
15645 Database Systems Lecture Notes
Lec 1 关系模型
术语
数据库管理系统 (DBMS) 是一种软件,允许应用程序在数据库中存储和分析信息,并应支持根据某种数据模型定义、创建、查询、更新和管理数据库。
数据模型 是描述数据库中数据的概念集合。(例如,关系或文档)
模式 是使用给定数据模型描述特定数据集合的描述。(例如,表结构设计)
关系 是一个无序集合,包含表示实体的属性关系。(例如,表或容器)
元组 是关系中一组属性值(即其域)。(例如,表中的数据条目)
DBMS 可以通过身份列自动生成唯一主键:
IDENTITY (SQL 标准)
SEQUENCE (PostgreSQL / Oracle) 全局,其他与列绑定
AUTO_INCREMENT (MySQL)
关系代数

Lec 2 现代 SQL
SQL 基于袋(重复项,如多站点),而不是集合(无重复项)。
术语:
- 数据操作语言 (DML)
- 数据定义语言 (DDL)
- 数据控制语言 (DCL)
执行顺序:
1 | FROM / JOIN |
聚合
从一组元组中返回单个值的函数:
- AVG(col)→ 返回 col 的平均值。
- MIN(col)→ 返回 col 的最小值。
- MAX(col)→ 返回 col 的最大值。
- SUM(col)→ 返回 col 中值的总和。
- COUNT(col)→ 返回 col 的值的数量。
COUNT(*) 计算行数,COUNT(1) 每行计算一个常量值(永远不为 NULL),因此它们是等价的;只有 COUNT(column) 可能不同,因为它会忽略 NULL。
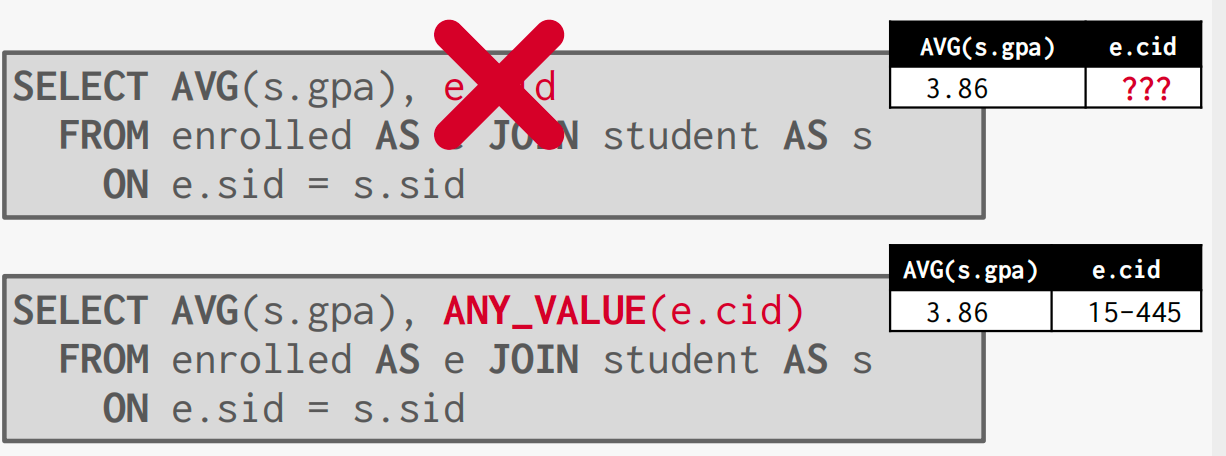
在上图中,AVG(s.gpa) 只有一个单一值,但 e.cid 可能有多个值,因此数据库不知道如何为该列选择一个值,我们应该使用 ANY_VALUE() 明确告诉数据库如何选择。
分组
将元组投影到子集,并对每个子集计算聚合。
分组在 FROM/JOIN/WHERE 之后,但在聚合函数之前发生。
分组集
在单个查询中指定多个分组,而不是使用 UNION ALL 来组合多个单独的 GROUP BY 查询的结果。
过滤
对结果进行资格认证 聚合计算前。聚合组成员资格资格。

HAVING
对结果进行过滤 聚合计算后。

这表明 HAVING 在 SELECT 之前发生,因此 avg_gpa 名称尚未生成。
字符串操作
- LIKE 提供带有特殊匹配运算符的字符串匹配:
- ‘%’ 匹配任何子字符串(包括空字符串)
- ’_’ 匹配任何一个字符
- SIMILAR TO 允许进行正则表达式匹配
- 在 SQL 标准中,但并非所有系统都支持
- 其他系统也支持 POSIX 风格的正则表达式
- SUBSTRING
- UPPER
- || : 连接两个或多个字符串(这也可以是 + 或 CONCAT() 函数)
日期/时间操作
日期/时间操作处理时间值,语法和行为因 DBMS 而异。
输出控制
输出控制子句决定查询返回的行的顺序和数量。
- ORDER BY: ORDER BY column [ASC | DESC] 按一个或多个列的值对元组进行排序
- FETCH: FETCH {FIRST|NEXT} <#> ROWS OFFSET
<#> ROWS
- 限制输出中返回的元组数量
- 可以设置偏移量以返回“范围”

输出重定向
将查询结果存储在另一个表中:
- 表必须尚未定义
- 表将具有与输入相同数量的列和相同类型

嵌套查询
在另一个查询中调用查询以组合更复杂的计算:
内部查询几乎可以出现在查询的任何地方
- ALL: 表达式必须对子查询中的所有行都为真。
- ANY: 表达式必须对子查询中的至少一行为真。
- IN: 等同于 ‘=ANY()’。
- EXISTS: 至少返回一行,而不与外部查询中的属性进行比较。
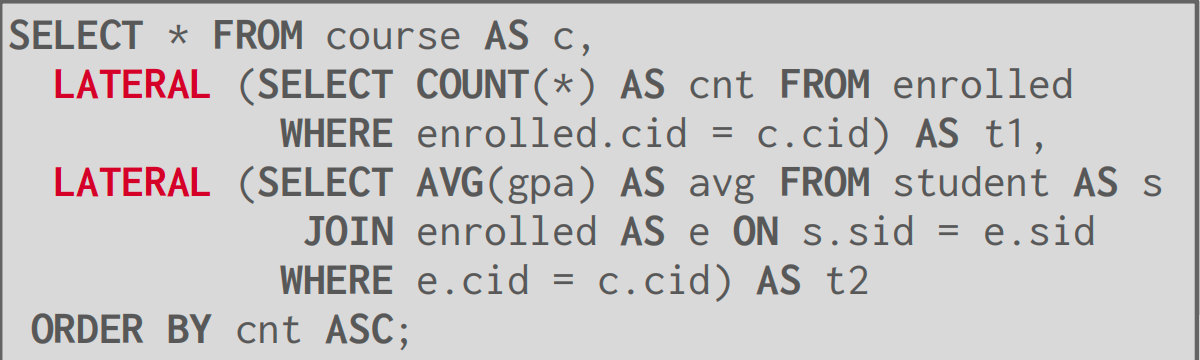
侧向连接
侧向运算符允许嵌套查询引用在其之前的其他嵌套查询中的属性(根据在查询中的位置)。
公共表表达式
指定一个临时结果集,然后可以在查询的其他部分引用该结果集。

窗口函数
在与当前元组相关的一组元组上执行计算,而不将它们合并为单个输出元组,以支持运行总计、排名和移动平均。
特殊窗口函数:
- ROW_NUMBER() 当前行的编号
- RANK() 当前行的排序位置
OVER 关键字指定在计算窗口函数时如何对元组进行分组。
使用 PARTITION BY 指定分组。

