CNNs - Part 1
卷积神经网络 (CNN) - 第1部分
首先,我们知道一些关于MLP(多层感知器)的事实:
- MLP是通用的函数逼近器。(布尔函数、分类器和回归)
- MLP可以通过梯度下降的变体进行训练
但我们如何满足平移不变性的需求,传统的MLP对模式的位置敏感,导致需要一个非常大的网络来覆盖模式的所有可能位置。因此,引入了CNN。
本讲座有两个场景:
- 1D输入(例如,时间序列)
- 2D输入(例如,图像)
常规网络与扫描网络
常规网络

在常规的MLP中,同一层中的每个神经元通过唯一的权重连接到前一层的每个单元。
- 权重矩阵中的所有条目都是唯一的
- 权重矩阵(通常)是满的
扫描网络
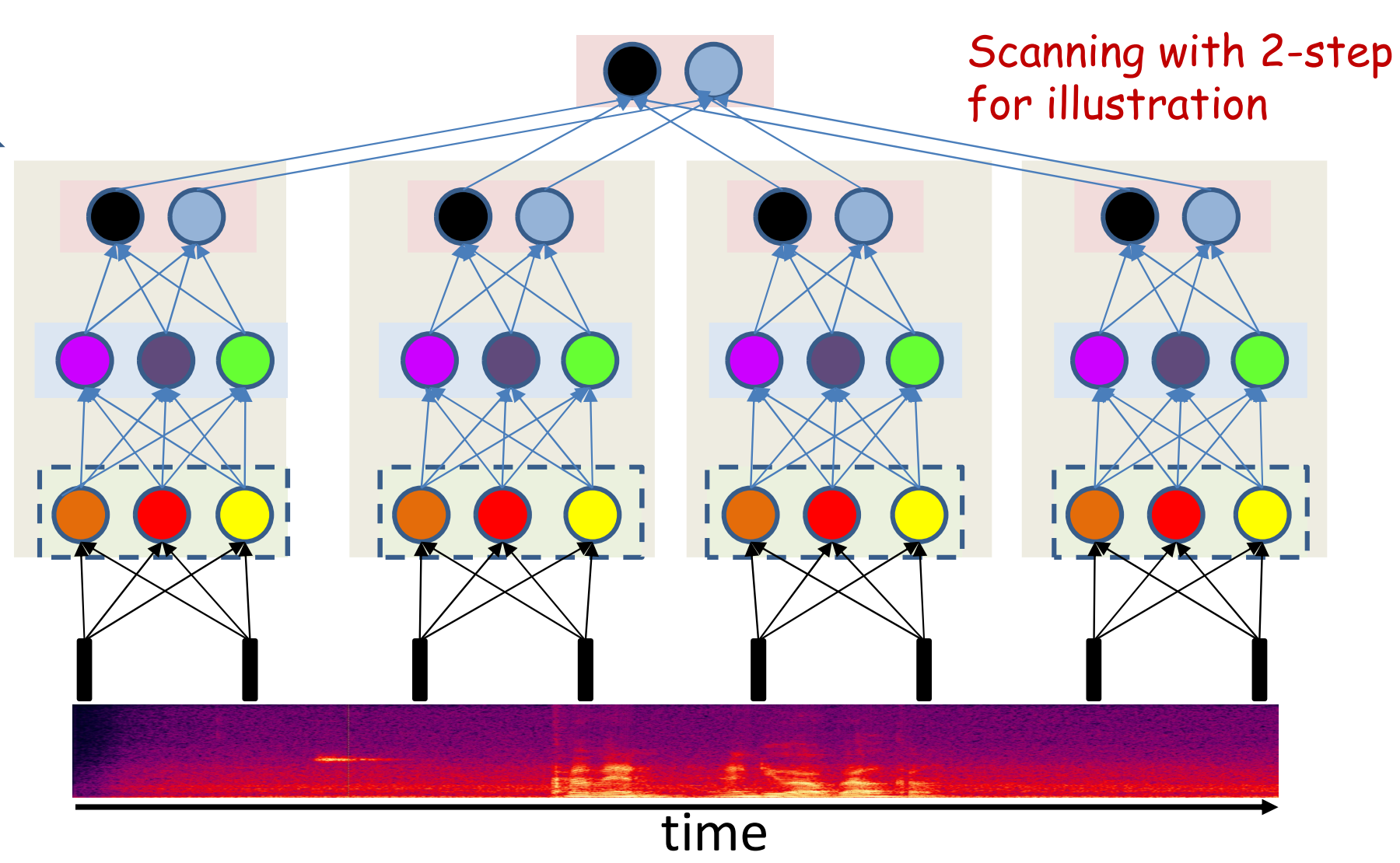
在扫描MLP中,每个神经元连接到前一层的一部分神经元。
- 权重矩阵是稀疏的
- 权重矩阵是具有相同块的块结构
- 网络是一个共享参数模型
扫描网络是我们在本讲座中的重点。
共享参数模型中的学习

1) 共享参数
多个连接被限制为具有相同的参数: \[ w_{ij}^k = w_{mn}^l = w^s \]
对于任何训练实例\(X\),\(w^s\)的微小扰动将同时扰动\(w_{ij}^k\)和\(w_{mn}^l\)。这些扰动将分别影响最终的散度(损失): \[ Div(d, y) \]
关于共享参数\(w^s\)的梯度等于关于每个共享权重的梯度之和: \[ \frac{\partial Div}{\partial w^s} = \frac{\partial Div}{\partial w_{ij}^k} \cdot \frac{\partial w_{ij}^k}{\partial w^s} + \frac{\partial Div}{\partial w_{mn}^l} \cdot \frac{\partial w_{mn}^l}{\partial w^s} \] 由于\(w_{ij}^k = w_{mn}^l = w^s\),这简化为: \[ \frac{\partial Div}{\partial w^s} = \frac{\partial Div}{\partial w_{ij}^k} + \frac{\partial Div}{\partial w_{mn}^l} \]
总之,关于共享参数的梯度是其每个实例的梯度之和。
2) 共享参数的梯度
\(S = \{e_1, e_2, ..., e_N\}\)是共享边的集合。因此,总梯度是集合中所有边的和: \[ \frac{\partial Div}{\partial w^s} = \sum_{e \in S} \frac{\partial Div}{\partial w^e} \]
然后关于\(w^s\)的损失梯度为 \[ \nabla_S \mathrm{Loss} = \frac{\partial \mathrm{Loss}}{\partial w^s} = \sum_{e \in S} \frac{\partial \mathrm{Loss}}{\partial w^{e}}. \]
3) 梯度下降更新
使用学习率\(\eta\),更新共享参数: \[ w^s \leftarrow w^s - \eta \ \nabla_S \mathrm{Loss}. \]
更新后,将新的共享值写回每个绑定的权重: \[ \forall (k,i,j)\in S:\quad w^{(k)}_{i,j} \leftarrow w^s. \]
4) 训练循环
- 初始化所有权重$ _1, _2, , _K $。
- 对于每个绑定集\(S\):
- 反向传播以获取每个边\(e\in S\)的$ $。
- 求和以获得$ _S $。
- 更新$ w^s w^s - , _S $。
- 将更新后的$ w^s \(同步回所有\) w^{(k)}_{i,j} S $。
- 重复直到损失收敛。
分布式与非分布式扫描
定义
- 分布式扫描:参数(权重)在空间位置之间共享。
→ 示例:在每个位置重用卷积核。 - 非分布式扫描:参数不共享;每个位置/块都有自己的一组权重。
关键区别
- 参数共享:分布式 ✅ | 非分布式 ❌
- 参数数量:
- 分布式:与位置数量无关;参数更少。
- 公式:\(K_0 D N_1 + K_1 N_1 N_2 + N_2 N_3\)
- 非分布式:随着位置数量线性增长(每个位置复制)。
- 分布式:与位置数量无关;参数更少。
- 归纳偏置:
- 分布式:强制平移等变性/不变性。
- 非分布式:没有这种偏置;更灵活但容易过拟合。
- 分布式:强制平移等变性/不变性。
- 输出排列:
- 分布式:自然生成与输入网格对齐的特征图。
- 非分布式:不需要遵循相同的形状(可以只收集输出)。
- 分布式:自然生成与输入网格对齐的特征图。
- 效率:
- 分布式:参数更少,更好的泛化,内存/计算更便宜。
- 非分布式:参数更多,成本高,扩展性差。
- 分布式:参数更少,更好的泛化,内存/计算更便宜。
- 实现类比:
- 分布式 ≈ 卷积(共享核)。
- 非分布式 ≈ 在每个位置应用独立的MLP。
- 分布式 ≈ 卷积(共享核)。
一句话总结
本质:分布式与非分布式扫描的区别在于权重是否在位置之间共享——这直接影响参数数量、泛化能力和效率。
CNN中的术语

滤波器(核):一个学习的权重张量\(W_c \in \mathbb{R}^{K_h \times K_w \times C_{\text{in}}}\)在每个位置重用;在\((u,v,c)\)处的输出:\(y(u,v,c)=\sigma(\langle \text{patch}(u,v), W_c\rangle + b_c)\)。
感受野:影响神经元输出的输入区域;每层(1D)\(r_l=r_{l-1}+(k_l-1)\,d_l\,j_{l-1}\),\(j_l=j_{l-1}s_l\),其中\(r_0=1, j_0=1\)。
步幅:在输入上滑动滤波器时的步长;较大的步幅会减少输出大小。

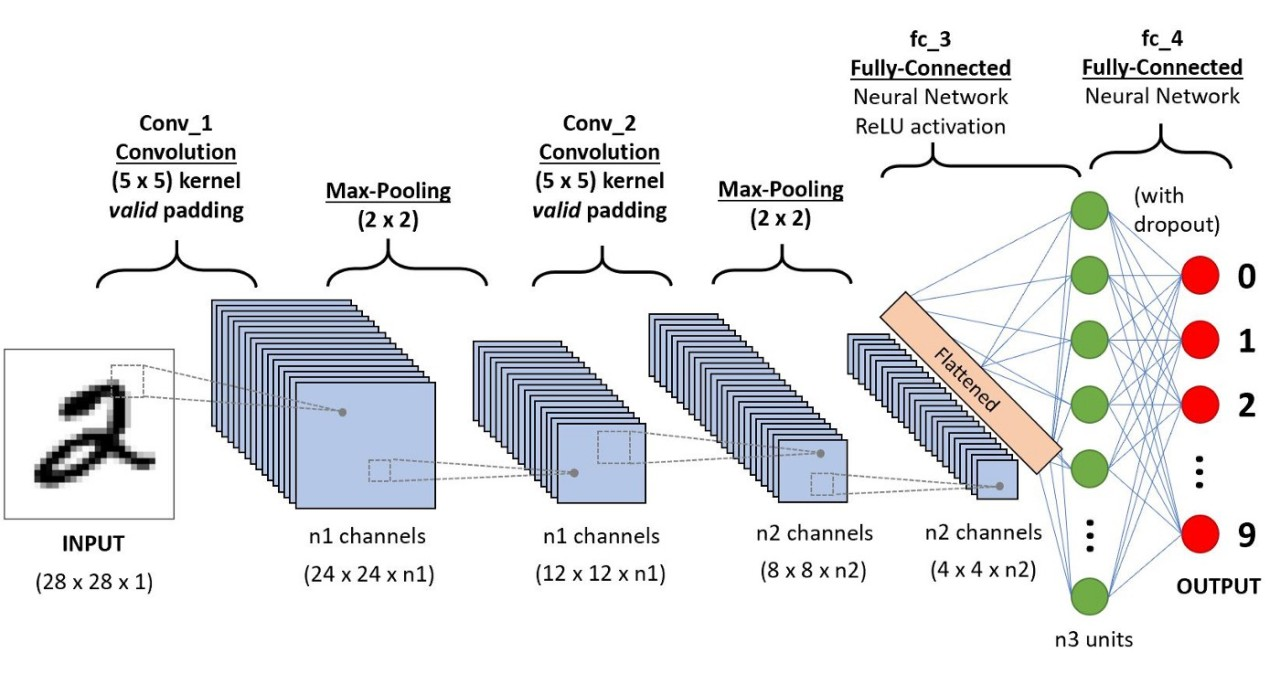
展平:将最终特征图从形状\(H \times W \times C\)重塑为长度为\(HWC\)的1-D向量(每个样本),然后输入全连接/softmax层。
带分类头:通过将嵌入\(z\)输入线性层+softmax(交叉熵)进行分类训练,在\(C\)个类别中预测一个ID。 不带分类头:用于验证,去掉线性/softmax,并用相似度(例如,余弦)比较两个嵌入\(z_1,z_2\)以决定匹配与不匹配(阈值/EER)。

池化:在卷积后对局部邻域进行下采样;
- 最大池化:\(y=\max(x_1,\dots,x_K)\)保留最强响应;
- 平均池化:\(y=\tfrac{1}{K}\sum_{i=1}^K x_i\)平滑;
两者都减少空间大小(步幅\(>1\))并增加小的平移/抖动不变性。
总结

- 神经网络以层次方式学习模式(简单→复杂)。
- 模式任务 =
使用共享参数网络(如CNN)扫描目标。
- 第一层扫描输入;更高层扫描之前的特征图;最后一层做出决策。
- 扫描可以分布在各层之间;可选的池化增加小的平移不变性。
- 2D扫描→卷积网络;沿时间的1D扫描→时间延迟神经网络(TDNN)。
附录