CS336-Lec3 Architectures & Hyperparameters
CS336-Lec3 Architectures & Hyperparameters
Overview of Original vs. Modern Transformer
| 特征 | 原始 Transformer | 现代变体 | 优化目标/优势 |
|---|---|---|---|
| 层归一化 (LayerNorm) | Post-Norm: 位于每个子层(Attention/FFN)之后 。 | Pre-Norm: 位于每个子层之前。 | 提高深层模型的训练稳定性,加速收敛。 |
| 归一化类型 | LayerNorm: 归一化均值和方差 | RMSNorm: 仅归一化方差,不减去均值,不使用偏置项 。 | 计算更快,参数更少,性能无明显下降。 |
| 偏置项 (Bias) | FFN 和线性层有偏置项 \(\boldsymbol{b}\)。 | 线性层(包括归一化层)无偏置项。 | 减少内存占用,提高优化稳定性。 |
| 位置编码 (PE) | 正弦余弦编码 (Sine/Cosine): 将位置信息相加到词嵌入中。 | 旋转位置编码 (RoPE): 将位置信息编码到查询和键(Q/K)向量的旋转操作中。 | 更好地捕捉相对位置信息,已成为 2024 年后大多数 SOTA 模型(如 LLaMA)的标准。 |
| FFN 激活函数 | ReLU | SwiGLU/GeGLU: 一种门控激活函数(Gated Activation。 | 通常比 ReLU 和 GeLU 性能更优,有更一致的增益。 |
| 层连接 | Serial (串行): 先计算 Attention,再计算 MLP。 | Serial 或 Parallel (并行): Attention 和 MLP 并行计算。 | Parallel 结构可以在大规模训练时通过矩阵乘法融合,实现约 15% 的训练速度提升。 |
Normalization
在Transformer架构中,归一化层的位置对模型训练的稳定性和效率至关重要。现代LLM几乎一致的抛弃了原始的归一化位置,采取了一些更稳定的策略。
Pre-Norm vs. Post-Norm
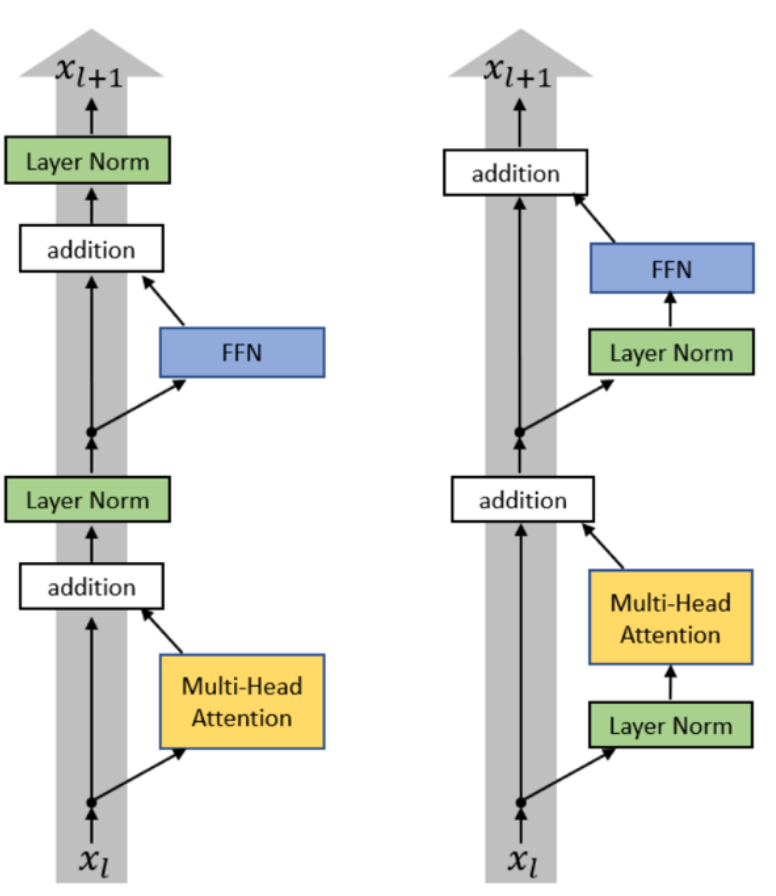
- Post-Norm (原始 Transformer): 归一化操作位于每个子层(如 Multi-Head Attention 或 FFN)计算后的残差连接之后。这种结构在训练深层模型时容易导致梯度消失或梯度爆炸,影响训练稳定性。
- Pre-Norm (现代 LLM): 归一化操作位于每个子层之前。这种放置方式能确保残差连接的主路径信号保持良好的尺度,从而极大地改善梯度传播,提高深层网络的训练稳定性。
It worth noting that almost all modern LMs use pre-norm (but BERT was post-norm)
LayerNorm vs. RMSNorm
原始 Transformer 采用 LayerNorm,而现代 LLM 则倾向于使用 RMSNorm。这两种方法在数学和工程效率上存在核心区别。
LayerNorm: \[ y=\frac{\boldsymbol{x}-E[\boldsymbol{x}]}{\sqrt{\text{Var}[\boldsymbol{x}]+\epsilon}} \cdot \gamma+\beta \]
- 前面那一堆是为了把神经网络某一层的输入\(\boldsymbol{x}\)(例如,一个 Token 的 \(d_{model}\) 维特征向量)进行中心化和归一化,使其均值为0,方差为1。
- \(\gamma\)和\(\beta\)分别是缩放参数和偏移参数,可学习,为了恢复模型的表达能力。
RMSNorm: \[ y=\frac{\boldsymbol{x}}{\sqrt{\frac{1}{D}\sum_{i=1}^{D}\boldsymbol{x}_i^2+\epsilon}} \cdot \gamma \]
- 均方根RMS\(\sqrt{\frac{1}{D}\sum_{i=1}^{D}\boldsymbol{x}_i^2+\epsilon}\) : 均方加一个极小值后的平方根,作为归一化的因子。它近似于向量的 \(\ell_2\) 范数。
- \(\gamma\)仅剩缩放参数,去掉了偏移参数。
核心区别:RMSNorm是对LayerNorm的简化:他放弃了计算和减去均值(中心化)的操作,只保留了尺度缩放。且得到了实践证明。
工程效率和训练优势的分析
RMSNorm 之所以被现代 LLM 广泛采用,主要是基于工程效率和实践效果的权衡:
- 更快的运行时(wallclock time)
- 计算优势:RMSNorm 没有均值计算,比 LayerNorm 的操作更少。
- 参数优势: RMSNorm 没有偏置项 \(\beta\) ,需要存储的参数更少 。
- 数据移动: 归一化操作虽然 FLOPs 占比小 (约 0.17%),但运行时占比很高 (约 25.5%) 。减少参数和计算,可以减少数据移动,从而节省实际的训练时间 。
- 性能相当: 实践证明,RMSNorm 在性能上通常与 LayerNorm 同样有效,表格数据也显示,RMSNorm 相比 Vanilla Transformer 在 Early Loss 和 Final Loss 上甚至略有提升 。

事实上,现代的FFN结构中甚至drop掉了偏置项bias: \[ \underbrace{\text{FFN}(\boldsymbol{x}) = \max(0, \boldsymbol{x} \boldsymbol{W}_1 + \boldsymbol{b}_1) \boldsymbol{W}_2 + \boldsymbol{b}_2}_{\text{原始 Transformer (ReLU, 含偏置项)}} \quad \longrightarrow \quad \underbrace{\text{FFN}(\boldsymbol{x}) = \sigma(\boldsymbol{x} \boldsymbol{W}_1) \boldsymbol{W}_2}_{\text{现代简化 (}\sigma\text{, 无偏置项)}} \]
激活函数 Activation
激活函数是神经网络中引入的非线性的核心机制。在Transformer架构中,FFN对激活函数的选择经历了从ReLU到复杂的门控(Gated)机制的演变。
ReLU 整流线性单元 (Rectified Linear Unit)
\[ \text{FFN}(\boldsymbol{x}) = \max(0, \boldsymbol{x} \boldsymbol{W}_1) \boldsymbol{W}_2 \]
计算量小,当\(x \le 0\)时输出为0
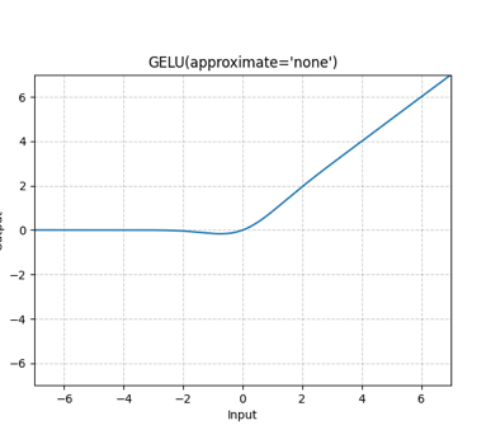
GeLU 高斯误差线性单元 (Gaussian Error Linear Unit)
GeLU是在ReLU基础上引入统计学思想的平滑激活函数。 \[ \text{FFN}(\boldsymbol{x}) = \text{GeLU}(\boldsymbol{x} \boldsymbol{W}_1) \boldsymbol{W}_2 \]
\[ \text{GeLU}(\boldsymbol{x}) = \boldsymbol{x} \cdot \Phi(\boldsymbol{x}) \]
核心概念:\(\Phi(\boldsymbol{x})\) 累积分布函数 (CDF)
\(\Phi(\boldsymbol{x})\) 特指标准正态分布的累积分布函数(CDF)。
- CDF 的定义: 对于一个随机变量 \(X\),其 CDF \(\boldsymbol{F}(\boldsymbol{x})\) 定义为 \(P(X \le \boldsymbol{x})\),即随机变量取值小于或等于 \(\boldsymbol{x}\) 的概率。CDF 的值域始终在 \([0, 1]\) 之间。
- \(\Phi(\boldsymbol{x})\)
的作用: 在 GeLU 中,\(\Phi(\boldsymbol{x})\)
充当了一个平滑的“门”或权重因子:
- 当 \(\boldsymbol{x}\) 为大正数时,\(\Phi(\boldsymbol{x}) \approx 1\) (信号被完全保留)。
- 当 \(\boldsymbol{x}\) 为负数时,\(\Phi(\boldsymbol{x})\) 逐渐趋近于 \(0\) (信号被平滑抑制)。
- 图形优势: 这种基于 CDF 的乘法操作,消除了 ReLU 在 \(\boldsymbol{x}=0\) 处的不可导尖点,使 GeLU 处处平滑,从而提高了深层网络的训练稳定性。
GLU 门控线性单元 (Gated Linear Unit)
GLU 家族引入了更复杂的门控机制,被认为是目前性能最强大的 FFN 激活机制。
GLU是所有门控激活的基础,它不仅仅是对输入进行简单的非线性变换,而是使用两个独立的线性投影来控制信息流。
- 核心结构: 相比于 \(\text{FF}(\boldsymbol{x}) = \max(0, \boldsymbol{x}\boldsymbol{W}_1)\boldsymbol{W}_2\):GLU 引入了一个额外的参数矩阵 \(\boldsymbol{V}\)。将 \(\max(0, \boldsymbol{x}\boldsymbol{W}_1)\) 替换为 \(\max(0, \boldsymbol{x}\boldsymbol{W}_1) \otimes (\boldsymbol{x}\boldsymbol{V})\) (ReGLU)。
- 门控机制: (\(\boldsymbol{x}\boldsymbol{V}\)) 作为门控信号,通过逐元素相乘 (\(\otimes\)) 来控制另一路经过激活函数的信息流的通过量。
- 优势: 增强了模型的非线性表达能力,已被证明能带来一致的性能增益。
GeGLU 门控 GeLU (Gated GeLU)
公式: \(\text{FFN}_{\text{GeGLU}}(\boldsymbol{x}, \boldsymbol{W}, \boldsymbol{V}, \boldsymbol{W}_2) = (\text{GeLU}(\boldsymbol{x} \boldsymbol{W}) \otimes \boldsymbol{x} \boldsymbol{V}) \boldsymbol{W}_2\)
特性: 结合了 GeLU 的平滑性和门控机制。
SwiGLU 门控 Swish (Gated Swish)
- 公式:\(\text{FFN}_{\text{SwiGLU}}(\boldsymbol{x}, \boldsymbol{W}, \boldsymbol{V}, \boldsymbol{W}_2) = (\text{Swish}_1(\boldsymbol{x} \boldsymbol{W}) \otimes \boldsymbol{x} \boldsymbol{V}) \boldsymbol{W}_2\),其中 \(\text{Swish}(\boldsymbol{x}) = \boldsymbol{x} \cdot \text{sigmoid}(\boldsymbol{x})\)。
- 地位: 是目前最受欢迎且性能最强的激活函数之一。
Swish 函数: \[ \text{Swish}(\boldsymbol{x}) = \boldsymbol{x} \cdot \text{sigmoid}(\boldsymbol{x}) \] 其中,\(\text{sigmoid}(\boldsymbol{x}) = \frac{1}{1 + e^{-\boldsymbol{x}}}\)。
Swish 激活函数的特性使其在实践中通常优于 ReLU:
- 平滑性 (Smoothness): Swish 是一个处处可导的平滑函数 。这与 GeLU 相似,避免了 ReLU 在 \(x=0\) 处的尖锐拐点,有助于优化过程更加稳定。
- 非单调性 (Non-monotonicity): Swish 在负半轴上具有非单调性(即它的曲线在 \(x < 0\) 的区域会先下降,达到一个极小值后,再逐渐趋于零)允许模型在一定程度上保留或赋予一些负值信息的权重,增强模型的表达能力。
总结
现代的LLM首选的激活函数是SwiGLU或者GeGLU,引入门控结构,简化实现移除偏置项,来提供一致的性能增益,从而增强模型的表达能力,不过仍需注意GLU并非构建优秀模型的唯一必要条件(如GPT-3仍使用GeLU)。
串行 vs. 并行
传统的串行计算方式是先计算Attention及其残差链接,然后将Attention的结果作为FFN的输入,再计算FFN及其残差链接。这样的话,Attention和FFN必须依次等待前一个计算的完成。
为了提高训练的效率,以 GPT-J、PaLM 和 GPT-NeoX 为代表的一些现代模型引入了 并行结构。其核心在于:Attention 和 FFN 共享相同的输入,并同时计算。
- 输入共享:Attention Block 和 MLP Block 都接收 LayerNorm 后的原始输入 \(\boldsymbol{x}\) 作为它们的输入信号。
- 并行计算: 两个子层独立、同时地计算其结果。
- 残差汇合: 两个子层的输出(Attention 增益和 MLP 增益)通过一个单一的残差连接,一起加回到原始输入 \(\boldsymbol{x}\) 上,形成最终输出 \(\boldsymbol{y}\)。
\[ \boldsymbol{y} = \boldsymbol{x} + \text{MLP}(\text{LayerNorm}(\boldsymbol{x})) + \text{Attention}(\text{LayerNorm}(\boldsymbol{x})) \]
并行结构之所以被采用,主要是因为显著的训练加速:
- 速度提升: 并行结构在大规模训练时,可以实现大约 15% 的训练速度提升。
- 矩阵融合: 这种加速主要得益于 矩阵乘法融合(Matrix Multiplies Fusion)。由于 Attention 和 MLP 的输入矩阵乘法可以合并处理,减少了内存访问和计算开销。
- 性能保证: 实验证明,如果实现得当,并行化对模型质量的退化很小,甚至可以忽略不计。
Embedding
由于Transfomer的Self-Attention机制本质上是置换不变(Permutation Invariant)的,所以我们必须显式注入位置信息。现代的LLM位置编码的演变主要围绕“如何更好的捕捉相对位置”展开。
Sine Embeddings (正弦编码)
\[ Embed(x, i) = v_x + PE_{pos} \\ PE_{(pos, 2i)} = \sin(pos/10000^{2i/d_{\text{model}}}) \\ PE_{(pos, 2i+1)} = \cos(pos/10000^{2i/d_{\text{model}}}) \]
虽然其具备相对位置的数学性质,但是在Attention的计算中展开后的项 \(\langle v_x + p_i, v_y + p_j \rangle\) 会包含杂乱的 交叉项 (cross-terms),例如 \(\langle v_x, PE_j \rangle\)。这些项混合了内容和位置信息,被认为是噪声。
Absolute Embeddings (绝对位置编码)
\[ Embed(x, i) = v_x + u_i \]
直接为每个位置 \(i\) 学习一个可训练的向量。
局限: 显然不是相对的 (obviously not relative),且外推性(Extrapolation)较差,难以处理超过训练长度的序列。
Relative Embeddings (相对位置编码)
直接在 Attention 计算中加入偏置项 \(a_{ij}\)。公式为 \[ e_{ij} = \frac{x_i W^Q (x_j W^K + a_{ij}^K)^T}{\sqrt{d_z}} \] 虽然解决了相对位置问题,但不再是标准的内积形式 (not an inner product),增加了计算实现的复杂度
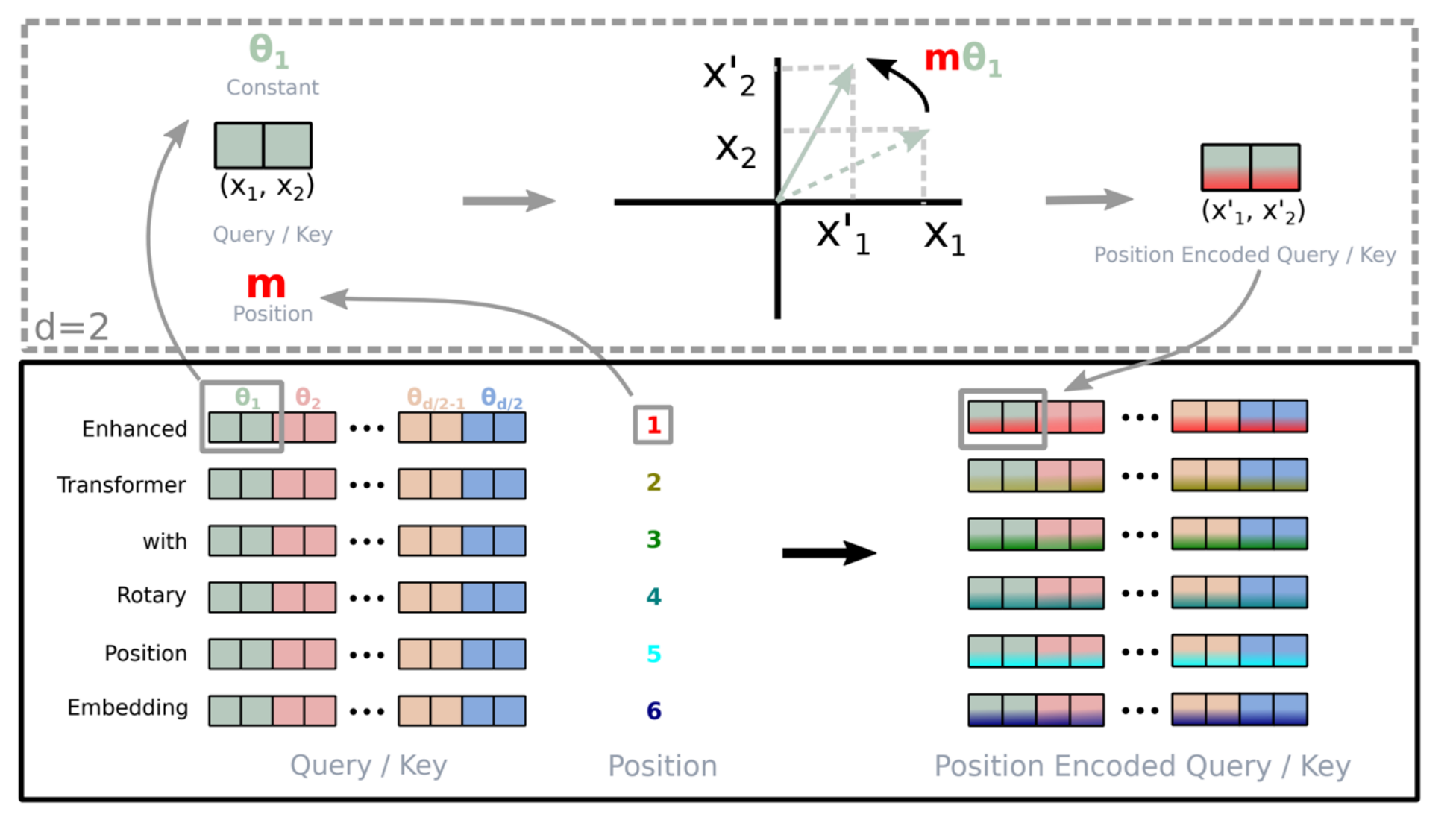
RoPE: Rotary Position Embeddings (旋转位置编码)
RoPE 是目前 SOTA 模型(如 LLaMA, PaLM, GPT-J)的标准配置。它的设计初衷是为了满足一个核心数学目标High level thought process: 寻找一个编码函数 \(f(x, i)\),使得两个向量的内积只取决于它们的相对距离 \(i-j\)。即: \[ \langle f(x, i), f(y, j) \rangle = g(x, y, i - j) \] RoPE 利用了向量内积对旋转保持不变的性质。
- 机制: RoPE 不在 Input Layer 进行,而是在 Attention 层对 \(Q\) 和 \(K\) 进行旋转操作。
- 做法: 将向量切分为二维平面上的对子 (Pairs)。对于位置 \(m\),将向量在平面上旋转 \(m\theta\) 角度。无论绝对位置在哪里,只要两个 Token 的相对距离固定,它们旋转后的相对夹角就是固定的,从而完美地通过内积捕捉相对位置信息。
Hyperparameters & Dimensions 超参数与维度
Attention Dimensions: The “1-1 Ratio”
在标准 Transformer 设计中,通常保持 Head_Dim \(\times\) Head_Num = Model_Dim (即 \(d_p \cdot h = d_{model}\))。
低秩瓶颈 (Low-Rank Bottleneck) 争议:
- 理论研究 [Bhojanapalli et al 2020] 认为,如果 Head_Dim (\(d_p\)) 太小,Attention 矩阵的秩会受限,导致模型无法表达某些复杂的关注模式。
- 理论建议:应该增加 Head 维度,打破 1-1 比例。
实践结论: 实验数据显示(如 Perplexity vs Parameters 曲线),尽管有理论争议,但在实际工程实践中,并没有观察到显著的低秩瓶颈。因此,保持标准的 1-1 比例仍然是最高效的选择。
FFN Dimension Scaling (GLU 变体缩放)
当使用 SwiGLU 等 GLU 变体时,由于引入了额外的门控矩阵 \(\boldsymbol{V}\)(参数量增加),为了保持总参数量与标准 Transformer 一致,需要缩小隐藏层维度 \(d_{ff}\)。
缩放规则: Scale down by \(2/3\)。 \[ d_{ff} = \frac{8}{3} d_{model} \] 这就是为什么 LLaMA 等模型的中间层维度通常是 \(d_{model}\) 的 2.67 倍左右,而不是传统的 4 倍。
Regularization 正则化
在训练超大规模模型时,正则化策略经历了从“防止过拟合”到“追求训练效率与稳定性”的理念转变,最显著的变化发生在 Dropout 的使用上。
Dropout
Dropout 曾是深度学习中标配的正则化手段,通过在训练过程中随机将神经元的输出置零,来防止神经元之间的共适应(Co-adaptation),从而减少过拟合。
现代趋势 (LLaMA / PaLM / Modern LLMs): 完全弃用 Dropout (Dropout rate = 0)。 目前的主流大模型(如 LLaMA 系列、PaLM)在预训练阶段通常不使用任何 Dropout。
弃用的原因:
- 数据量级 (Data Scale): 现代 LLM 在数万亿 Token 上训练,模型往往处于“欠拟合”状态(Underfitting),而不是过拟合。数据本身就是最好的正则化。
- 训练效率 (Memory & Speed): Dropout 需要存储随机掩码(Mask)以用于反向传播,这增加了显存开销(Memory Bandwidth)。在 FlashAttention 等算子优化中,移除 Dropout 可以显著提升计算吞吐量。
- 训练稳定性: 在极深的网络中,Dropout 引入的随机性有时会影响梯度的稳定性。
Weight Decay
虽然 Dropout 被抛弃了,但 Weight Decay 依然是优化器(如 AdamW)中不可或缺的一部分。
在 Loss 函数中增加一项惩罚,抑制权重矩阵的范数过大。把权重矩阵往回拉,避免过拟合。我们实际上是在对模型说:“除非这个特征真的特别重要,否则不要给它那么大的权重。” \[ \mathcal{L}_{total} = \mathcal{L}_{task} + \frac{\lambda}{2} \|\theta\|^2 \] 通用设置: 通常设置为 \(0.1\) (如 GPT-3, LLaMA, PaLM)。
选择性应用 (Selective Decay): 并不是所有参数都使用 Weight Decay。
- Apply: Linear Layers (Attention projections, FFN weights)。
- Skip: Bias 项、LayerNorm/RMSNorm 的缩放因子 \(\gamma\)、Embedding 层(有时)。对这些参数使用 Weight Decay 可能会破坏数值稳定性或模型对分布的适应能力。
Gradient Clipping
为了防止梯度爆炸(Exploding Gradients),这是现代 Transformer 训练的必须项。
机制: 监控全局梯度的 \(L_2\) 范数 (\(|g|\))。如果超过阈值 \(C\)(通常为 1.0),则对梯度进行缩放: \[ \text{if } \|g\| > C, \quad g \leftarrow g \cdot \frac{C}{\|g\|} \]
作用: 即使使用了 RMSNorm 和 QK-Norm,在训练初期或遇到“坏数据”时,Gradient Clipping 依然是保证训练不崩溃的最后一道防线。
Training Stability 训练稳定性
Gradient Norm & Attention Optimizations
现象: 未优化的模型(如 OLMo 0424)在训练中会出现频繁且剧烈的梯度尖峰 (Spikes),导致 Loss 曲线毛刺严重,训练甚至可能发散。
优化: 通过改进 Attention 计算(如 QK-Norm 或 Logit Softcapping),可以将梯度范数(L2 norm)压得非常低且平滑,从而实现极其稳定的训练过程。
QK-Norm (Query-Key Normalization)
在标准的 Attention 计算中,\(Q\) 和 \(K\) 是直接相乘的: \[ \text{Score} = \frac{Q K^T}{\sqrt{d}} \] 如果模型在训练过程中让 \(Q\) 或 \(K\) 的向量模长变得很大,那么它们的内积(点积)就会变得巨大。即使除以 \(\sqrt{d}\) 也无法抵消这种增长。
QK-Norm 的做法是在做矩阵乘法之前,先对 \(Q\) 和 \(K\) 分别应用 LayerNorm(或 RMSNorm): \[ Q' = \text{LayerNorm}(Q) \\ K' = \text{LayerNorm}(K) \\ \text{Score} = \frac{Q' (K')^T}{\sqrt{d}} \] 为什么它能稳定训练?
- 解耦模长与方向:Attention 的本质是计算向量的“相似度”(方向的一致性)。QK-Norm 强制将向量投影到一个固定的超球面上,消除了模长带来的干扰,让模型专注于学习向量的方向。
- 防止数值爆炸:由于 LayerNorm 将输出限制在特定的统计分布内(通常方差为1),\(Q \cdot K^T\) 的结果就被天然地限制在了一个合理的数值范围内,不会出现几千甚至上万的 Logits 值。
Logit Softcapping
这是 Gemma 2 和 OLMo 2用的关键技术。相比于 QK-Norm 对输入的归一化,Logit Softcapping 是对输出结果进行非线性截断。这个和下文的z-loss同属于对softmax稳定性的优化。
它的做法是利用 \(\tanh\) 函数将 Logits 限制在一个固定区间内(例如 \([-C, C]\))。 \[ \text{Logits}_{\text{capped}} = C \cdot \tanh\left(\frac{q^T k}{C \cdot \sqrt{d}}\right) \] 其中,\(C\) 是一个超参数(Cap value),通常设置为 30 或 50。
为什么它能稳定训练?
- 强制有界 (Hard Bound):\(\tanh(x)\) 的值域是 \((-1, 1)\)。当x趋于0时,\(\tanh(u) \approx u\), 能在数值小的时候保持线性, 此时该方法几乎不起作用,但当x很大时,\(\tanh\) 会趋于1或-1, 此时被限制在了 \([-C, C]\) 区间内。因此,无论 \(q^T k\) 算出来多大,最终的 Logits 绝对值永远不会超过 \(C\)。
- 防止 Softmax 熵崩溃:如果某个 Logit 值极大(比如 1000),经过 Softmax 后概率会变成 1(one-hot),其他的变成 0。导致梯度消失。Softcapping 保证了 Softmax 输出的概率分布保留了一定的熵(不确定性),让梯度能持续回传。
Output Softmax Stability: The “z-loss”
为了解决输出层 Softmax 的数值溢出问题(Logits 过大导致配分函数 \(Z(x)\) 爆炸),PaLM 引入了 z-loss trick。
原理: 在总 Loss 中增加一项辅助惩罚,鼓励配分函数
\(\log Z\) 接近 0,此时\(Z\) 接近 1。 \[
Z(x) = \sum_{i} e^{z_i} \\
L_{\text{total}} = L_{\text{original}} + 10^{-4} \cdot \log^2 Z
\] 应用: 该技巧主要用于 TPU/GPU 低精度
(bfloat16) 训练时的数值稳定性,已被 Baichuan 2, DCLM, OLMo
2 等模型广泛采用。
Attention Efficiency
随着模型上下文窗口的增大,推理时的显存占用和带宽成为了主要瓶颈。虽然 Transformer 的核心架构变动不大,但 Attention Heads 的设计为了效率做出了显著调整。
推理瓶颈:Incremental Generation & KV Cache
在文本生成阶段,模型是逐步生成 (Step-by-step) 的,无法并行。
KV Cache: 为了避免每次生成新 Token 时重复计算历史所有 Token 的 Attention,我们必须缓存之前所有 Token 的 Key 和 Value 矩阵。
显存压力: 随着序列变长,KV Cache 的体积会线性增长,甚至超过模型权重的显存占用。这限制了最大 Batch Size 和上下文长度。
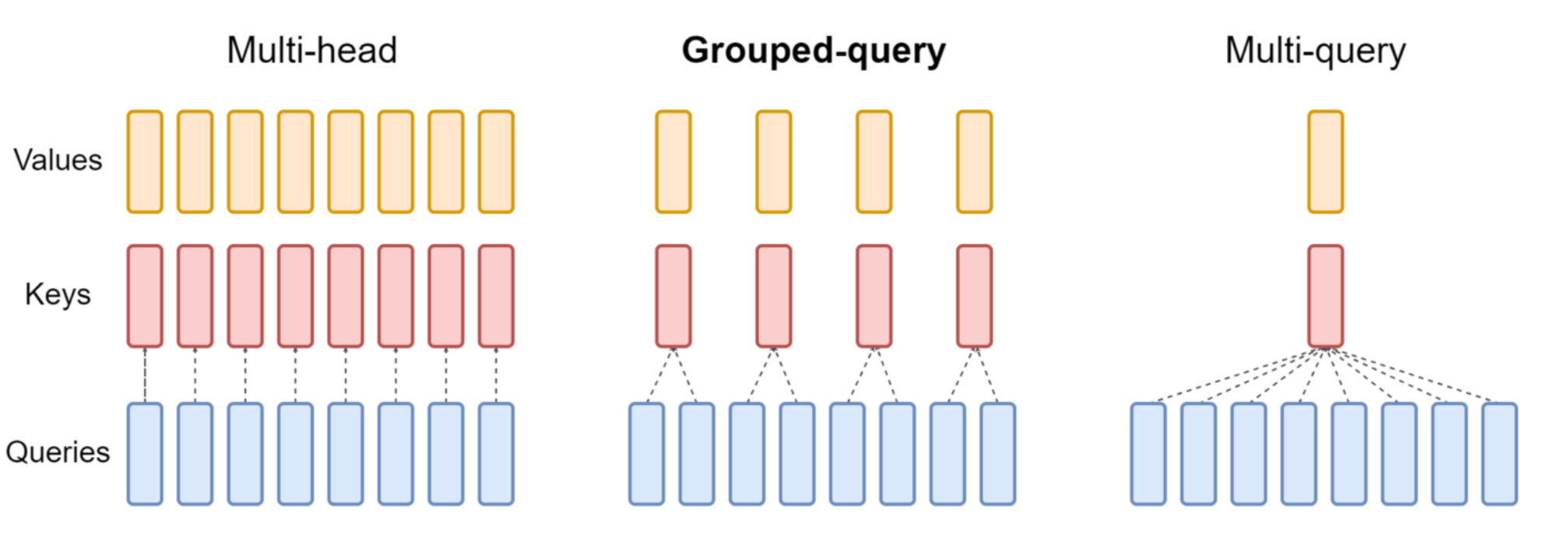
优化方案:GQA / MQA
为了解决 KV Cache 过大的问题,现代模型通过减少 Key/Value Head 的数量来降低推理成本。
- MQA (Multi-Query Attention):
- 机制: 所有 Query Heads 共享同一个 Key Head 和 Value Head。
- 优势: 极致的显存节省和推理加速。
- GQA (Grouped Query Attention):
- 机制: 将 Query Heads 分组,每组共享一个 KV Head。例如 LLaMA 2/3。
- 定位: 这是一个折中方案,平衡了推理效率和模型性能。
其他 Attention 变体
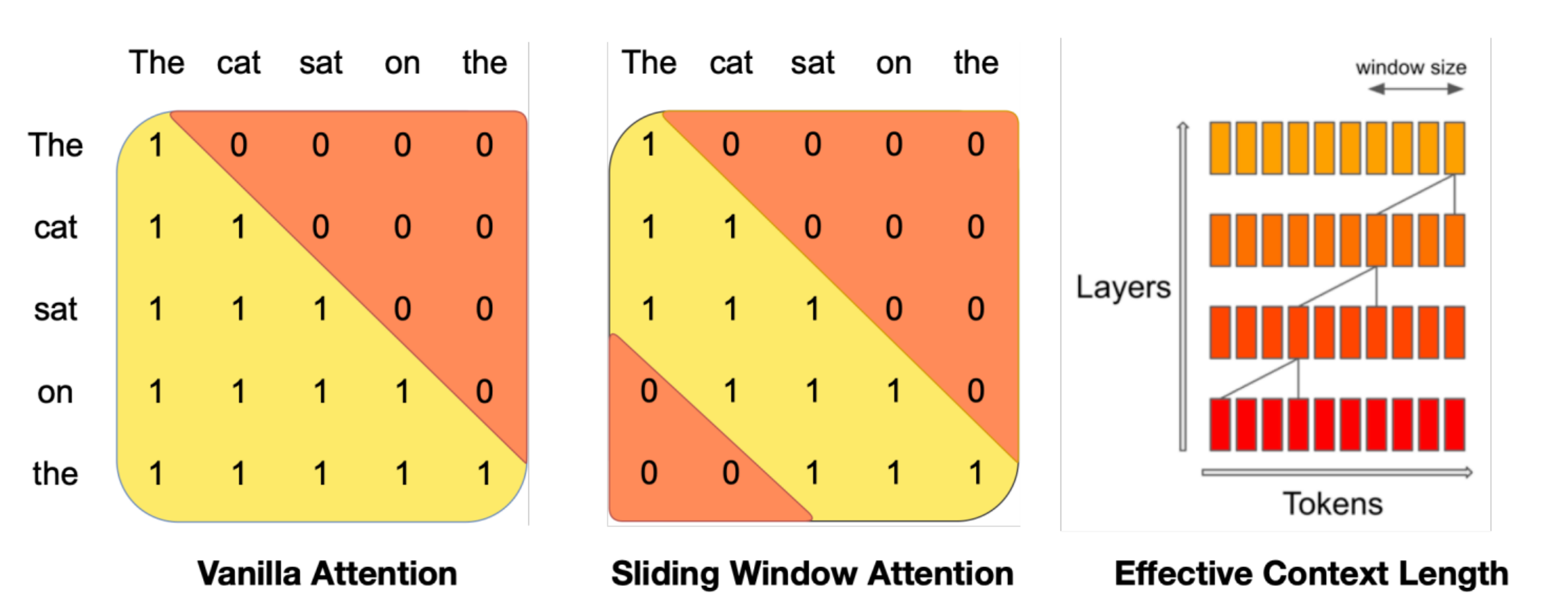
Sparse / Sliding Window Attention: 如 Mistral 和 GPT-4,通过限制 Attention 只看最近的窗口或稀疏点,将复杂度从 \(O(N^2)\) 降低,以处理超长文本。