CS336-Lec4 Mixture of Experts
CS336-Lec4 Mixture of Experts
在现代的超大规模LLM的竞赛中,混合专家模型(Mixture of Experts, MoE)已经成为实现“万亿级参数量”与“可控计算成本”的核心技术。
MoE的核心定义
传统的Transformer模型是dense的,每个Token都会激活所有的参数。MoE的基本思想就是把巨大的FFN替换为多个并行的专家网络,然后增加一个路由层,决定Token进入哪个或哪些专家。
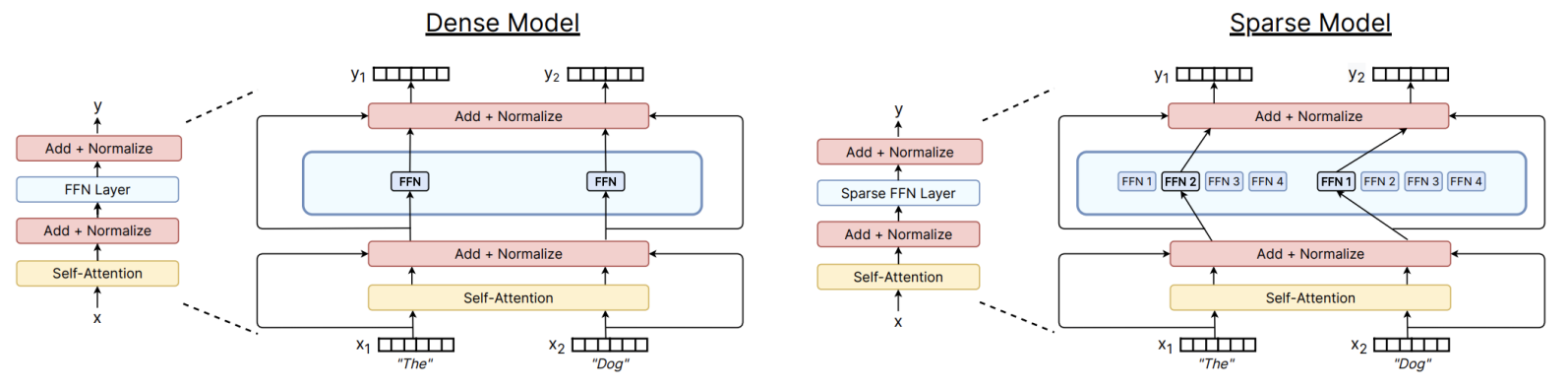
MoE 层在位置 \(t\) 的输出 \(\mathbf{h}_t^l\) 可以表示为被选中专家输出的加权总和 : \[ \mathbf{h}_t^l = \sum_{i=1}^{N} \left( g_{i,t} \cdot \text{FFN}_i (\mathbf{u}_t^l) \right) + \mathbf{u}_t^l \] 其中:
- \(N\) 是专家总数。
- \(\mathbf{u}_t^l\) 是该层的输入 Token 向量 。
- \(g_{i,t}\) 是由路由器计算的门控权重(Gating Weight),通常通过 Top-K 路由 计算 ,见下节。
路由机制
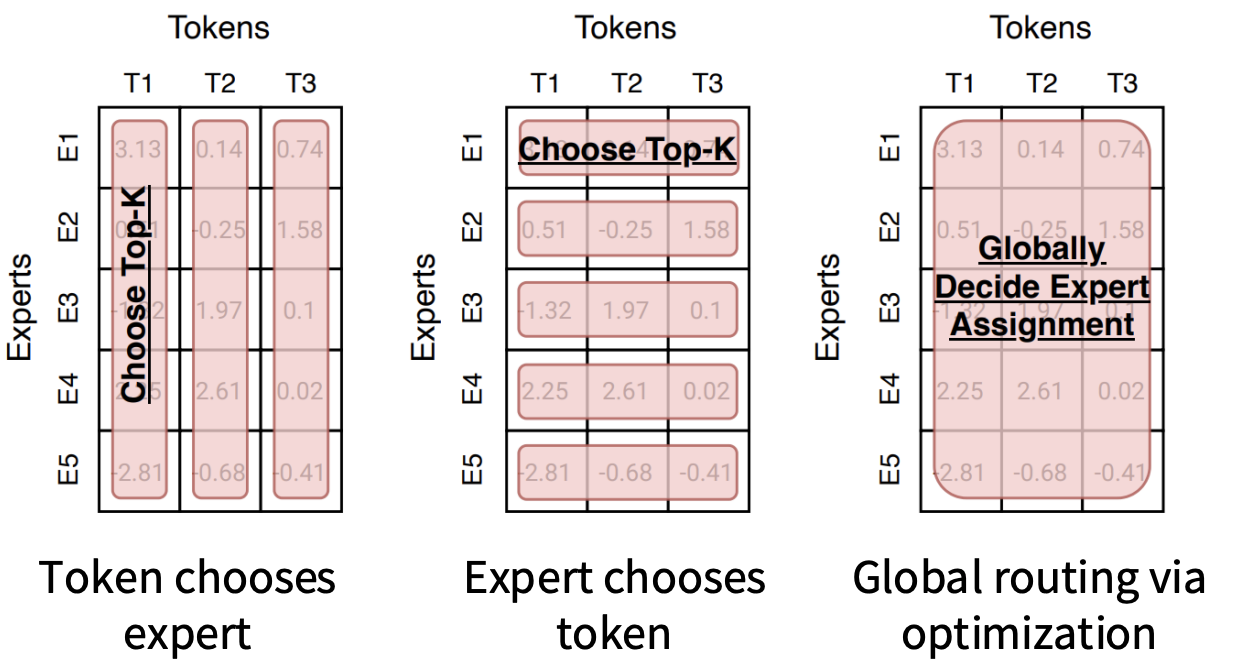
路由函数是MoE非常重要的部分,这一块决定了参数的利用效率,我们首先介绍一些路由机制可能的实现方式。大致可以按照需要Learning和不需要Learning两种:
- 需要Learning的包括Top-K以及RL机制的路由
- 不需要Learning的包括Hash和Base Routing
在这里先简单介绍一下不需要Learning的两种机制:
- 哈希路由 (Hash Routing): 采用固定的哈希函数将 Token 分配给专家 。因为路由是固定的,所以根本不需要学习 Router 参数,自然也就没有不可微的问题了
- BASE 路由 (BASE Routing): 将路由决策转化为一个“线性分配问题(Linear Assignment)”来求解,试图找到最优的全局匹配 。
但是目前大部分模型使用的都是Choose Top-K,但Top-K也有以下几种变体。
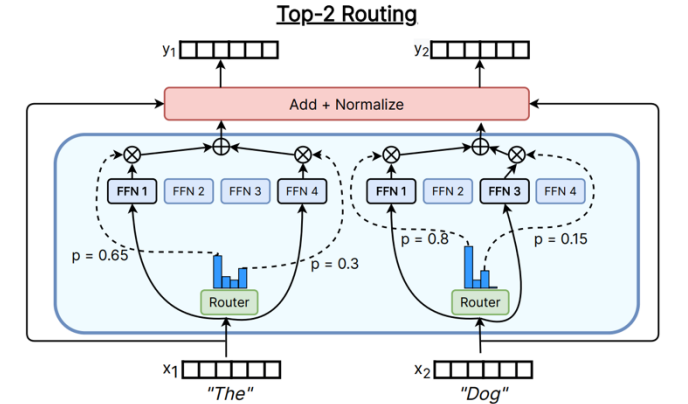
Top-K 路由数学细节(主流方案)
路由器首先计算 Token 与专家嵌入向量 \(e_i\) 的相关性得分 \(s_{i,t}\) : \[
s_{i,t} = \text{Softmax}_i (\mathbf{u}_t^{lT} e_i^l)
\] 随后,通过 Top-K 算子实现稀疏激活 : \[
g_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \text{TopK}(\{s_{j,t}
| 1 \le j \le N\}, K) \\ 0, & \text{otherwise} \end{cases}
\]
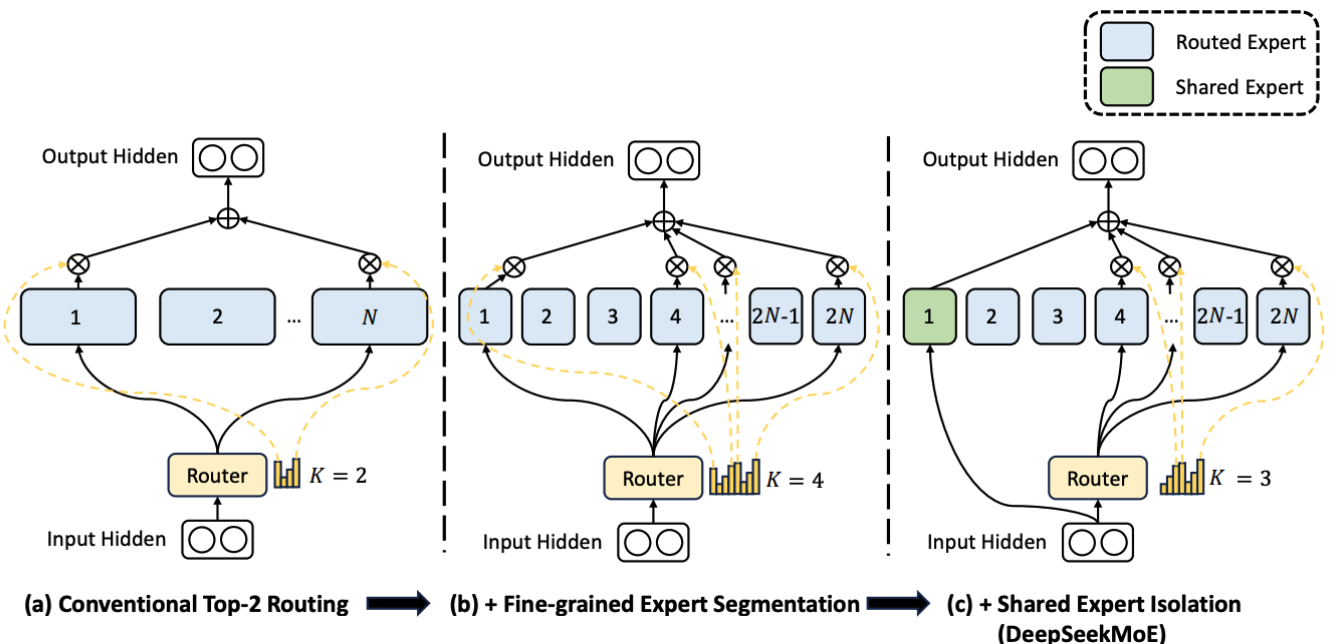
现代架构变体:DeepSeekMoE
DeepSeek引入了更加精细化的设计用于提升MoE的效果:
- 细粒度 (Fine-grained)的专家分割:将大专家拆分为多个小专家(如 \(2N\) 个),允许更精确的知识组合。
- 共享专家隔离 (Shared Expert Isolation):设置固定开启的专家,专门处理所有 Token 共享的基础公共知识,减少路由专家的冗余 。
训练的稳定性
MoE的核心挑战在于如何稳定的训练。为了提高训练的效率,我们需要模型具备稀疏性,但是稀疏的门控机制(Top-K)是Non-differentiable的。而且,我们还需要保持专家间的负载均衡,如果不对Router进行约束,那流量集中在部分专家,导致剩下的得不到训练,成为“死专家”,我们有以下的Solutions去解决这个问题。
强化学习 (Reinforcement Learning)
其原理很简单,就是将整个Router视作一个智能体,将Token视为Action,利用强化学习的算法,根据最终的Loss(作为Reward)来优化route策略。
但其实这种方法并不常用,逻辑上正确,但是梯度方差极大且计算复杂, 导致在大规模与训练中不如其他方案,不被广泛采纳。
随机近似 (Stochastic Perturbations)
原理就是在路由的Logits中加入高斯噪声(Gaussian noise)或者是随机抖动(Jitter),强迫模型进行一些非常规的探索。 \[ H(x)_i = (x \cdot W_g)_i + \text{StandardNormal}() \cdot \text{Softplus}((x \cdot W_{noise})_i) \] 即使这样的初始权重不好,随机性也会让每个专家都有机会得到训练,让Route变得更robust,避免了一些dead expert的出现,
辅助Loss (Auxiliary Loss)
为了让每个专家均匀分担任务,引入辅助 Loss,意味着越频繁使用的专家收到的惩罚越严重,loss最小是任务平均分配到各专家: \[ \text{Loss}_{aux} = \alpha \cdot N \cdot \sum_{i=1}^N f_i \cdot P_i \] 其中:
- \(f_i\) (分发比例): 代表该 Batch 中被分派到专家 \(i\) 的 Token 比例 。
\[ f_{i} = \frac{1}{T} \sum_{x \in \mathcal{B}} \mathbb{I}\{argmax \ p(x) = i\} \]
- \(P_i\) (路由概率比例): 代表 Router 分配给专家 \(i\) 的概率总和比例。
\[ P_{i} = \frac{1}{T} \sum_{x \in \mathcal{B}} p_{i}(x) \]
DeepSeek的变体实现
DeepSeek v1-2 (专家与设备双重均衡): 引入了
Per-expert Loss(和Switch
Transfomer一致),确保专家之间平衡 。以及 Per-device
Loss,确保跨 GPU 通信(All-to-All)也达到平衡 。
DeepSeek v3 (无辅助损失均衡): 引入了 Per-expert Bias (\(b_i\)) 机制: \[ S_{i,t}^{\prime} = \begin{cases} s_{i,t}, & s_{i,t}+b_{i} \in Topk(\{s_{j,t}+b_{j} | 1 \le j \le N_{r}\}, K_{r}) \\ 0, & \text{otherwise} \end{cases} \] 通过在线学习调整偏置 \(b_i\),在不破坏主 Loss 梯度的情况下实现平衡(Auxiliary-loss-free)。

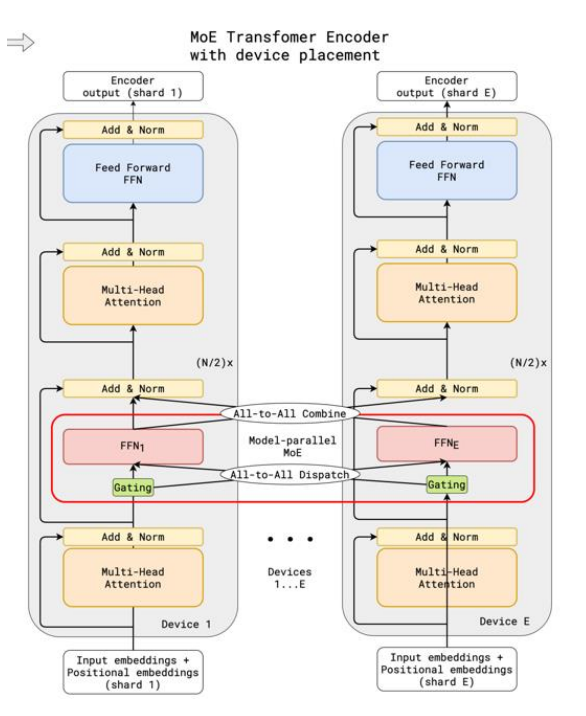
系统优化:分布式并行和计算优化
由于参数规模巨大, MoE的物理实现极度依赖并行化。
1. 设备部署 (Device Placement)
- All-to-All Dispatch:Token 根据路由结果,跨设备分发到对应的专家节点 。
- All-to-All Combine:计算结果回传,维持序列顺序 。
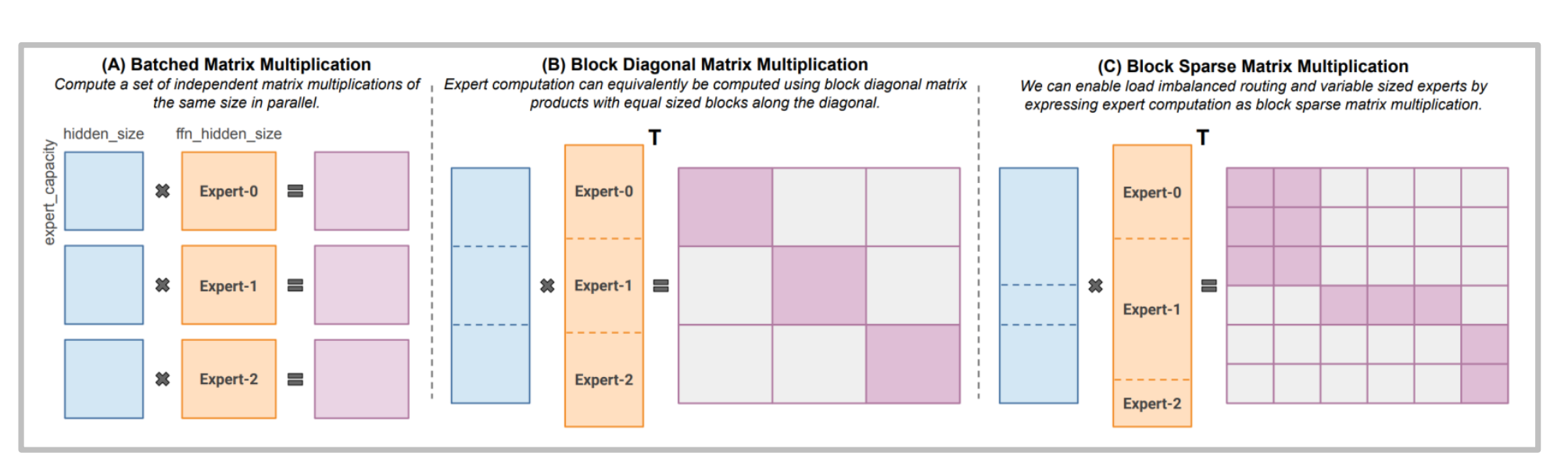
2. 计算算子优化 (MegaBlocks)
传统的矩阵乘法在面对负载不均时效率极低 。MegaBlocks 等库引入了块稀疏矩阵乘法 (Block Sparse MM),能够高效处理变长的专家计算,避免了填充导致的资源浪费 。
进阶技术
z-loss (数值平滑):为防止 Softmax 在低精度下溢出,通过惩罚 \(\log^2 Z\)(\(Z\) 为配分函数)强制 Logits 处于安全范围。
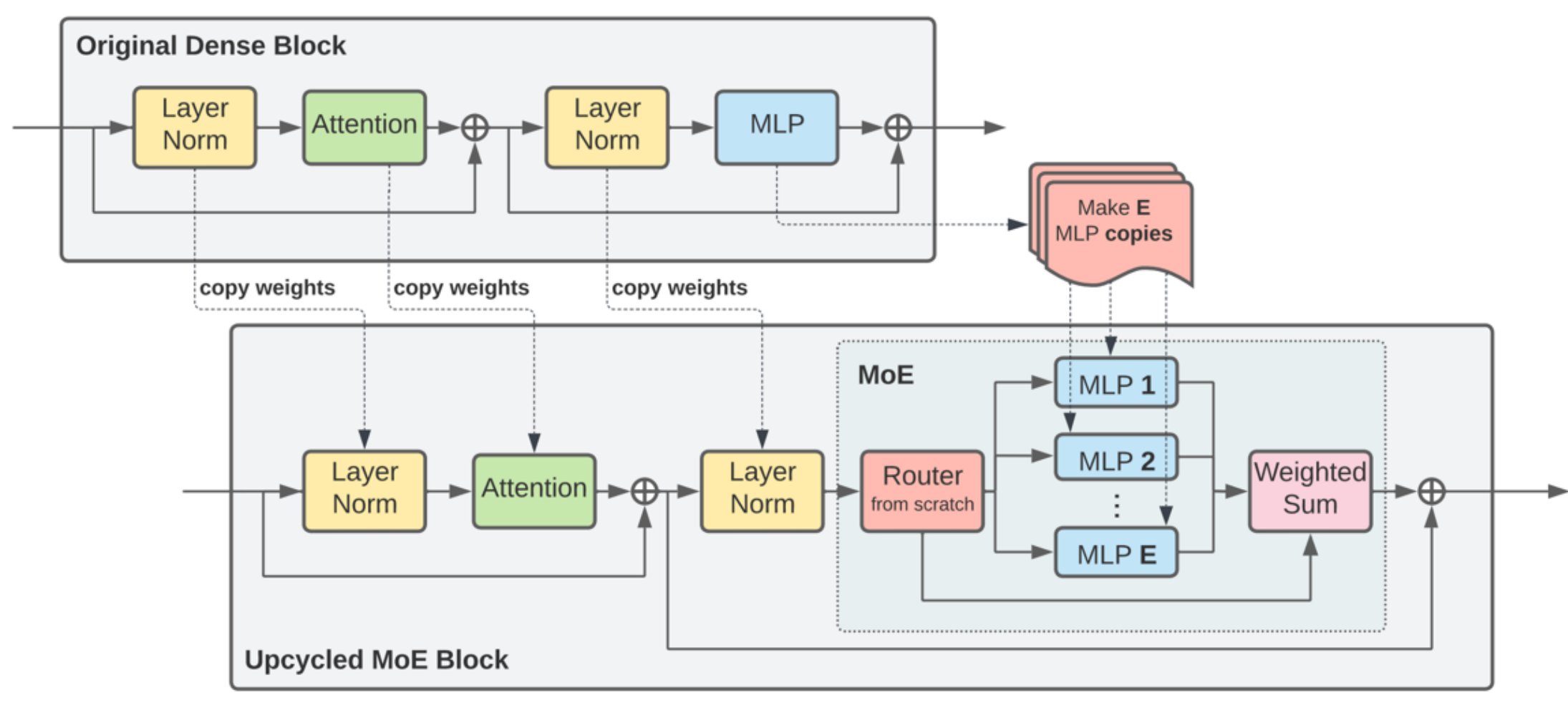
Upcycling (上行循环):可以将训练好的稠密模型 FFN 权重克隆多份,作为 MoE 专家的初始值,显著缩短从零开始训练的时间,在部分model上证明效果有很大提升。
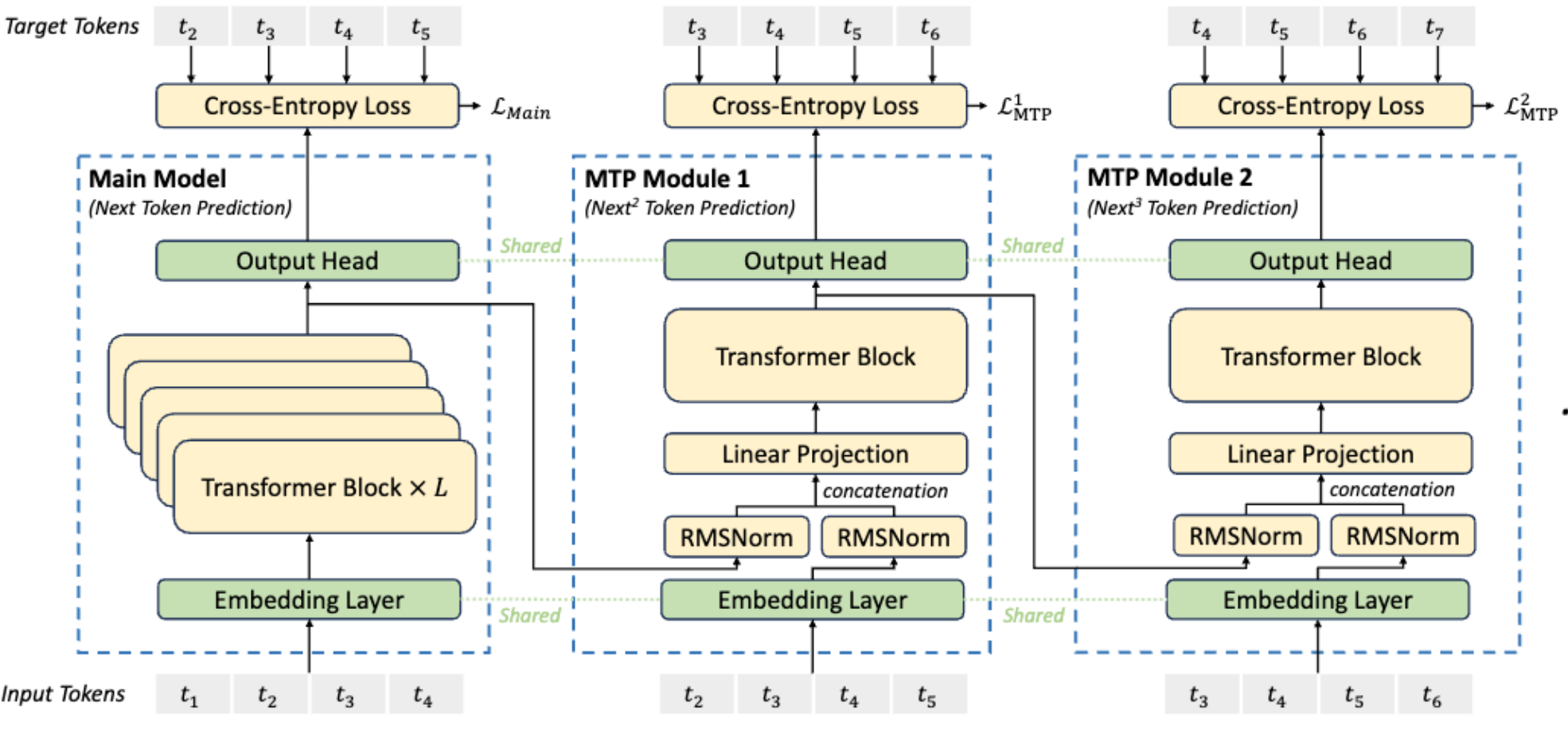
MTP (多 Token 预测):DeepSeek v3 使用的技术。在主模型之外增加轻量模块,一次预测未来多个 Token,增强了模型对长文本的建模能力。
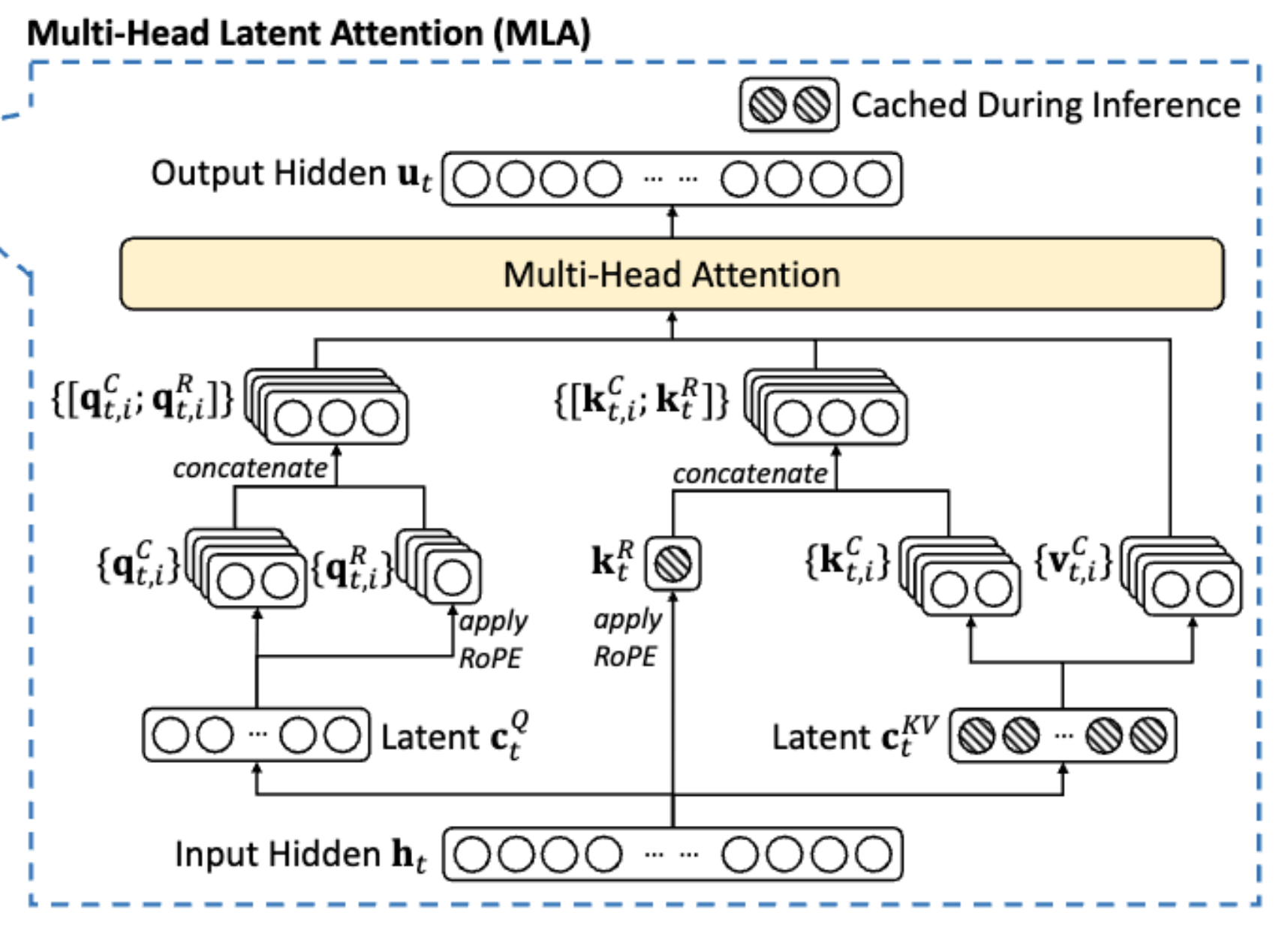
MLA (多头潜在注意力):DeepSeek v3 解决 KV Cache 瓶颈的关键。通过将 Q、K、V 投影到低维的“潜在 (latent)”空间进行压缩,推理时只需缓存极小的隐向量 \(c_t^{KV}\),大幅削减了显存占用。同时通过解耦设计,让部分维度不参与压缩(模型架构时预先设定的硬性规则)以适配旋转位置编码 (RoPE),解决了位置编码与压缩缓存的冲突 。
- 为什么省了缓存?A: 重构矩阵 \(W^{UK}\) 可以被直接吸收到查询矩阵 Q 的投影中。这意味着在推理时,我们只需要在显存中缓存低维的 \(c_t^{KV}\),而不需要缓存重构后的多头 K 和 V。
\[ \text{Score} = (h W_Q)^T \times (W_{UK} c_t^{KV}) = h \cdot (W_Q W_{UK}) \cdot c_t^{KV} \]
- RoPE为什么要解耦,不能直接在潜空间加RoPE吗?A: 不行,直接看公式,此时无法合并矩阵为一个,导致我们需要还原Key,省显存的计划破产。
\[ \text{Score} = (R_m h W_Q)^T \times (R_n W_{UK} c_n^{KV}) = h W_Q \cdot (R_m^T R_n) \cdot W_{UK} c_n^{KV} \]