行化,这可能会降低性能。
SM 上的 Warp 执行模型
一旦 warp 被分配给 SM,其 执行上下文在整个 warp 生命周期内保持驻留在 SM 上。该上下文包括程序计数器、寄存器值和 warp 使用的任何共享内存。由于所有活动的 warp 都将其上下文保留在片上,在 warp 之间切换不需要保存或恢复状态,使得 warp 之间的上下文切换几乎是瞬时的。
在运行时,每个 SM 包含一个或多个 warp 调度器,它们不断选择一个具有活动和准备线程的 warp。所选 warp 的下一条指令随后被 发出(调度) 到适当的执行单元,例如 FP32 核心、张量核心或加载/存储单元。如果一个 warp 因长延迟操作(例如,全局内存访问)而停滞,调度器可以立即切换到另一个准备好的 warp,从而允许 SM 通过并发隐藏内存延迟。
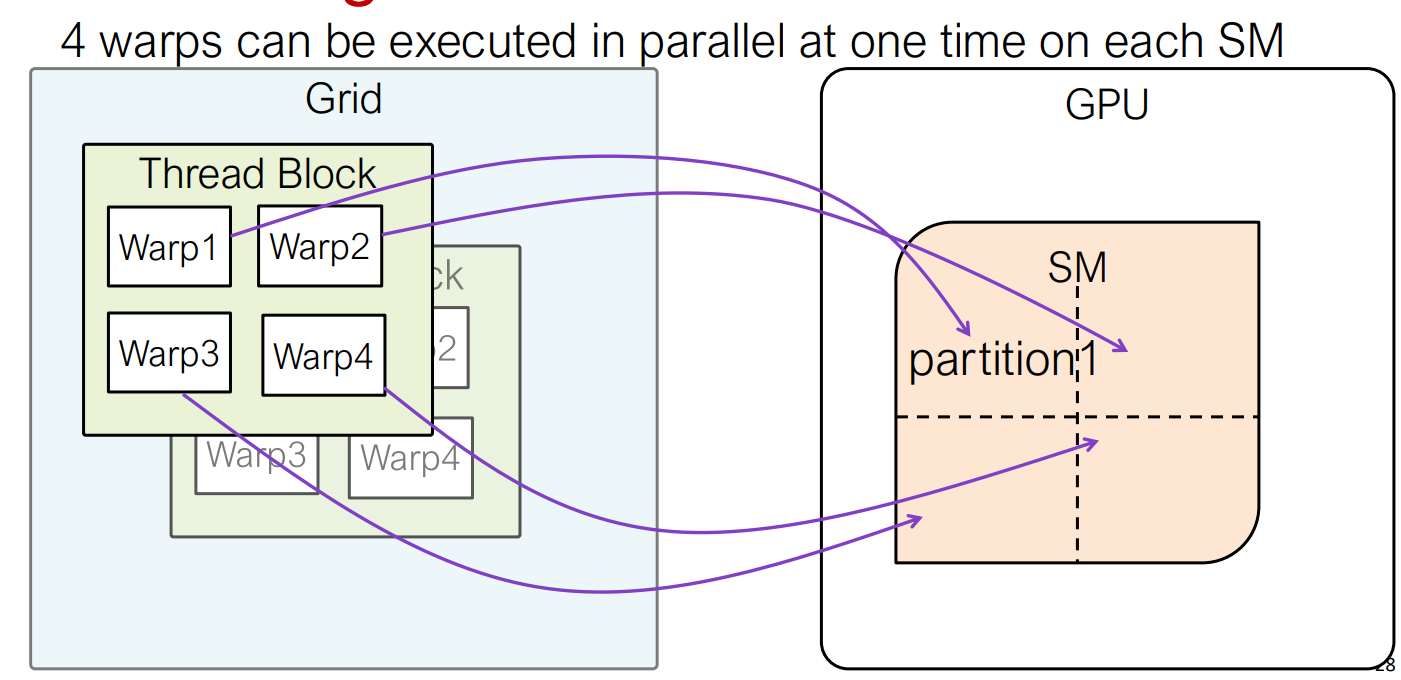
尽管 NVIDIA GPU 暴露了 SIMT 编程模型,但 warp 执行是通过硬件级别的带有预测和掩蔽的 SIMD 风格向量执行来实现的。
CPU-GPU 数据移动
CUDA 内核
CUDA 内核 是在 GPU 上运行的函数。从编程的角度来看,内核描述了 单个线程 的执行逻辑,代码本身是以 串行方式 编写的。并行性并不是来自代码结构,而是来自于内核被大量线程同时执行的事实。
当内核被启动时,成千上万的线程
可能会同时执行相同的内核函数。每个线程使用其
线程索引(例如,threadIdx,blockIdx)来确定其操作的数据部分。这遵循
SPMD(单程序,多数据)模型:相同的程序在许多线程中复制,每个线程处理不同的数据元素。
CUDA 内核的关键特性:
- 内核代码是 每个线程串行的
- 通过 许多线程执行相同内核 实现大规模并行性
- 线程索引用于将线程映射到数据
- 程序员表达 一个线程做什么,而不是线程如何被调度
编译 CUDA 代码
CUDA 程序遵循 异构编程模型,其中 单个源文件包含 主机(CPU) 代码和 设备(GPU) 代码。 CUDA 编译器 NVCC 作为编译驱动程序,分别处理这两部分并以不同方式编译它们。
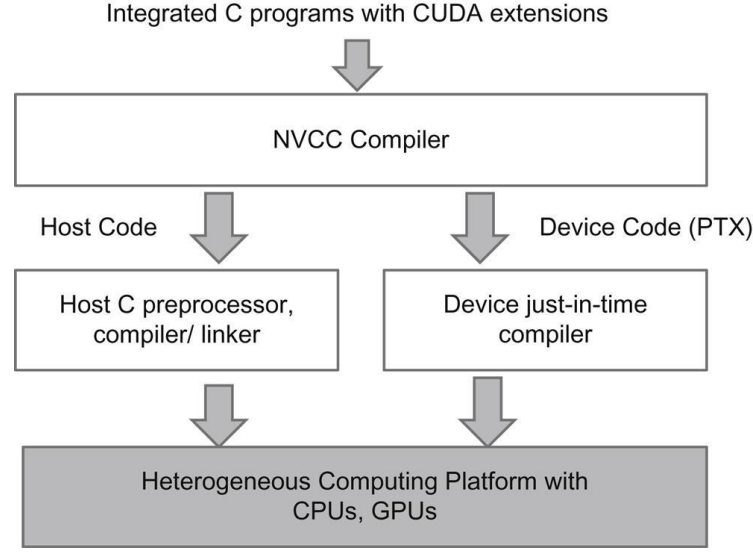
在编译期间:
- 主机代码 被传递给标准 C/C++
编译器(例如,
gcc或clang),并编译为 CPU 可执行代码。 - 设备代码(CUDA 内核)被编译为 PTX,这是 NVIDIA GPU 的中间表示。
在运行时,PTX 代码由 NVIDIA 驱动程序 即时编译(JIT) 为特定于目标 GPU 架构的机器代码。这种设计允许相同的 CUDA 二进制文件在不同的 GPU 代上运行,而无需重新编译源代码。
PTX 作为中间表示,而不是最终的机器代码。在运行时,NVIDIA 驱动程序将 PTX JIT 编译为特定于架构的 GPU 指令,从而使相同的 CUDA 二进制文件能够在不同的 GPU 代上运行。
基本 GPU CUDA 操作
在 CUDA 中,所有 GPU 操作由 CPU 协调。主机显式地使用
cudaMalloc 分配设备内存,使用 cudaMemcpy
在主机和设备之间传输数据,启动 GPU 内核,最后使用 cudaFree
释放设备内存。这种显式的内存管理模型反映了 CUDA 的异构设计,其中 GPU
作为由 CPU 控制的计算加速器。
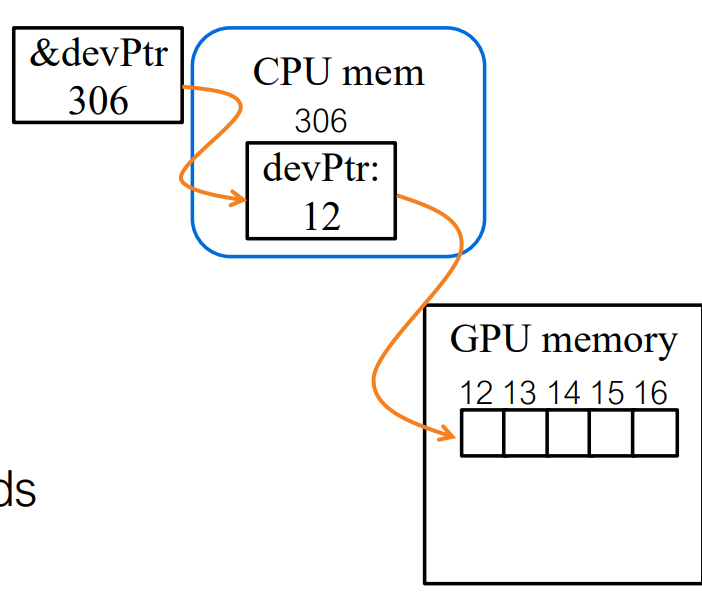
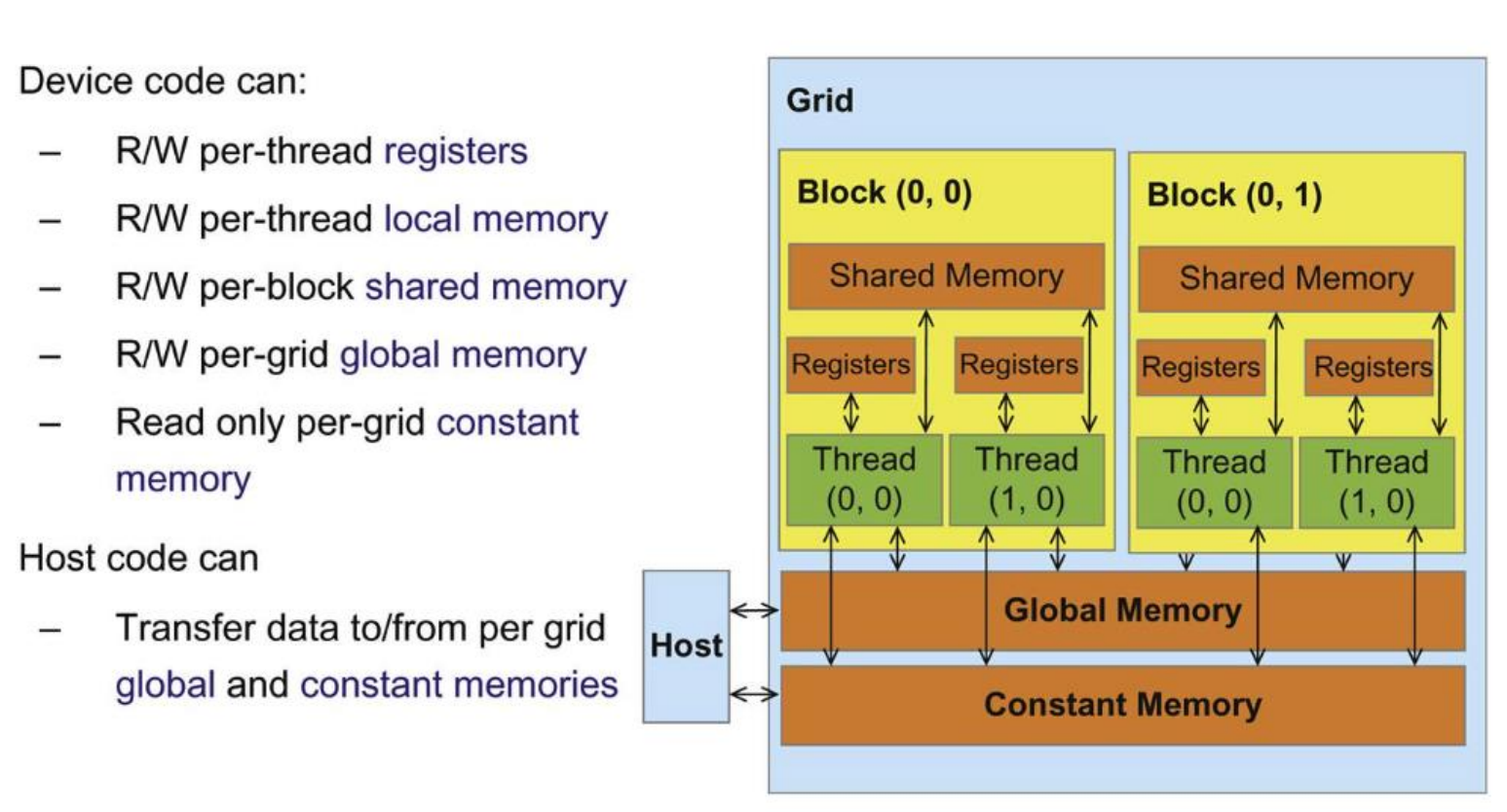
GPU 内存
CUDA 提供了一个分层内存模型。每个线程都有 私有寄存器,这是访问速度最快的内存。
同一 线程块 内的线程可以通过
共享内存 进行通信,使用 __shared__
显式声明,延迟远低于全局内存。
相比之下,全局内存 可被所有线程访问,并在内核启动之间持续存在,但访问延迟最高。
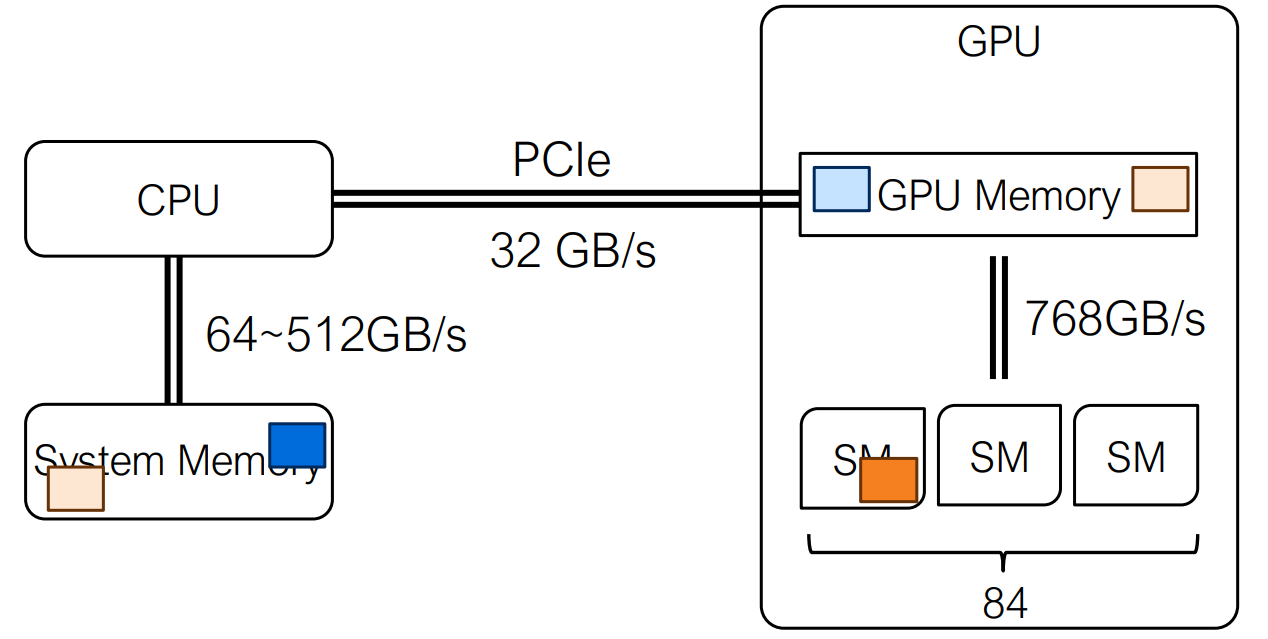
数据移动
CPU 和 GPU 之间的数据移动由程序员使用 cudaMemcpy
显式管理。内存可以 从主机到设备 或
从设备到主机 复制,传输大小以字节为单位指定。由于
CPU-GPU 数据传输相对昂贵,性能关键的应用程序旨在最小化此类传输并最大化
GPU 上的数据重用。

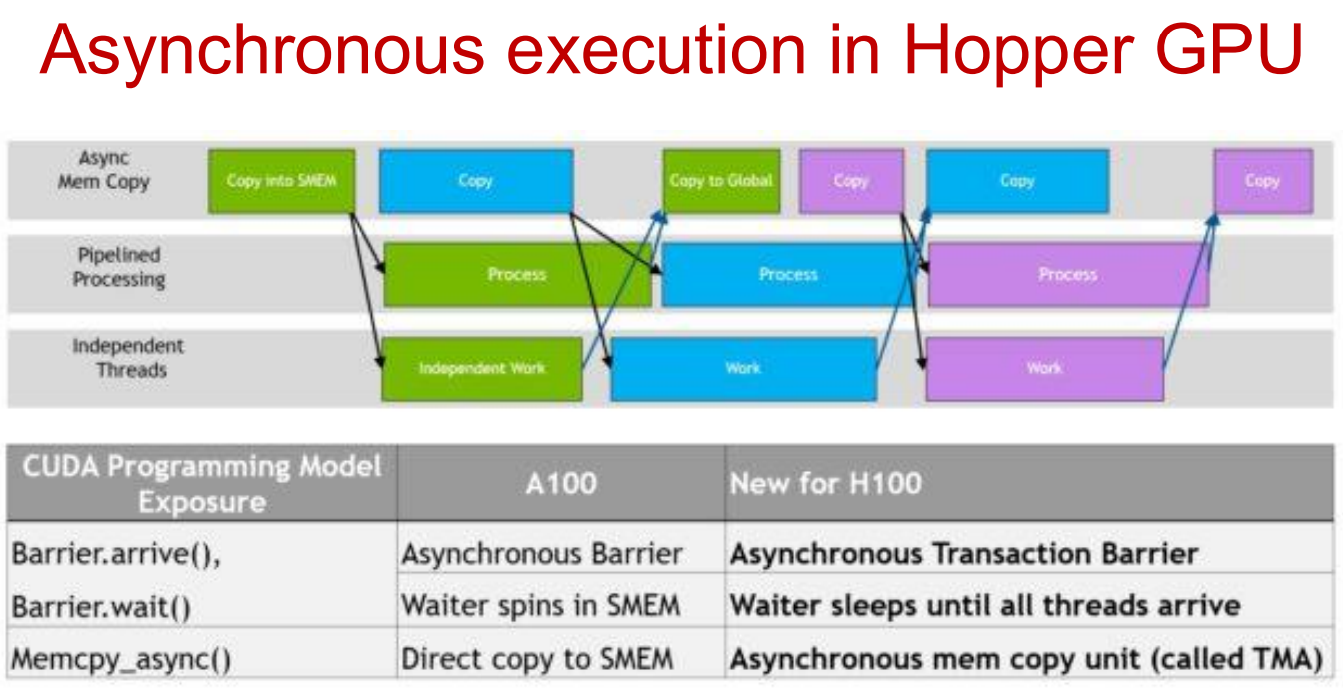
在每个流式多处理器(SM)上,指令通过每个周期有限数量的 发射槽 发给执行单元。发射槽表示在给定周期从 warp 发出指令的硬件能力,因此直接限制了 SM 上的指令吞吐量。
在预 Hopper 架构(例如,A100)中,等待内存操作的 warp——例如 异步复制到共享内存——仍然参与调度。即使一个 warp 在障碍上停滞,它也会反复检查准备情况,占用发射槽并降低整体 SM 利用率。
Hopper 在这个执行模型中引入了一个关键变化。通过 张量内存加速器(TMA),内存传输被卸载到专用硬件单元,等待复制完成的 warp 被置于 睡眠状态。睡眠中的 warp 从调度器的活动集中移除,不再消耗发射槽。因此,发射槽专门用于准备好执行计算的 warp,从而实现更高的指令吞吐量和更有效的内存移动与计算之间的重叠。
主机/设备函数的声明
| 关键字 | 调用在 | 执行在 | 用途 |
|---|---|---|---|
__global__ |
主机(CPU) | 设备(GPU) | GPU 内核 |
__device__ |
设备 | 设备 | GPU 函数 |
__host__ |
主机 | 主机 | 普通 CPU 函数 |
CUDA 使用显式限定符区分主机和设备函数。__global__
函数定义一个 GPU 内核,从 CPU 启动,但由 GPU
上的许多线程并行执行。每个线程运行相同的内核代码,并使用其线程和块索引来确定处理的数据部分。
运行时调用内核
在 CUDA 中,内核的并行执行配置由 主机(CPU) 在运行时指定,而不是在编译时固定。当启动内核时,主机显式定义 网格-块-线程层次结构,这决定了将有多少 GPU 线程执行该内核。
内核使用特殊语法启动:
1 | kernelFunc<<<Dg, Db>>>(args); |
在这里,Dg(网格维度)和
Db(块维度)可以指定为整数或 dim3 对象:
1 | dim3 Dg(4, 2, 1); |
Dg定义 网格的大小,即线程块的数量。Db定义 每个块的大小,即每个块的线程数量。
块的总数为 Dg.x * Dg.y * Dg.z,每个块的线程总数为
Db.x * Db.y * Db.z,在当前 NVIDIA GPU 上不得超过 1024。
设备运行时变量
一旦内核被启动,每个在 GPU 上执行的线程必须能够识别 它属于哪个块以及它在该块内的线程编号。CUDA 提供了一组内置的设备侧变量来实现这一点,这些变量由编译器自动生成。
这些变量包括:
gridDim(dim3): 网格的维度blockIdx(uint3): 当前块在网格中的索引blockDim(dim3): 块的维度threadIdx(uint3): 当前线程在块内的索引
所有内核线程执行相同的代码,但通过使用这些变量,每个线程可以计算出一个唯一的全局索引。一个常见的模式是:
1 | int i = blockIdx.x * blockDim.x + threadIdx.x; |
这使得线程能够自然地映射到存储在全局内存中的数组或其他数据结构的元素。
从 CPU 调用 CUDA 内核
在实践中,主机通常根据输入问题的大小计算网格和块的大小。例如,在处理长度为
n
的向量时,常见的方法是选择固定数量的线程每个块,并使用向上取整的整数除法计算所需的块数:
1 | int n = 1024; |
当这个启动发生时:
- CPU 使用指定的网格和块配置发出内核启动。
- GPU 创建块的网格并将其调度到可用的流式多处理器(SMs)上。
- 每个块进一步划分为 warp,线程并行执行内核代码。
- 每个线程使用
blockIdx、blockDim和threadIdx确定其操作的数据元素。
GPU 加速
内存访问效率
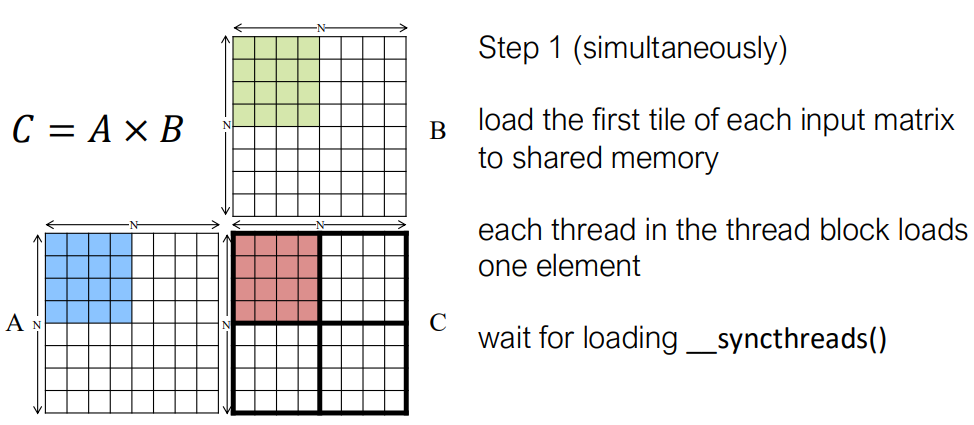
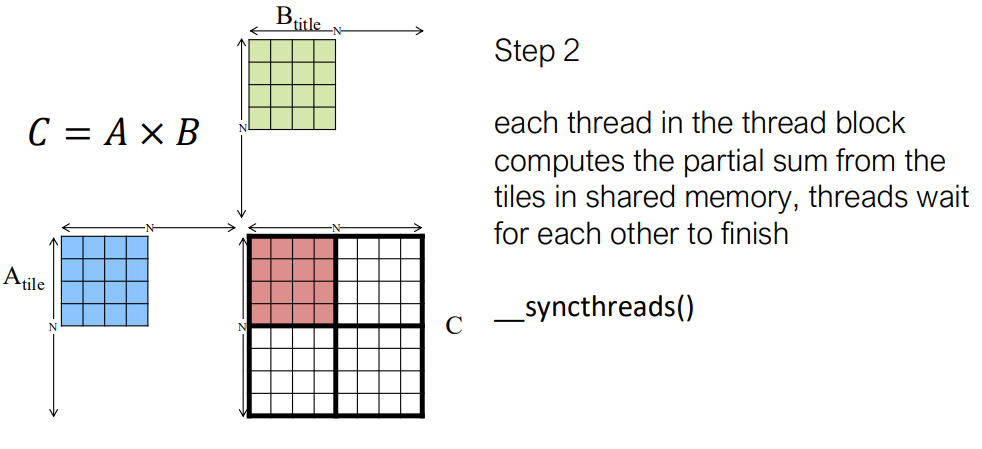
CUDA 设备内存模型

矩阵乘法的平铺
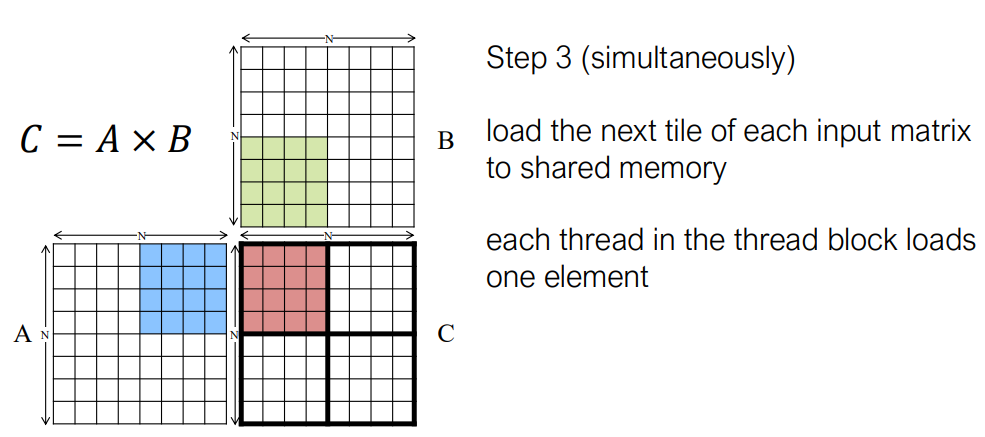
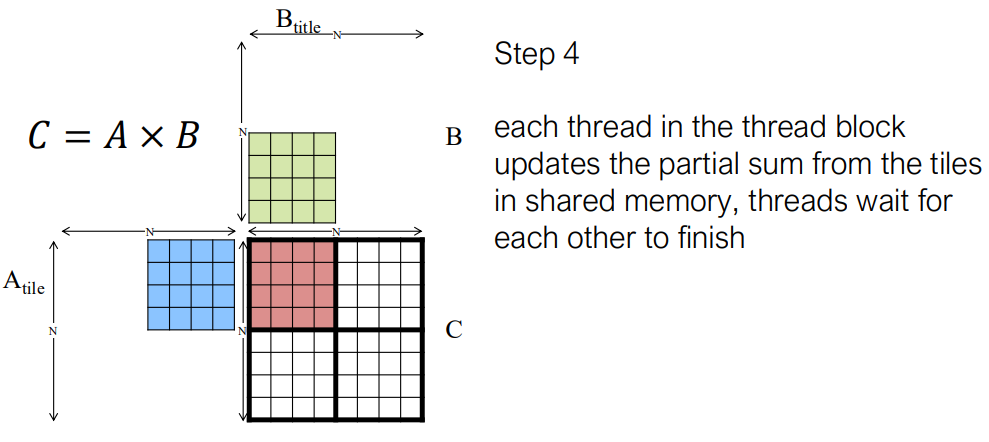
在 CUDA C++ 中的实现:
1 | __global__ void MatrixMultiplyKernel( |
GPU 上的矩阵转置:合并、共享内存和银行冲突
合并转置内核
1 | __global__ void smem_cuda_transpose(int m, float* a, float* c) { |
这解决了什么
✅ 全局内存读取被合并 ✅ 全局内存写入被合并
但是…
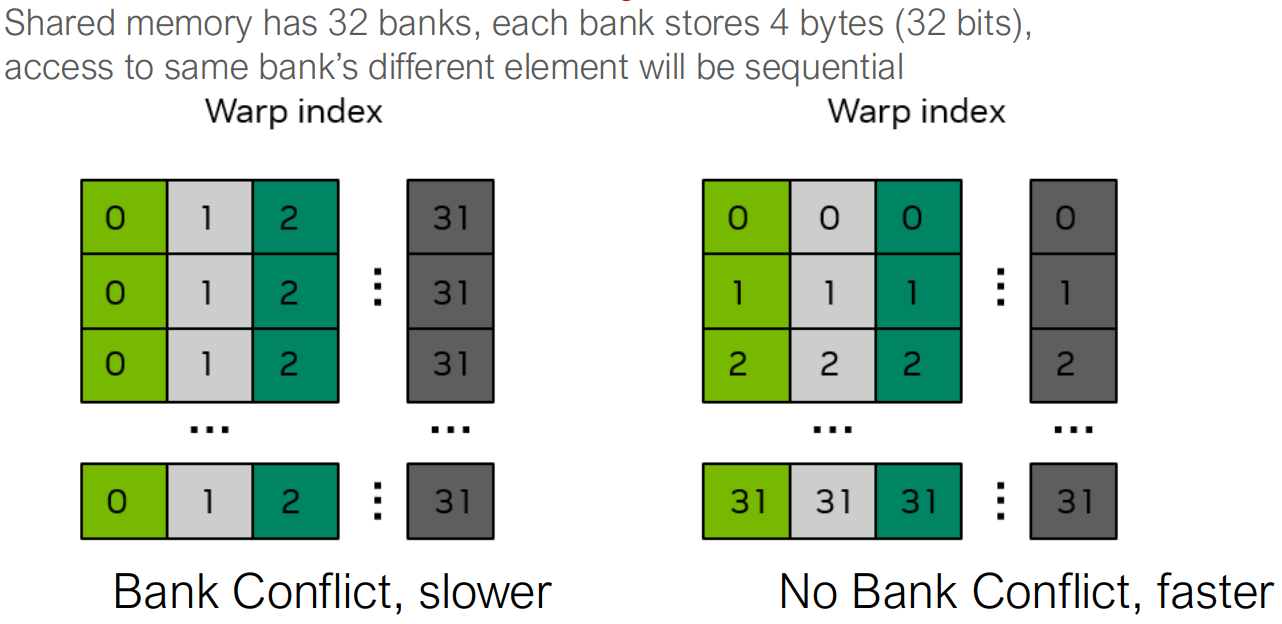
❌ 共享内存银行冲突出现
共享内存银行:真正的瓶颈
- 共享内存被划分为 32 个银行
- 每个银行每个周期提供 一个 32 位字
- 一个 warp 只能在 1 个周期 访问共享内存,前提是:
- 每个线程访问 不同的银行
smem[threadIdx.x][threadIdx.y]
这段代码实际上会导致银行冲突。
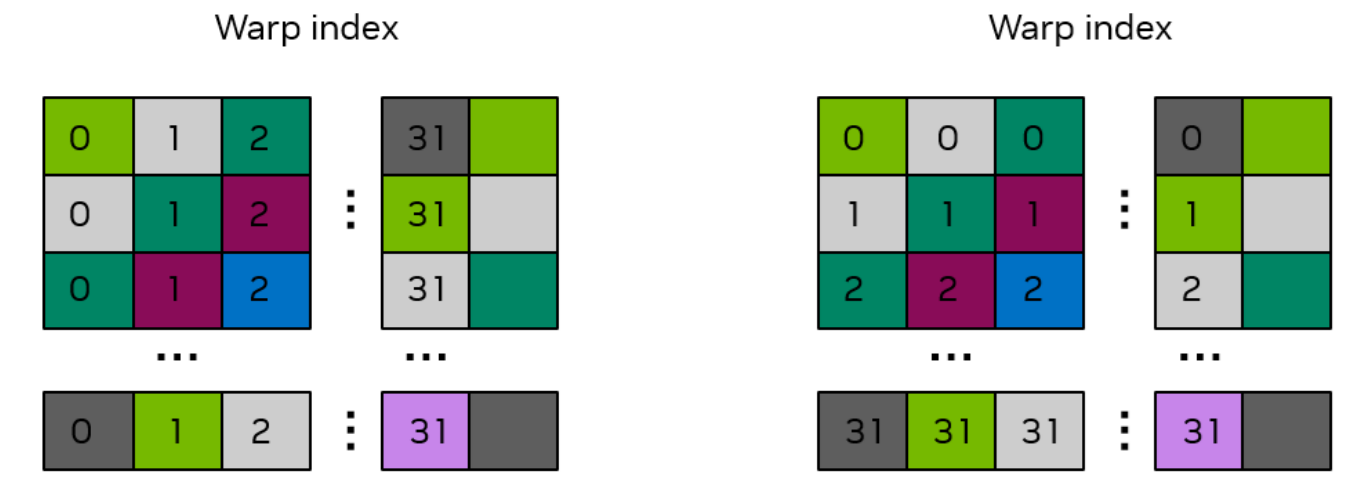
修复:填充共享内存
1 | __global__ void smem_cuda_transpose(int m, float* a, float* c) { |
稀疏矩阵乘法
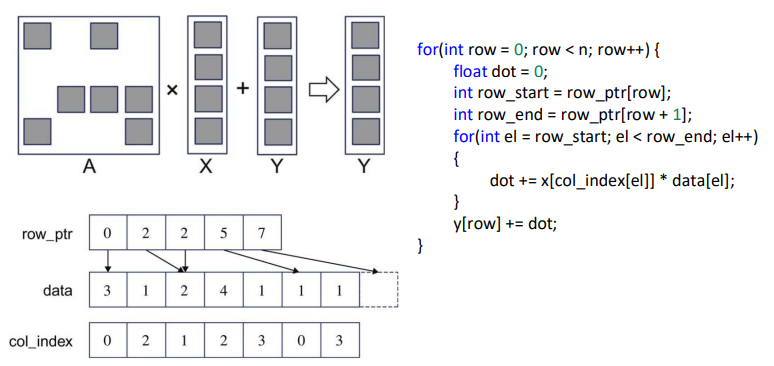
1 | __global__ void SpMVCSRKernel( |
cuBLAS
cuBLAS 代表 CUDA 基本线性代数子程序。
它是 NVIDIA 高度优化的 GPU 实现经典 BLAS 接口,针对以下操作:
- 向量操作(第 1 级 BLAS)
- 矩阵-向量操作(第 2 级 BLAS)
- 矩阵-矩阵操作(第 3 级 BLAS,特别是 GEMM)
编程模型
cuBLAS 使用 基于句柄的 API:
1 | cublasHandle_t handle; |
所有 cuBLAS 操作都需要一个有效的
cublasHandle_t,它存储执行上下文,例如 CUDA
流和数学模式。
第 1 级 BLAS:向量点积
计算两个向量的点积: \[ \text{result} = x^T y \]
1 | cublasStatus_t cublasSdot( |
关键点:
n是元素的数量incx、incy指定元素之间的步幅x和y必须位于 设备内存 中result写入 主机内存
这是范数、投影和归约的基本构建块。
第 2 级 BLAS:矩阵-向量乘法
计算: \[ y = \alpha A x + \beta y \]
1 | cublasStatus_t cublasSgemv( |
关键点:
A是一个 \(m \times n\) 矩阵,以 列优先 顺序存储trans控制A是否转置lda是A的主维度- 所有向量和矩阵都在 设备内存 中
此操作在迭代求解器和神经网络层中很常见。
第 3 级 BLAS:矩阵-矩阵乘法(GEMM)
计算: \[ C = \alpha A B + \beta C \]
1 | cublasStatus_t cublasSgemm( |
关键点:
- 这是 最重要的 cuBLAS API
A、B、C都以 列优先 布局存储m、n、k定义矩阵形状- 内部使用 平铺、共享内存和张量核心(如果可用)
GEMM 是深度学习和科学计算的性能支柱。

