
15618 Parallel Programming Lecture (1-4) Notes
[toc]
Lec 1 为什么并行性?为什么效率?
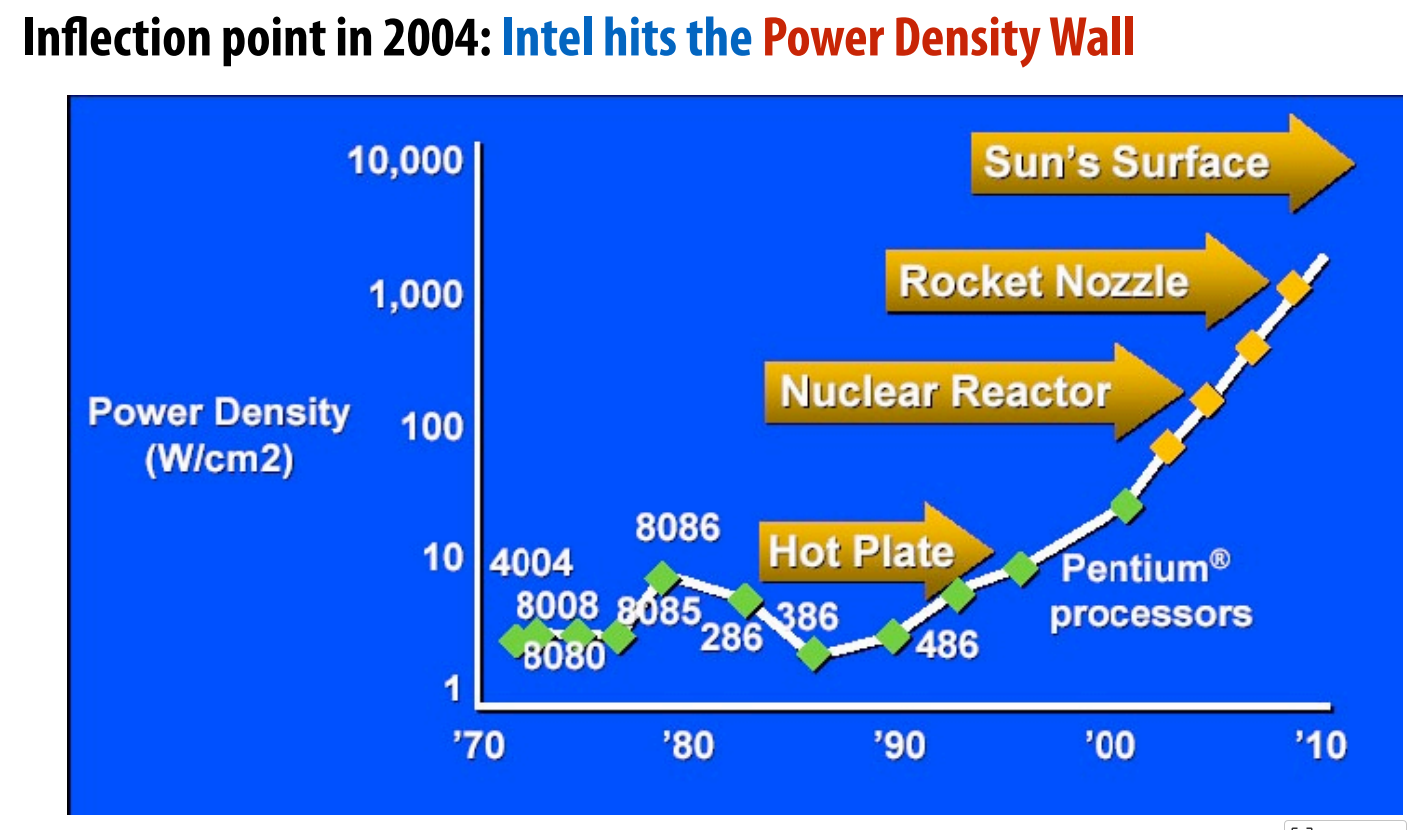
处理器性能的简要历史
更宽的数据通道(位宽)
更高效的流水线(3.5 指令周期(CPI)→ 1.1 CPI)
指令级并行性(ILP),例如 超标量 处理
更快的时钟频率(最重要),例如 10 MHz → 200 MHz → 3 GHz

什么是并行计算机?
一个常见的定义:
并行计算机是一个 处理元素的集合,它们 合作 以 快速解决问题。 \[ 加速比(使用\ P\ 处理器) = \frac{执行时间(使用\ 1\ 处理器)}{执行时间(使用\ P\ 处理器)} \] 关于加速比的一些观察:
- 通信限制了实现的最大加速比(可能 主导 并行计算)
- 最小化通信成本可以提高加速比
- 工作分配不均衡限制了加速比
- 改善工作分配可以提高加速比
CPU 设计哲学的转变
最大化 性能(ILP)→ 最大化 每单位面积的性能(每芯片的性能)→ 最大化 每瓦特的性能
总结:主要关注 核心的效率
Lec 2 现代多核处理器
并行执行
使用泰勒展开计算 sin(x):sin(x) = x - x³/3! + x⁵/5! - x⁷/7! + …
1 | void sinx(int N, int terms, float* x, float* result) |
提高程序效率的思路如下。
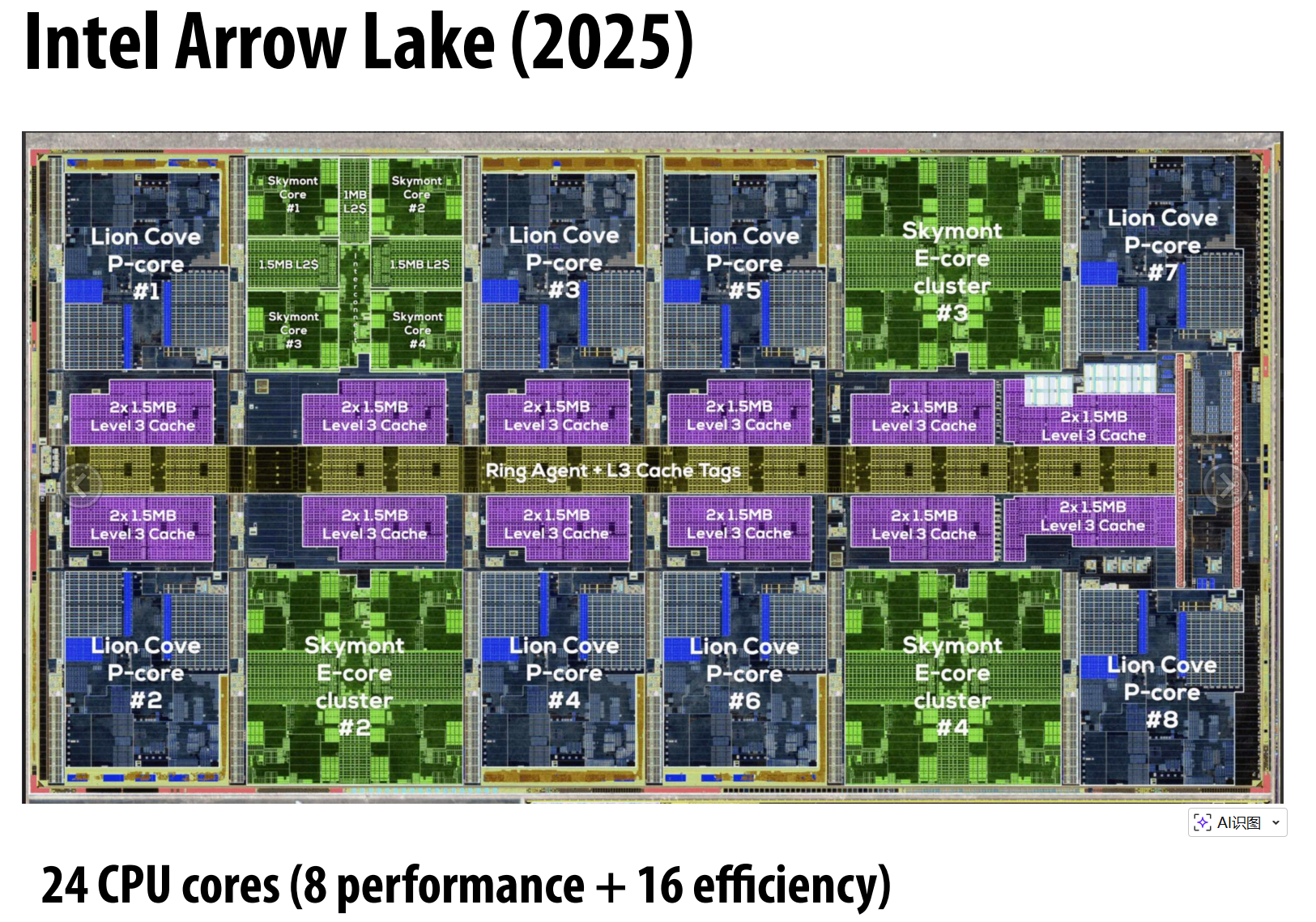
多核
利用不断增加的晶体管数量为处理器添加更多核心
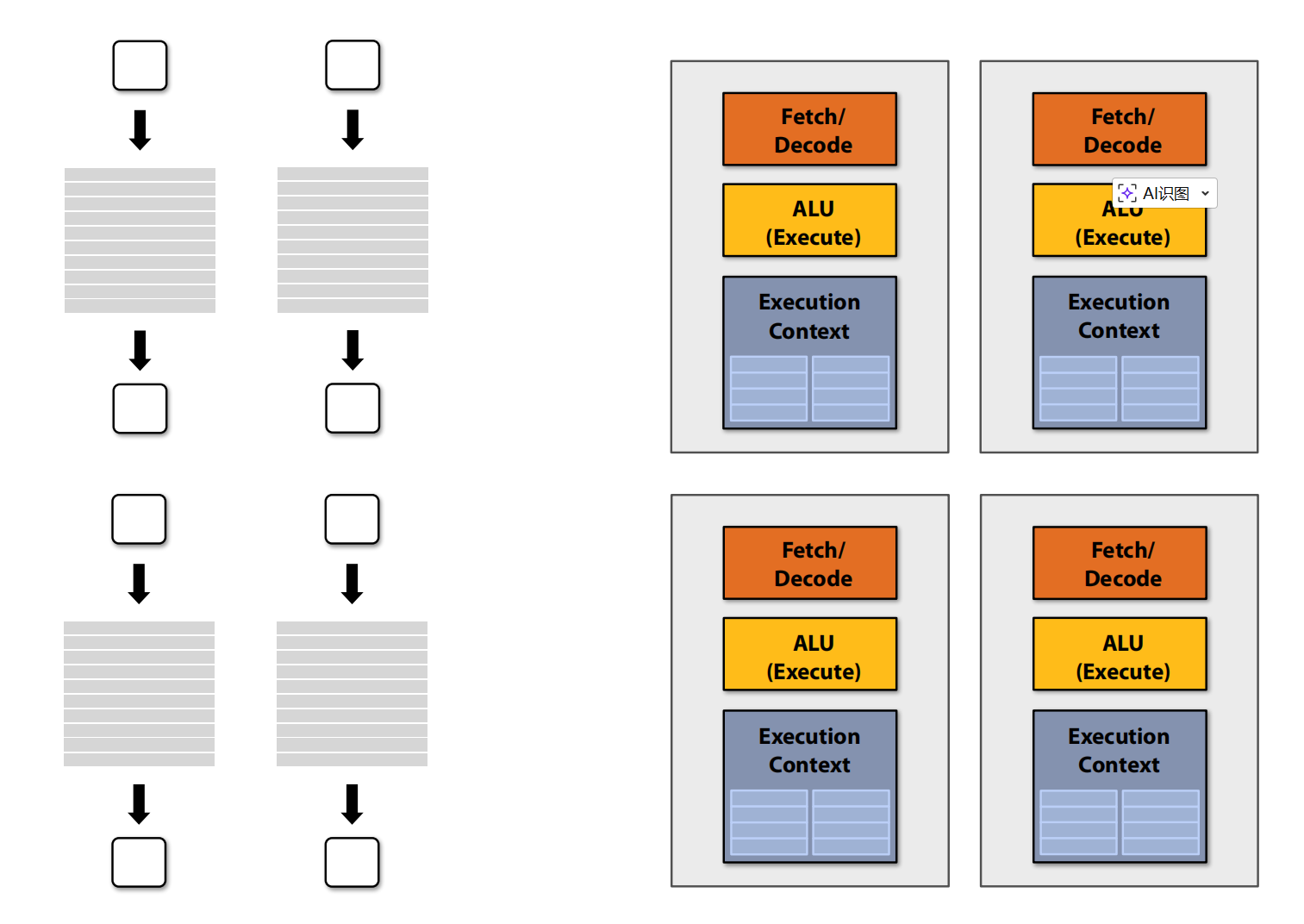
更多 ALU
在多个 ALU 上摊销管理指令流的成本/复杂性
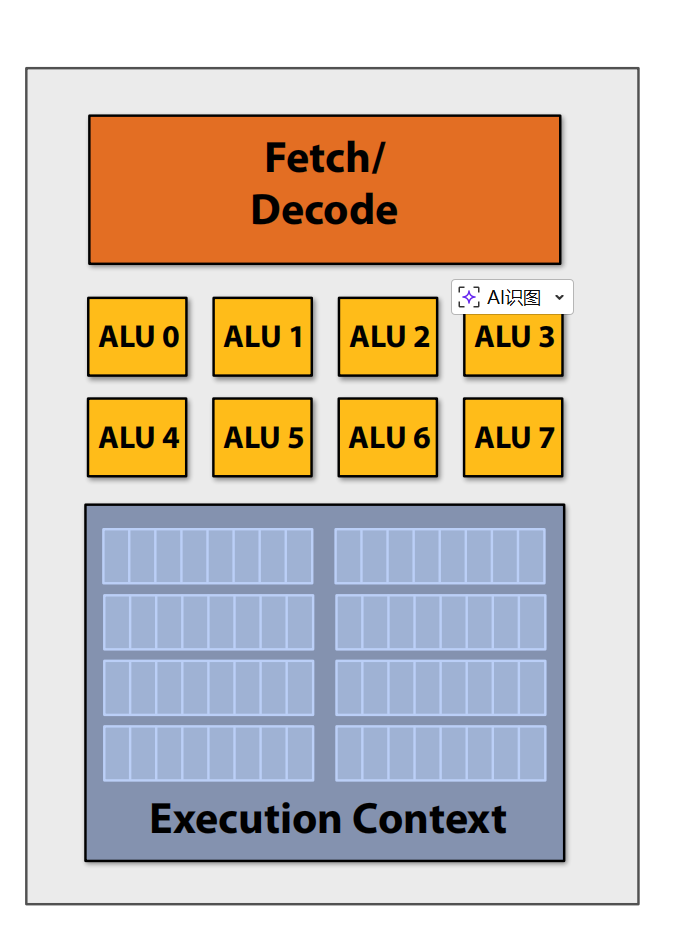
SIMD 处理(单指令,多数据):相同指令广播到所有 ALU,并在所有 ALU 上并行执行
标量程序与向量程序:标量:每个寄存器一个操作。向量:使用 SIMD 每个寄存器多个操作。
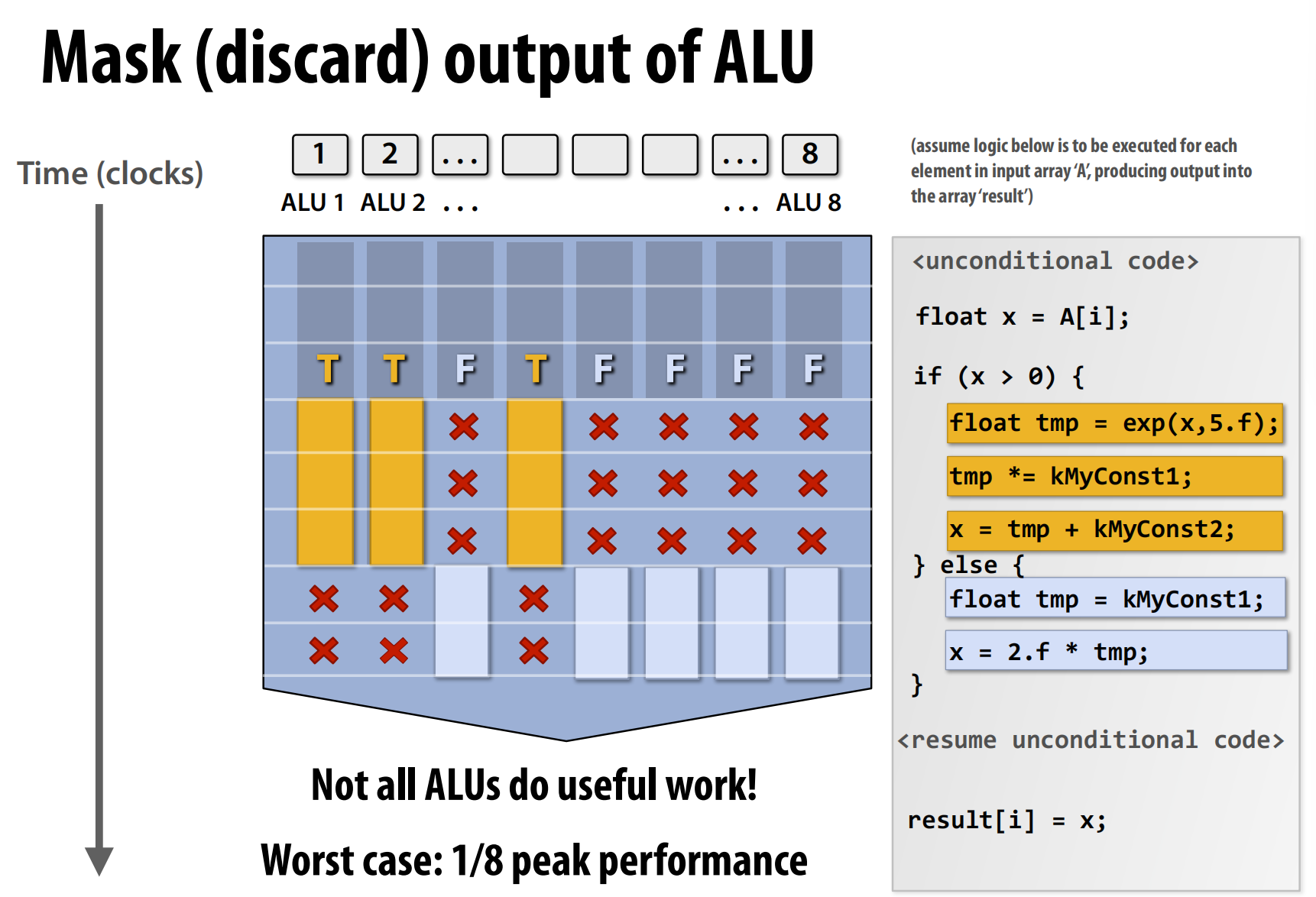
上图显示条件代码(if - else)可能会 降低 多 ALU 架构的效率。因为 同一处理器中只能同时执行一条指令,所以可能有一些 ALU 处于空闲状态,我们使用 掩码来丢弃某些 ALU 的输出。
SIMD 术语
指令流一致性与分歧执行
- 一致性执行:所有元素同时执行相同的指令序列(对 SIMD 高效)
- 分歧执行:不同元素需要不同的指令路径(对 SIMD 低效,例如 if-else 分支)
SSE 与 AVX
- SSE:128 位操作(4 宽浮点向量)
- AVX:256 位操作(8 宽浮点向量)
显式 SIMD 与隐式 SIMD
- 显式 SIMD:程序员显式编写 SIMD 代码,使用内建函数或并行结构;向量化在编译时完成
- 隐式 SIMD(自动向量化):编译器自动检测并将标量循环转换为 SIMD 指令
总结
多核
- 什么:多个核心同时执行不同线程
- 控制:程序员创建线程(例如 pthreads)
- 并行性:线程级并行性
SIMD
- 什么:单指令对多个数据元素操作
- 控制:编译器(显式 SIMD)或硬件(隐式)
- 并行性:数据级并行性
超标量
- 什么:同一线程的多条指令并行执行
- 控制:硬件在运行时自动发现并行性
- 并行性:指令级并行性(ILP)
- 注意:本课程未涵盖(属于架构课程,如 18-447)
访问内存
停顿
当处理器因依赖于先前指令而无法运行指令流中的下一条指令时,它会“停顿”。

减少停顿的方法:
预取:所有现代 CPU 都有将数据预取到缓存的逻辑

多线程:在同一核心上交错处理多个线程以隐藏停顿
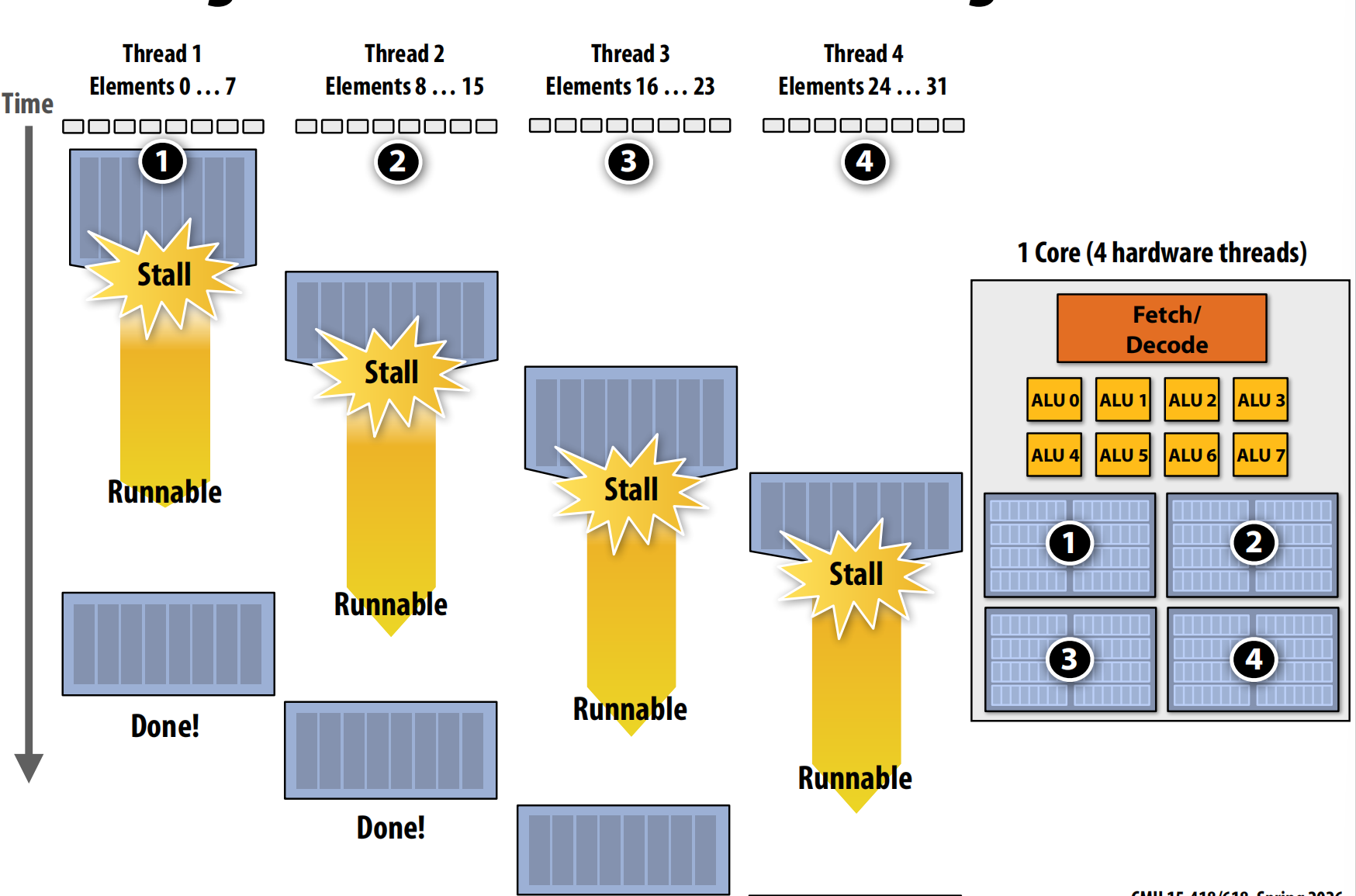
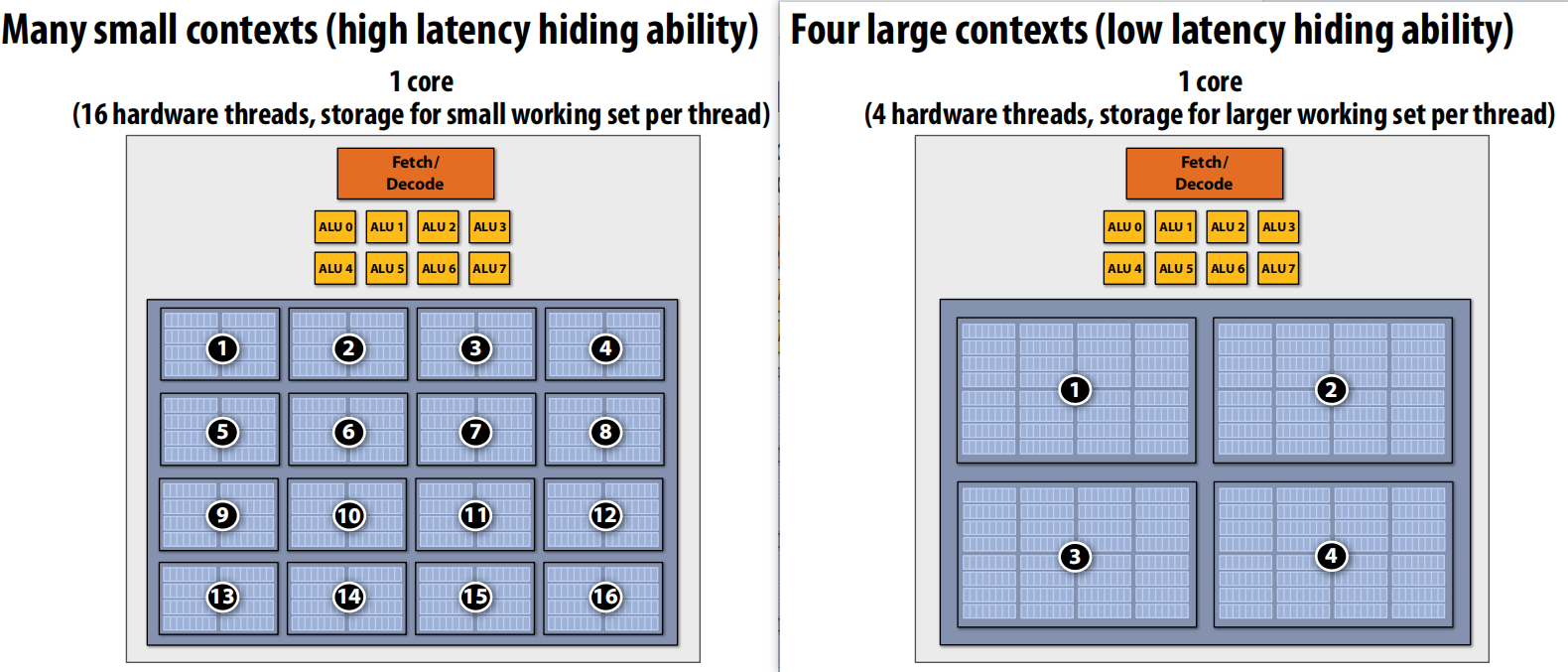
核心需要管理多个线程的执行上下文。以下是不同概念的计数方法示例。
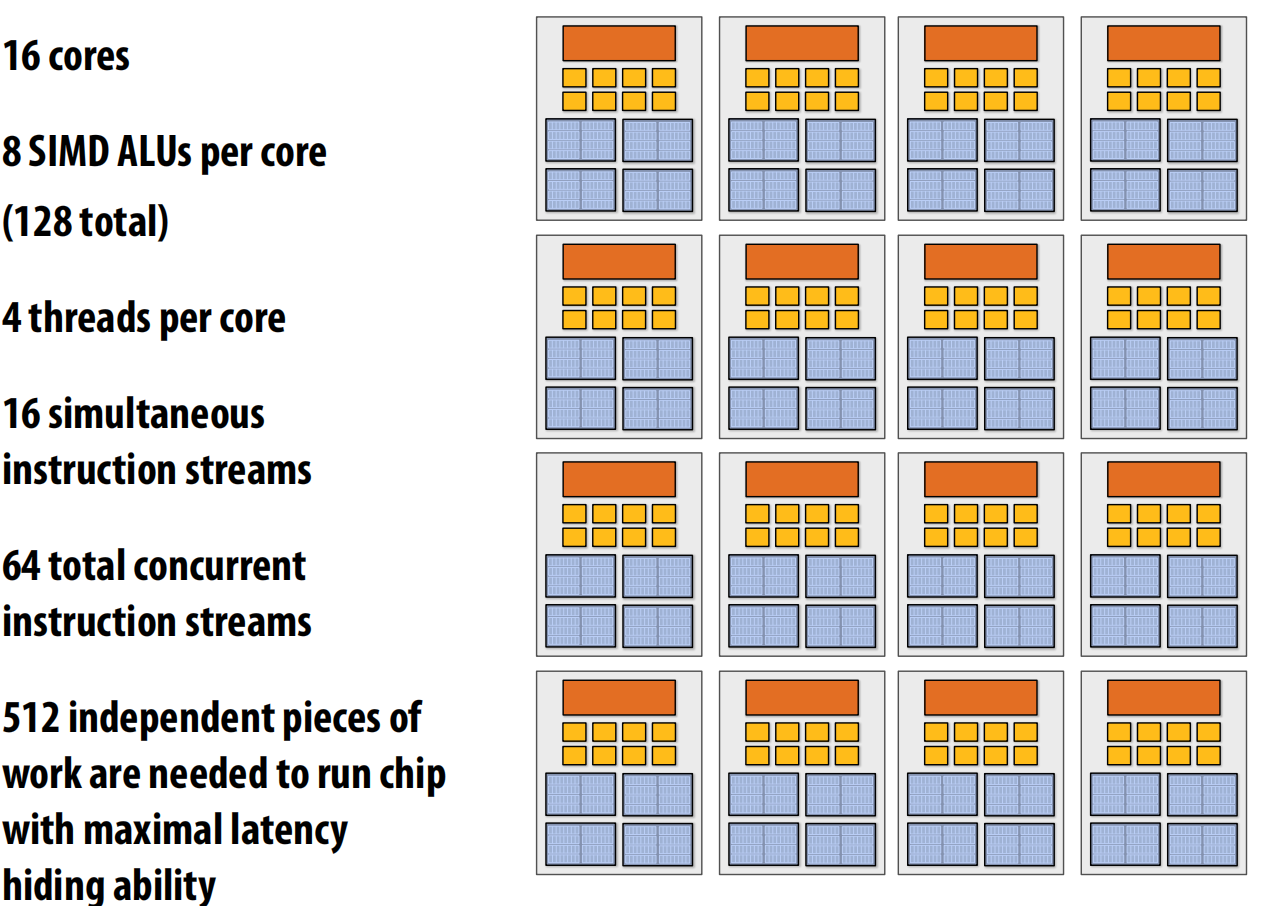
GPU 与 CPU
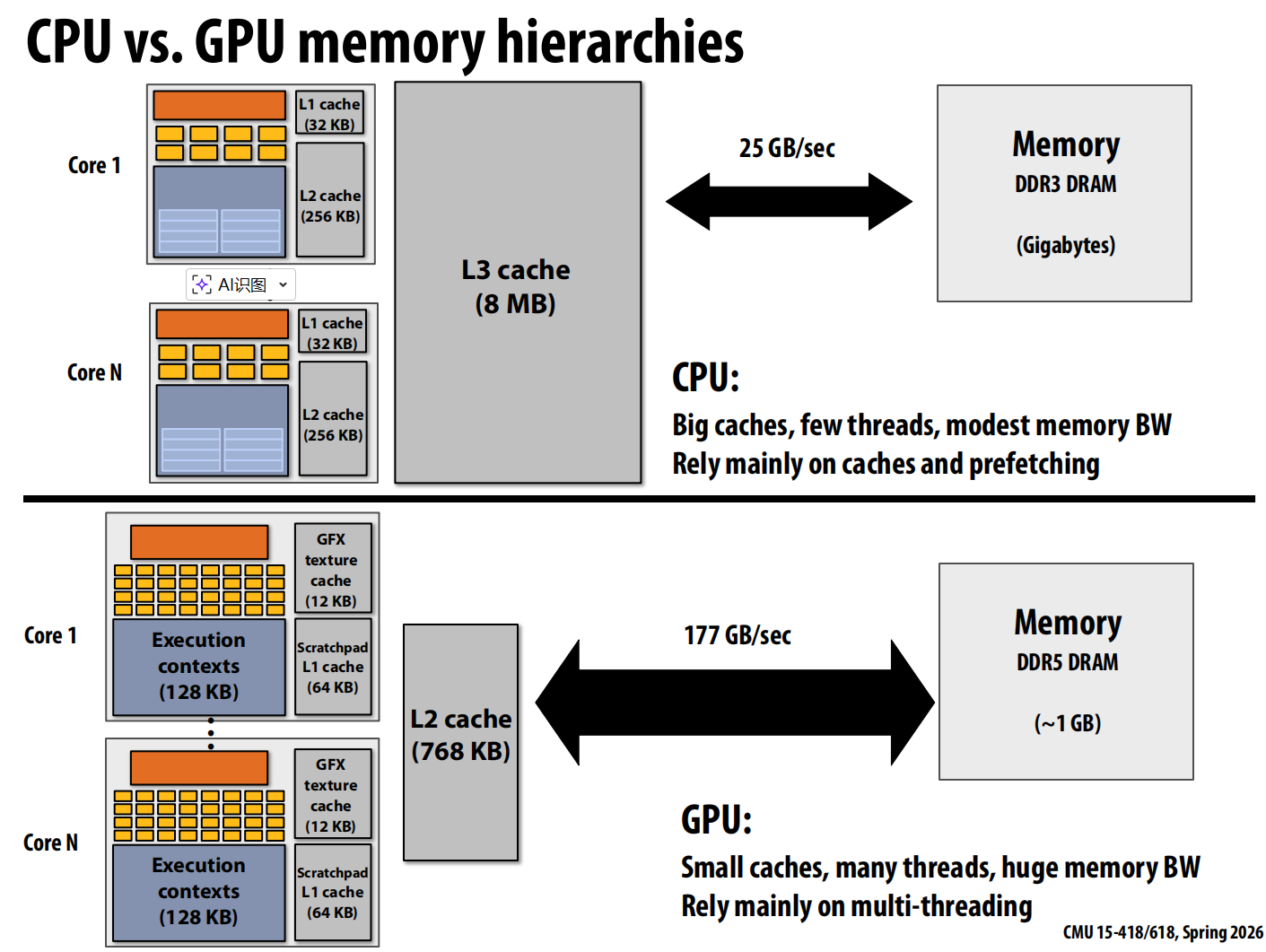
带宽限制
由于现代芯片的 高算术能力,许多并行应用(在 CPU 和 GPU 上)都受限于带宽。

Lec 3 并行编程抽象
Intel SPMD 程序编译器(ISPC)
SPMD 指的是单程序多数据,调用 ISPC 函数会生成 ISPC 的 “帮派” “编程实例(SIMD 通道)”。所有实例并发运行 ISPC 代码。
帮派是向量宽度级别的概念
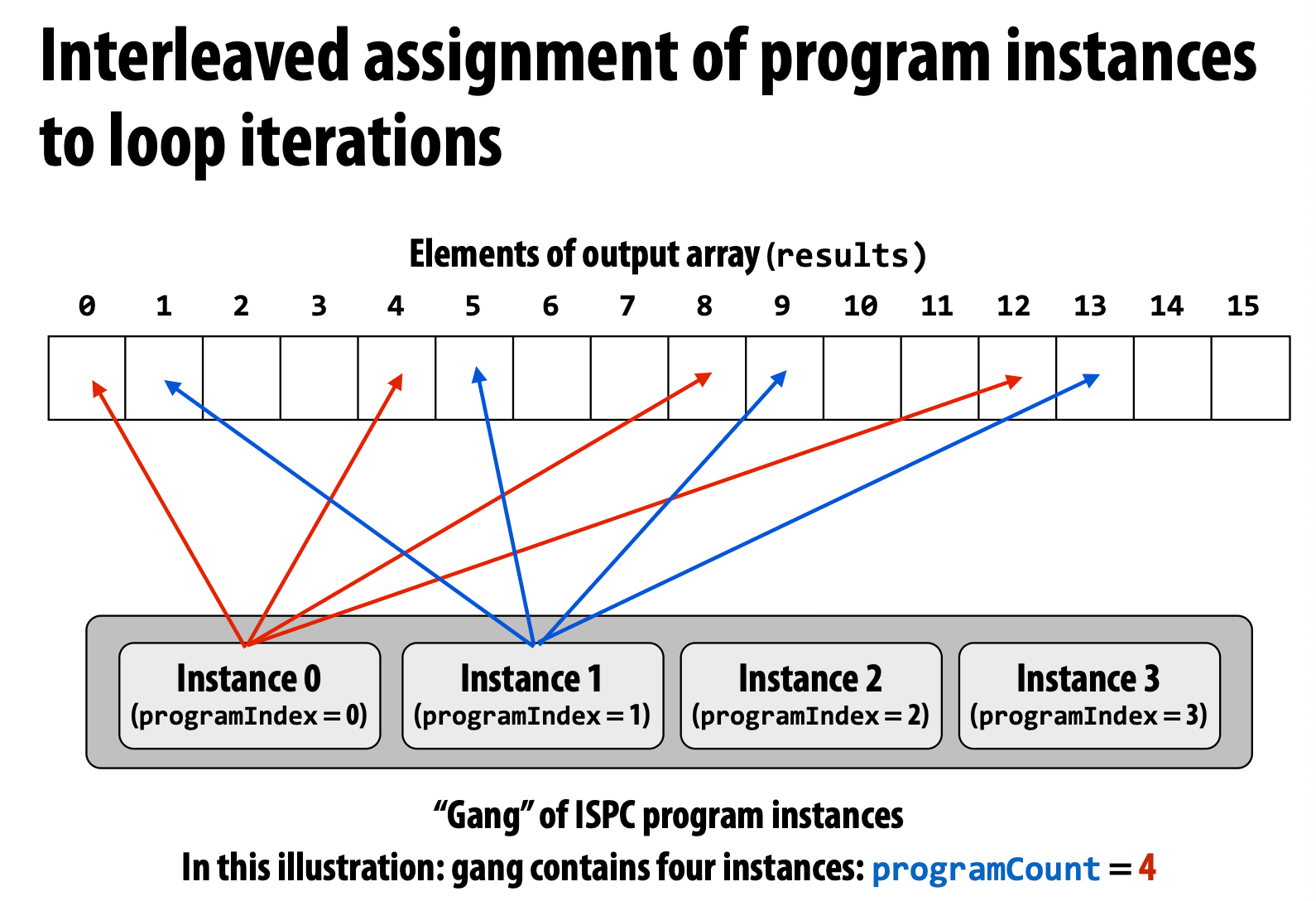
交错版本

阻塞版本

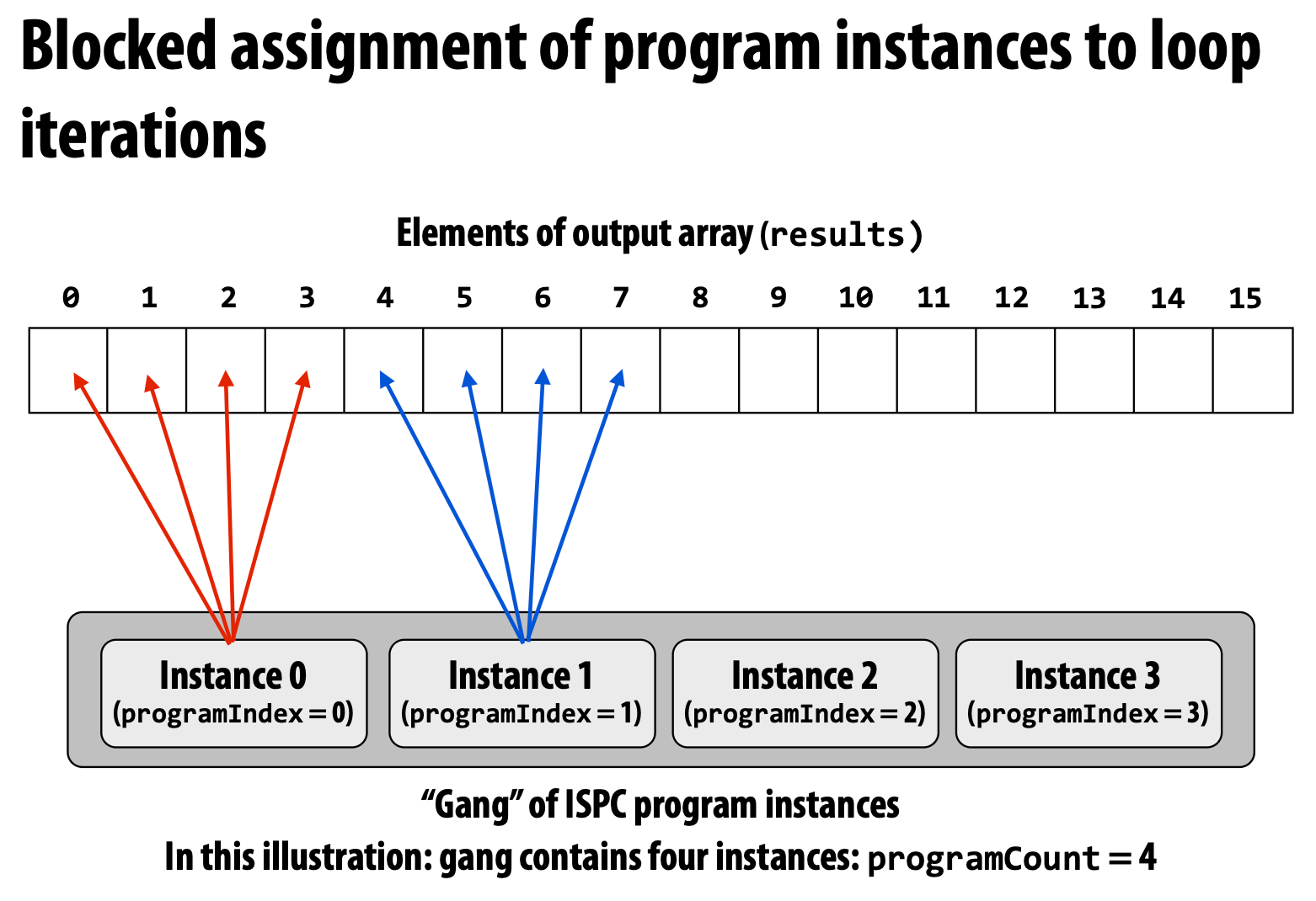
哪个更快? 答:交错 的更快。
交错版本使用 **_mm_load_ps1** 加载这些连续数据,而阻塞版本需要使用 **_mm_i32gather**,这更复杂且更慢。
对于 ISPC,我们不能将一个变化的数字与一个统一的数字相加,编译时会拒绝该代码。
四种通信模型
共享地址空间:结构非常少
线程通过
- 读取/写入共享变量。
- 操作同步原语
同步原语也是共享变量。例如,锁、信号量
共享地址空间的硬件实现
关键思想:任何处理器都可以 直接 访问任何内存位置
对称(共享内存)多处理器(SMP):统一的内存访问时间
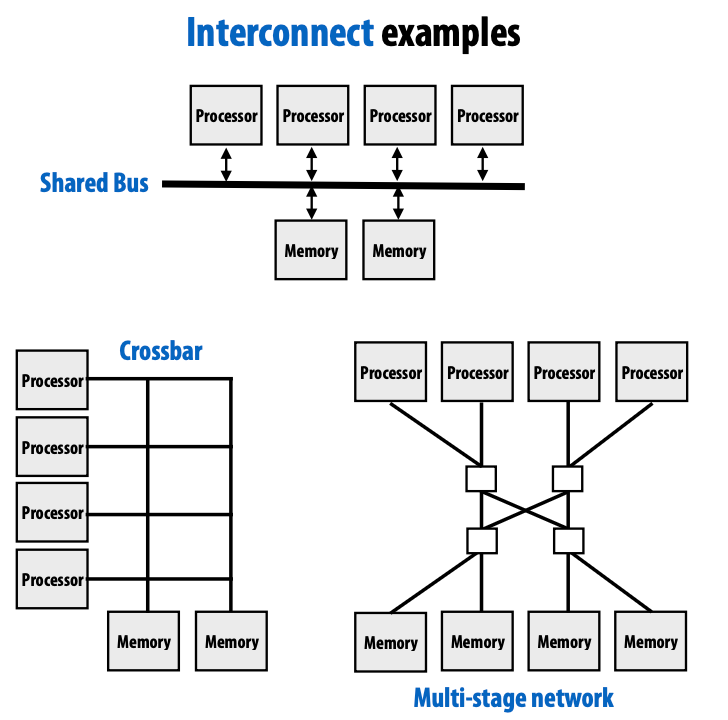
非统一内存访问(NUMA):所有处理器都可以访问任何内存位置,但内存访问的成本对处理器而言是不同的。

统一:成本是统一的,但都是统一的坏
NUMA:更具可扩展性
消息传递:高度结构化的通信
线程在自己的私有空间内操作,通过 发送/接收消息 进行通信
流行的软件库:MPI(消息传递接口)
编程模型和硬件架构之间并没有一一对应关系:消息传递可以在共享内存硬件上实现,而共享内存抽象可以在没有硬件支持的机器上模拟,通常会有性能权衡。
数据并行:非常严格的计算结构
数据并行编程将独立计算映射到大数据集合上;通过限制通信和副作用,它使简单推理和高性能实现成为可能,尽管不规则访问模式如 聚集/散布 成本较高。

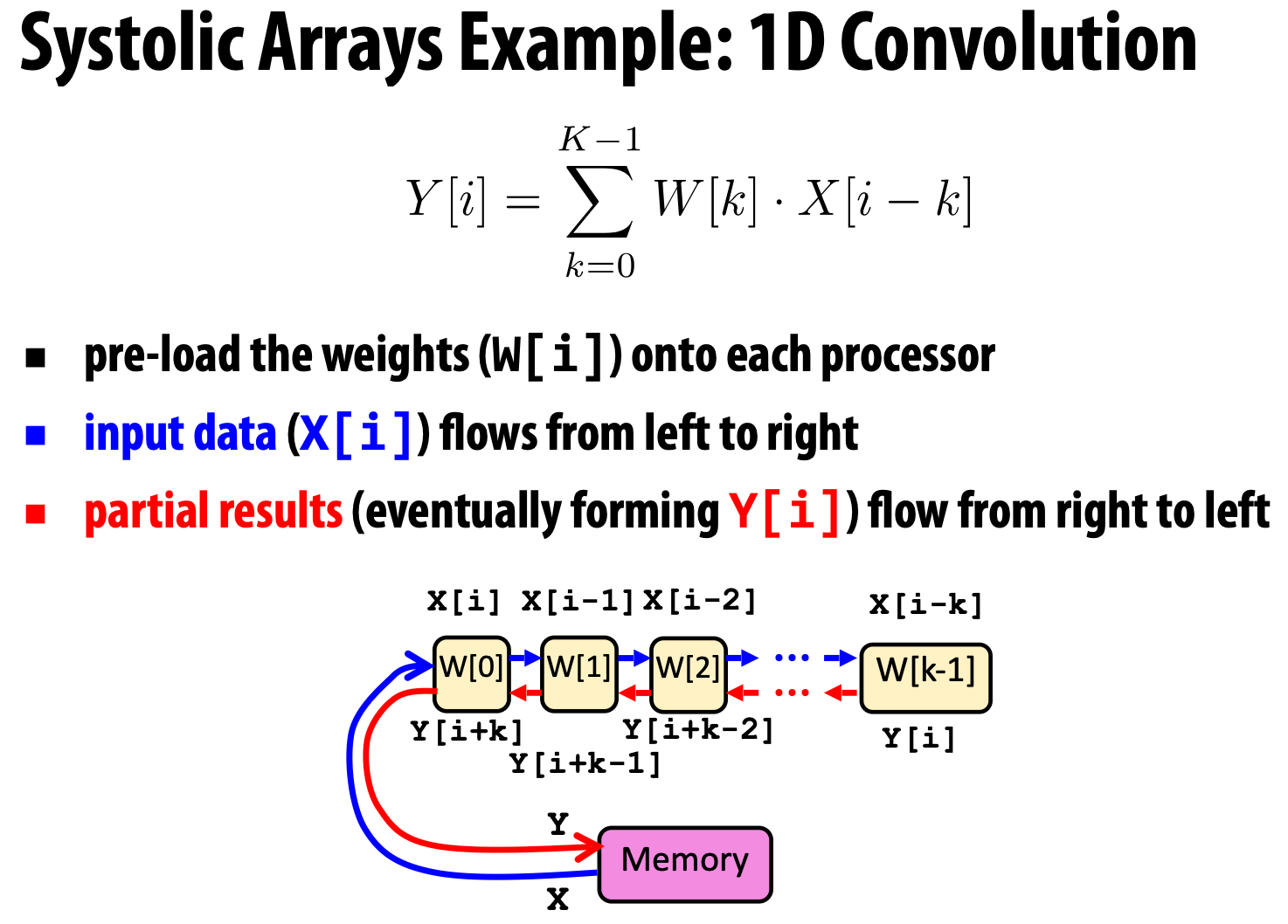
脉动阵列
目标领域:数据密集型应用,其中 内存带宽 是 瓶颈。
由于内存带宽是关键资源,因此我们确实希望 避免不必要的内存访问。因此,我们需要 在处理器上执行所有必要的计算,然后再写回任何结果,通常通过 在处理器之间直接流水线中间结果。
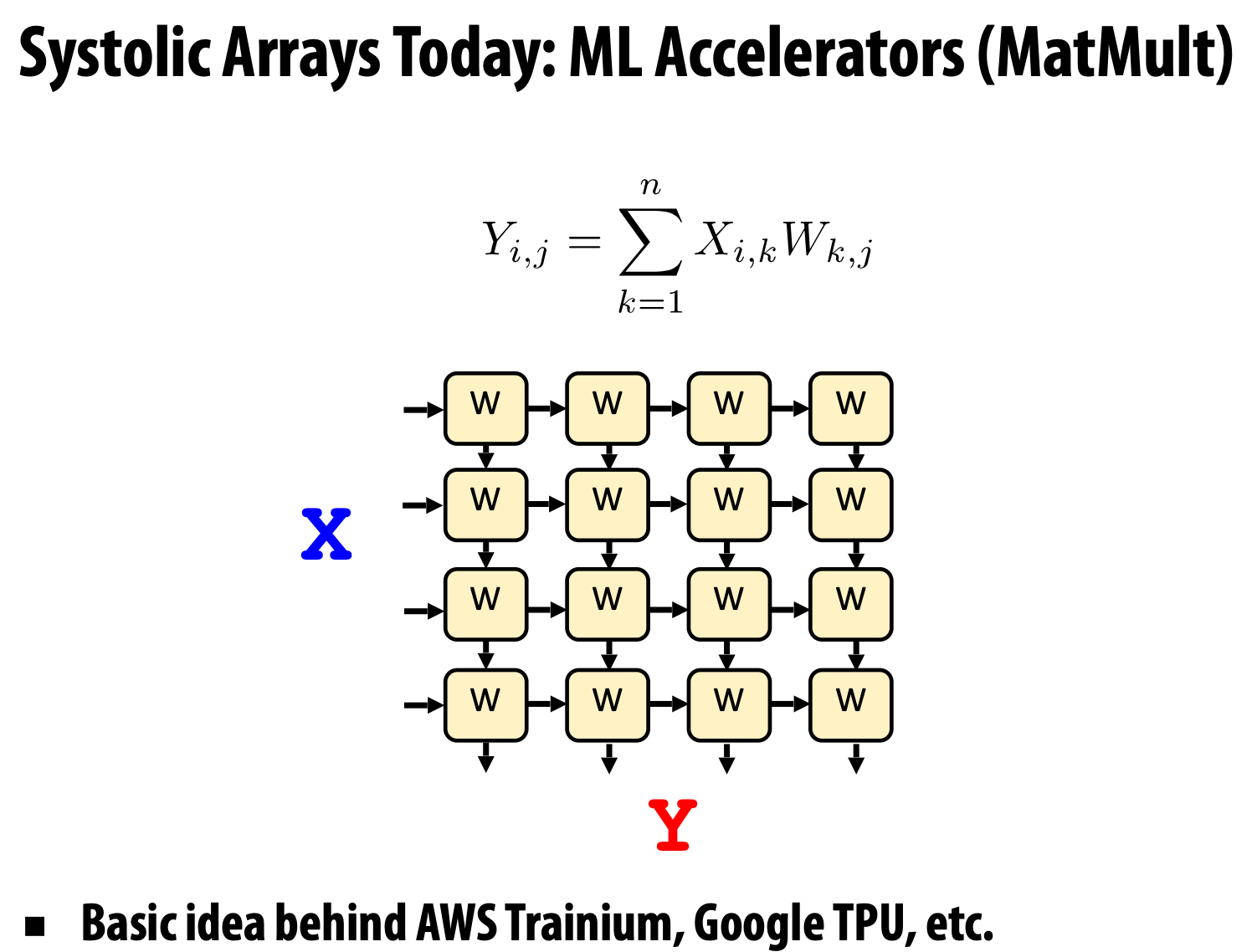
现代实践:混合编程模型
在集群的 多核节点 内使用 共享地址空间 编程,在节点之间使用 消息传递。
Lec 4 并行编程基础
创建并行程序
思考过程:
- 确定可以并行执行的工作
- 划分工作(以及与工作相关的数据)
- 管理 数据访问、通信 和 同步
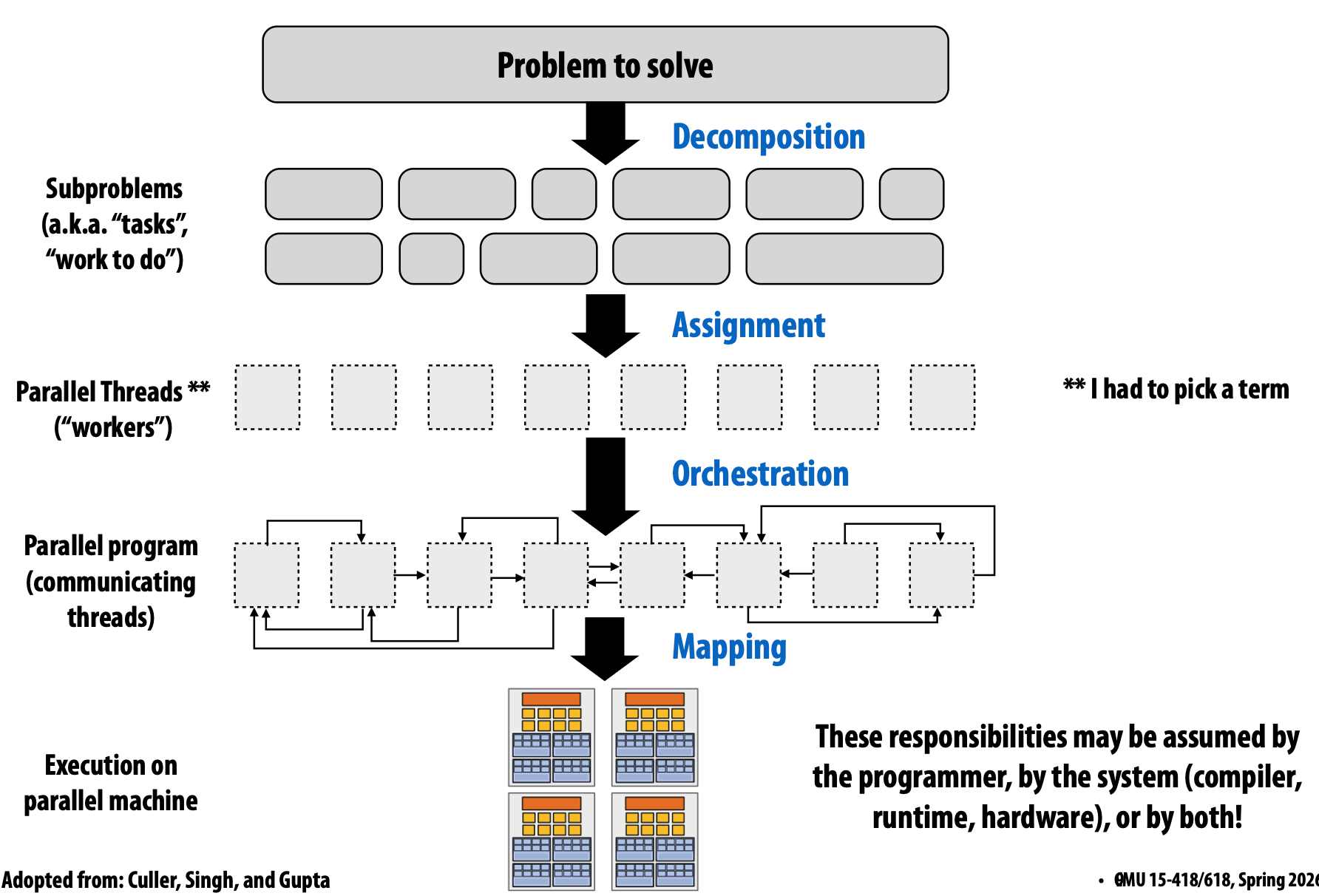
分解
将问题分解为可以 并行执行的任务
主要思想:创建至少足够的任务以保持机器上所有执行单元的忙碌。
阿姆达尔定律:依赖关系限制了由于并行性而实现的最大加速比。然后 由于并行执行的最大加速比 <= 1 / S。 \[ \text{加速比} \leq \frac{1}{s + \frac{1-s}{p}} \]
分配
将任务分配给线程
目标:平衡工作负载,减少通信成本
协调
- 结构化通信
- 添加同步以在必要时保留依赖关系
- 在内存中组织数据结构
- 调度任务
目标:减少 通信/同步成本,保留数据引用的 局部性,减少 开销 等。
映射到硬件
将“线程”(“工作者”)映射到硬件执行单元
- 通过 操作系统 映射(例如,将 pthread 映射到 CPU 核心上的硬件执行上下文)
- 通过 编译器 映射(将 ISPC 程序实例映射到向量指令通道)
- 通过 硬件 映射(将 CUDA 线程块映射到 GPU 核心)



