
15618 Assignment 1 Report
15618 作业 1 探索多核和 SIMD 并行性报告
问题 1:使用 Pthreads 的并行分形生成
1.1 加速图
实现: 使用水平条带(空间分解)的多线程 Mandelbrot 生成。每个线程 处理连续的行。对于行数(900)不能被线程数整除的情况,前 (900 % T) 个线程被 分配一行额外的行 以确保所有行都被处理。

注意:16 个线程通过超线程技术使用相同的 8 个物理核心。
加速并不是线性的。 在 8 个核心下,我们仅实现了 3.97× 的加速(49.6% 的效率),而不是理想的 8×。
假设:负载不平衡:
水平条带策略造成了严重的负载不平衡,因为:
- 顶部/底部行:远离 Mandelbrot 边界的点快速发散(约 10-50 次迭代)
- 中间行:靠近边界的点需要最大迭代次数(256)
- 结果:分配给中间行的线程工作时间显著更长
由于总时间等于最慢线程的时间,不平衡的工作显著降低了加速。
关键观察:
从 2 个线程(98%)到 4 个线程(60%)的效率急剧下降,确认负载不平衡是主要的性能瓶颈,而不是硬件限制。
1.2 每线程计时测量
为了验证第 1.1 节的负载不平衡假设,我在 workerThreadStart() 的开始和结束处添加了计时测量,使用 CycleTimer::currentSeconds()。
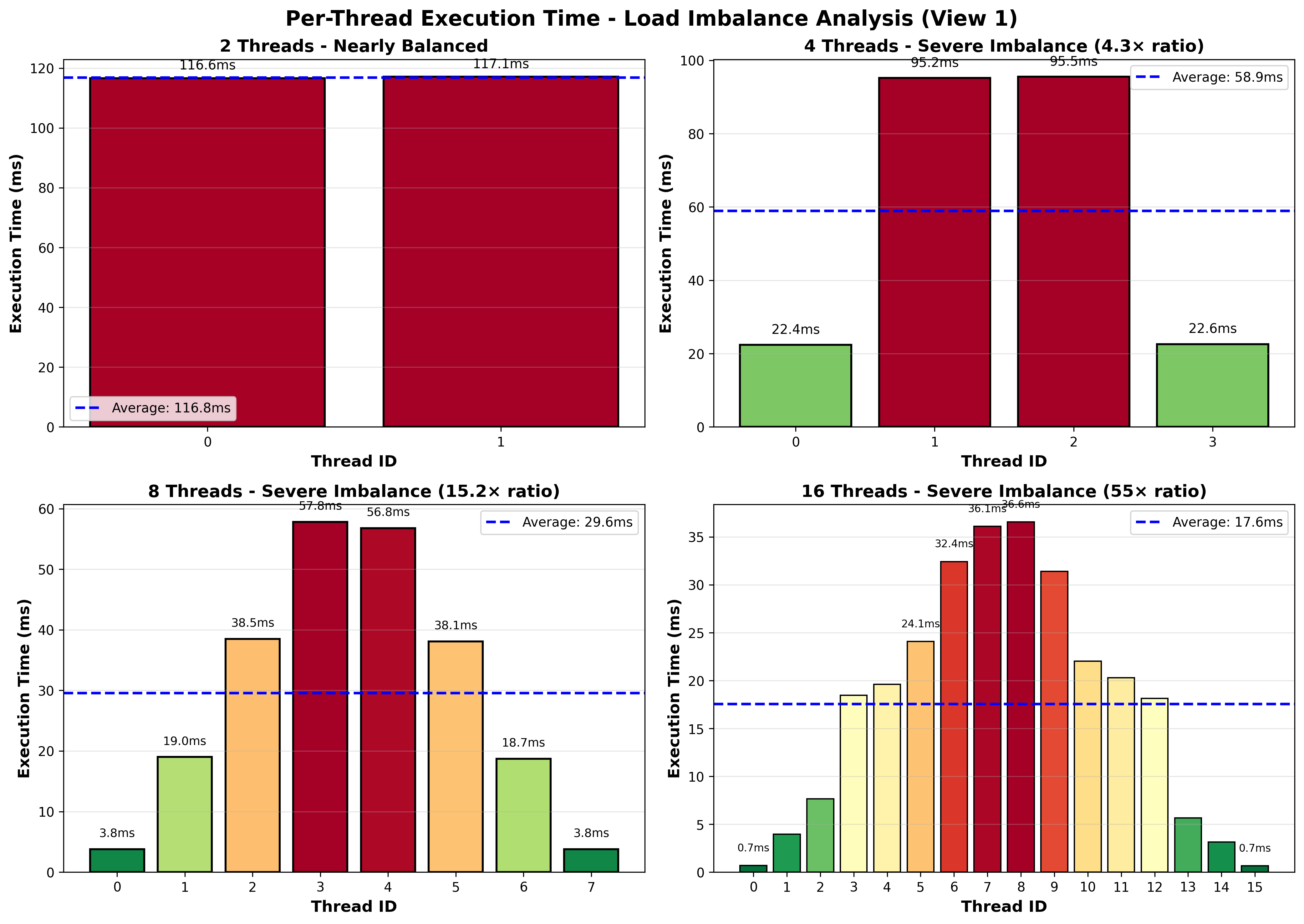
分析:负载不平衡确认
计时可视化清楚地显示了 严重的负载不平衡。颜色渐变揭示了问题:处理顶部和底部行的线程(绿色条)快速完成,而处理中间行的线程(红色条)则需要显著更长的时间。这个模式直接对应于 Mandelbrot 集的计算结构——边界区域需要最大迭代次数,而外部区域快速发散。
对于 4 个线程,这种不平衡意味着两个线程在大部分执行时间内处于空闲状态,而另外两个线程继续工作,浪费了一半的可用 CPU 能力。使用 8 个线程时,问题更严重:大多数线程早早完成并等待少数几个处理昂贵边界行的线程。这种不均匀分布解释了为什么我们在 8 个核心下仅实现了 3.97× 的加速,而不是理想的 8×——执行时间被最慢线程所瓶颈,而不是平均工作负载。
1.3 提高加速
策略:交错行分配
我实现了交错分配,而不是水平条带(每个线程处理连续行),其中线程 i 处理行 i, i+T, i+2T, i+3T, …,其中 T 是线程总数。
这种简单的静态分配确保每个线程处理一组计算上便宜的行(图像顶部/底部)和昂贵的行(靠近 Mandelbrot 边界),自动平衡工作负载而无需任何同步。
| 线程数 | 视图 1 加速 | 视图 2 加速 |
|---|---|---|
| 4 | 3.84× | 3.82× |
| 8 | 7.56× | 7.53× |
| 16 | 7.61× | 7.35× |
扩展行为分析:
4→8 线程(4→8 核心): 加速几乎翻倍,展示了出色的扩展性,因为每个额外的线程都在一个专用的物理核心上运行,拥有完整的计算资源。
8→16 线程(8 核心与超线程): 性能提升有限甚至下降(视图 2)。由于这两种配置共享相同的 8 个物理核心,16 个线程在执行单元和缓存上通过超线程竞争。对于计算密集型的 Mandelbrot 工作负载,内存停顿最小,超线程几乎没有好处。
问题 2:使用 SIMD 内在向量化代码
2.1 clampedExpVector
实现遵循平方取幂算法,并每个向量指令并行处理 W 个元素。
关键实现细节:
- 循环结构:以 VECTOR_WIDTH 为单位处理数组,每次迭代处理一个元素向量
- 掩码管理:使用 maskActive 跟踪哪些通道的指数仍大于 0,当所有通道完成时终止循环
- 边界处理:使用 _cmu418_init_ones(count) 动态创建掩码,以正确处理 N 不是 W 的倍数的情况
- 结果限制:向量化限制逻辑,以限制超过 4.18 的结果
正确性:通过了所有测试用例,包括非对齐数组大小(例如,N=3,N=10,N=100)
2.2 向量宽度扫频实验
实验设置:运行 ./vrun -s 10000,VECTOR_WIDTH ∈ {2, 4, 8, 16, 32}
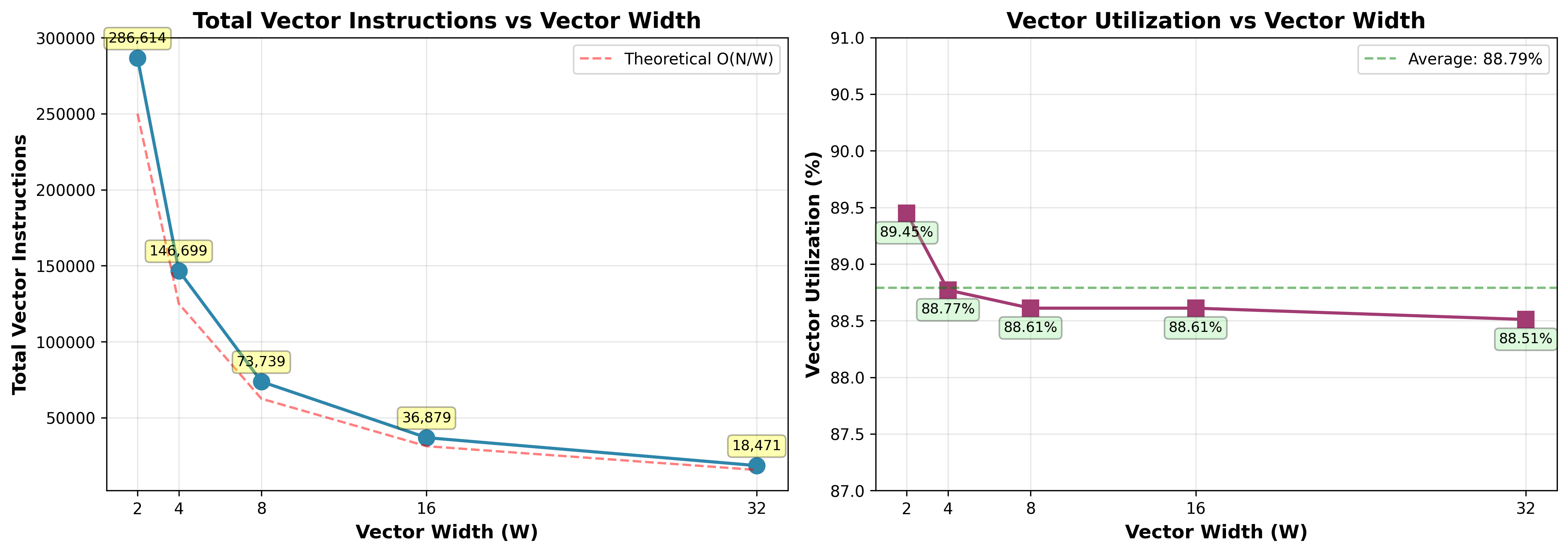
向量利用率分析
观察:在所有向量宽度下,向量利用率保持高水平(88.51%-89.45%),随着 W 从 2 增加到 32,仅 下降 0.94%。这表明 对向量宽度的低敏感性。
这是因为迭代次数与 log₂(指数) 成正比,这意味着指数之间的 10 倍差异(例如,100 与 1000)仅导致 ~3 次额外迭代。由于向量指令必须 等待最慢的通道完成,每个向量的迭代次数由最大迭代次数的元素决定。这种低方差 确保向量内的元素在相似时间内完成,最小化空闲通道,无论向量宽度如何。
向量指令数量分析
观察:总向量指令从 286,614(W=2)减少到 18,471(W=32),每次向量宽度翻倍大约减半。测得的指令数量紧密跟随理论 O(N/W) 曲线(红色虚线),确认接近理想扩展。
总指令数量 由外循环运行的次数决定。当向量宽度翻倍(例如,W=4 到 W=8)时,每个向量指令可以处理更多元素,因此外循环只需运行一半的次数。由于每次循环迭代内部的工作保持不变,翻倍 W 直接减半总指令。这种 93.6% 的减少 从 W=2 到 W=32 证明了向量化提供了预期的线性加速。
2.3 arraySumVector
实现了一个树归约算法,达到 O(N/W + log₂W) 的跨度复杂度:
算法:
- 第一阶段 - 向量累加(O(N/W)):使用向量加法将所有数组元素相加到一个单一的向量寄存器中
- 第二阶段 - 树归约(O(log₂W)):在 log₂W 轮中使用 hadd 和交错操作将 W 个元素归约为一个标量
正确性:通过了 W = 2, 4, 8, 16 的所有测试。
问题 3:使用 ISPC 的并行分形生成
3.1 第 1 部分:ISPC SIMD 并行化分析

8x 理论最大加速
ISPC 编译器配置为发出 8 路 AVX2 SIMD 指令,可以 同时处理 8 个浮点值。因此,理论最大加速为 8x,与串行实现相比。
SIMD 分歧(停顿)
观察到的平均加速为 4.48x,仅为理论 8x 最大值的 56%,因为 不同像素需要不同数量的迭代 来确定它们是否在 Mandelbrot 集中——在 SIMD 中同时处理 8 个像素时,有些快速完成,而其他则需要更长时间,迫使 所有通道等待最慢的一个,这浪费了空闲通道的计算。
不同视图的性能变化
不同视图的加速范围从 4.01x 到 4.88x(视图 6:最佳 4.88x,视图 5:最差 4.01x)。具有 复杂分形边界的视图 其相邻像素的迭代次数差异很大,导致更多 SIMD 通道处于空闲状态,而具有 平滑区域的视图 其像素在相似时间内完成,从而减少了浪费的计算。
3.2 第 2 部分:ISPC 任务
使用 –tasks 的加速
| 实现 | 时间 (ms) | 与串行的加速 | 与 ISPC 的加速 |
|---|---|---|---|
| 串行 | 176.369 | 1.00x | - |
| ISPC(仅 SIMD) | 37.019 | 4.76x | 1.00x |
| ISPC + 任务(2 个任务) | 18.721 | 9.42x | 1.98x |
来自任务的 2 倍提升是合理的,因为当前实现仅创建 2 个任务,仅利用了 8 个核心中的 2 个。通过增加任务数量,性能可以显著提高。
找到最佳任务数量
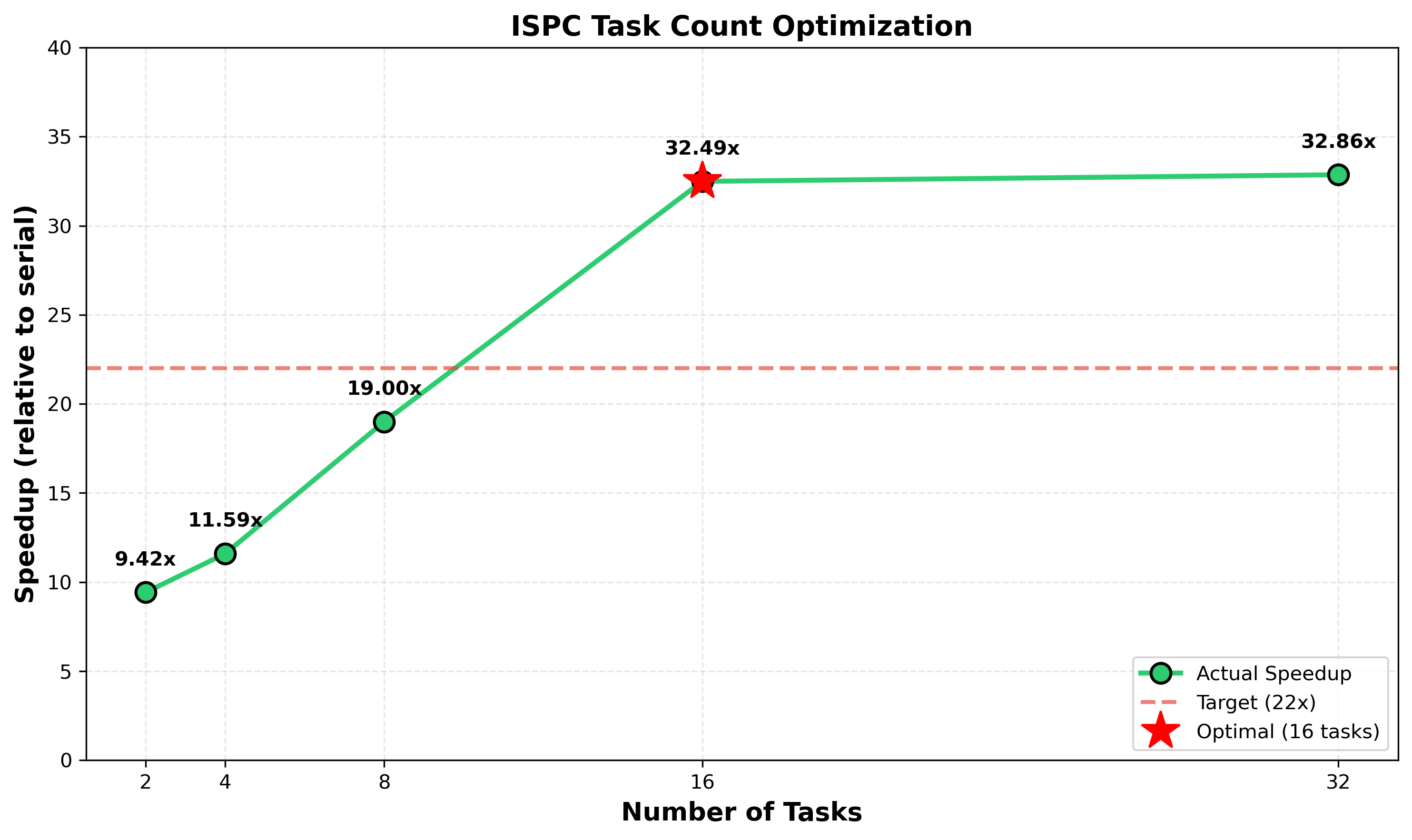
最佳任务数量为 16
系统有 8 个物理核心,支持超线程,允许 16 个硬件线程 同时运行。使用 16 个任务实现最佳性能(32.49× 加速),原因如下:
- 匹配硬件容量:16 个任务充分利用所有 16 个硬件线程,使所有执行单元保持忙碌。
- 更好的负载平衡:Mandelbrot 计算的工作负载不均匀——分形边界需要比实心区域多得多的迭代。仅使用 2 个任务时,一个任务可能会在重负载区域卡住,而另一个则早早完成。使用 16 个较小的任务,工作在核心之间分配得更均匀。
- 超过 16 的收益递减:使用 32 个任务(32.86×)相较于 16 个任务的提升有限,因为任务调度开销增加,而负载平衡的好处趋于平稳。
Pthread 与 ISPC 任务的对比
Pthreads 是操作系统级线程,开销较大。启动 10,000 个线程可能会由于过多的内存消耗和上下文切换而崩溃或严重减慢系统。
相比之下,ISPC 任务是轻量级的逻辑单元。运行时将它们映射到一个小的固定线程池(通常与 CPU 核心数量相匹配)。启动 10,000 个任务是高效的,因为它们通过任务队列进行调度。
关键区别是 Pthreads 适用于粗粒度并行(任务少,开销高),而 ISPC 任务使得细粒度数据并行(任务多,开销低)。这使得 ISPC 非常适合像像素级处理这样的 SPMD 风格操作。
问题 4:迭代平方根
4.1 加速
1 | 串行:682.707 ms |
4.2 initGood
实现: 将所有值设置为 2.999f
1 | 串行:1698.132 ms |
这个选择通过以下方式最大化加速:
完美的 SIMD 效率:所有元素 在相同的迭代中收敛,消除了通道分歧。每个 SIMD 通道执行相同的工作量,并且 同时完成,没有空闲等待。 SIMD 加速 从 4.69x(随机)提高到 5.71x。
超线程下的最大多核收益:均匀的重负载使得多核扩展表现出色。多核加速达到 8.76x,超过基线 7.25x。这证明了作业中提到的 超线程效应——当所有线程执行相同的重负载时,超线程可以提供超出物理核心数量的额外性能。
4.3 initBad
实现: 每 8 个元素交替使用 2.999f 和
1.0f
1 | 串行:234.384 ms |
值的选择:2.999f 需要更多的迭代,而
1.0f 需要 ~0 次迭代(与初始猜测相符)。这在每个 SIMD
幫中造成了最大迭代次数的分歧。
SIMD 性能:这种模式在每个 SIMD 向量内造成了 最大工作分歧(帮大小 = 8),每个向量有 1 个慢元素和 7 个快元素。SIMD 在锁步操作中,所有通道必须等待最慢的通道,性能低于串行执行(0.79x)。
多核性能:多核加速 仍然非常高,达到 8.77x,与 initGood(8.76x)几乎相同。该模式在数组中均匀重复(每第 8 个元素是慢的),确保 尽管单个向量内存在严重的 SIMD 效率低下,但线程之间的工作负载分配仍然均衡。
问题 5:BLAS saxpy
5.1 saxpy 性能分析
| 版本 | 时间 (ms) | 带宽 (GB/s) | 性能 (GFLOPS) | 加速 |
|---|---|---|---|---|
| 串行 | 11.356 | 26.243 | 1.761 | 1.00x |
| 流式 | 11.242 | 26.509 | 1.779 | 1.01x |
| ISPC | 11.315 | 26.339 | 1.768 | 1.00x |
| 任务 ISPC | 11.133 | 26.768 | 1.796 | 1.02x |
工作负载是 受内存带宽限制。Saxpy 访问大量数据,但仅执行 2 次浮点运算。处理器在等待内存时花费的时间远远超过计算时间。尽管 saxpy 可以轻松并行化,ISPC 和多核执行提供的加速仅约为 1.00x。所有实现的带宽约为 26-27 GB/s,表明我们已经 达到了内存带宽限制。
该程序无法通过并行化单独显著改善。 增加更多核心或 SIMD 通道在串行执行已经最大化内存带宽时并没有帮助。潜在的改进需要 减少内存流量(例如,使用非临时存储结果向量以避免缓存污染,将带宽从 4N 降低到 3N 个浮点数)或 升级到更高带宽的内存硬件。
5.2 额外学分:为什么是 4N 而不是 3N?
我认为这是因为缓存的行为。现代 CPU 使用写分配缓存策略,这意味着写操作必须首先将目标数据加载到缓存中,然后才能修改。这是为了确保缓存一致性和局部性优化。因此,额外的 N 个浮点数是 读取结果缓存行。
5.3 额外学分:还有哪些因素可能影响?
观察到的 26-27 GB/s 带宽代表了 DDR4 内存系统的典型效率。观察到的带宽与理论峰值之间的差距是由于:
- DRAM 时序开销:DDR4 在操作之间需要强制延迟(CAS 延迟、行预充电时间、刷新周期),在此期间内存总线处于空闲状态。这些时序限制通常将有效带宽降低到理论峰值的 60-70%。
- 内存控制器效率:银行冲突、通道仲裁和内存控制器中的命令调度增加了额外的开销。
5.4 额外学分:非临时存储优化
实现: 使用 SSE 内在修改 saxpyStreaming(),使用
_mm_stream_ps 绕过缓存。
| 版本 | 时间 (ms) | 带宽 (GB/s) | 性能 (GFLOPS) | 加速 |
|---|---|---|---|---|
| 串行 | 11.124 | 26.791 | 1.798 | 1.00x |
| 流式 | 8.138 | 36.623 | 2.458 | 1.37x |
| ISPC | 11.201 | 26.608 | 1.786 | 0.99x |
| 任务 ISPC | 11.125 | 26.789 | 1.798 | 1.00x |
非临时存储将内存流量从 4N 降低到 3N 个浮点数,实现了 1.37x 的加速和带宽从 26.8 GB/s 提升到 36.6 GB/s。



