
Generic Programming and C++ Standard Template Library (STL)
泛型编程与 STL 结构
泛型编程的基本概念
指编写不依赖于特定数据类型的程序。模板是泛型编程的主要工具。
术语:概念
用于定义具有某些功能的数据类型。例如: * “所有可以比较(使用比较运算符)的数据类型”的概念表示为 Comparable * “具有公共复制构造函数并可以使用 ‘=’ 赋值的数据类型”的概念表示为 Assignable * “所有可以比较、具有公共复制构造函数并可以使用 ‘=’ 赋值的数据类型”的概念表示为 Sortable。
对于两个不同的概念 A 和 B,如果概念 A 所需的所有函数也被概念 B 所需,则称概念 B 是概念 A 的子概念。例如: * Sortable 是 Comparable 和 Assignable 的子概念
实际上,这个子概念类似于从基类派生的类。
术语:模型
模型:符合某个概念的数据类型称为该概念的模型 * int 类型是 Comparable 概念的模型; * 静态数组类型不是 Assignable 概念的类型(静态数组不能被赋值)。
使用概念作为模板参数名称
- 许多 STL 实现代码使用概念来命名模板参数。
- 给一个概念命名,并将该名称用作模板参数名称。
例如: 表示一个函数模板的原型,如 insertionSort: 1
2template <class Sortable>
void insertionSort(Sortable a[], int n);
STL 介绍
标准模板库提供了一些非常常用的数据结构和算法。
STL 的基本组成部分: * 容器 * 迭代器 * 函数对象 * 算法
基本关系: * 迭代器是算法与容器之间的桥梁。使用迭代器作为算法参数,通过迭代器访问容器,而不是直接将容器作为算法参数传递; * 使用函数对象作为算法参数,而不是将函数执行的操作作为算法的一部分。
关系图:
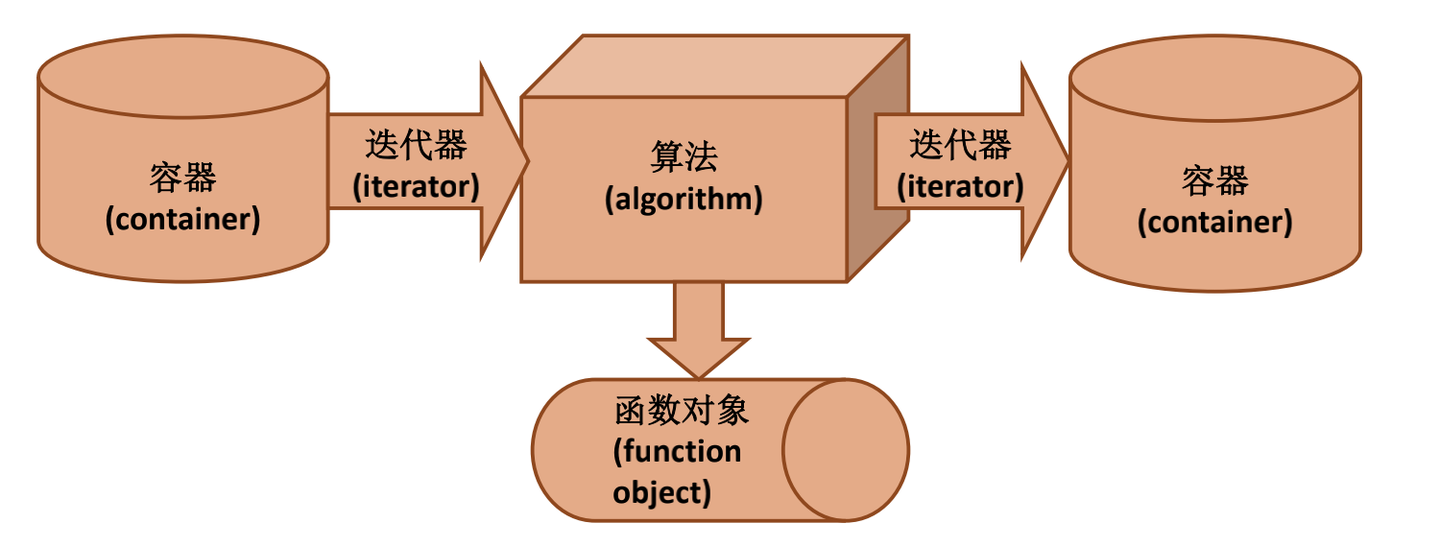
STL 的基本组成部分 - 容器
容器是保存一组元素的对象。容器类库包括七种基本容器:vector、deque、list、set、multiset、map 和 multimap。
- 顺序容器:array、vector、deque、forward_list(单链表)、list(双链表);
- 有序关联容器:set、multiset、map、multimap;
- 无序关联容器:unordered_set、unordered_multiset、unordered_map、unordered_multimap。
容器适配器:stack、queue、priority_queue(优先队列,底层是最大或最小二叉堆)
要使用容器,您需要包含相应的头文件。
STL 的基本组成部分 - 迭代器
- 迭代器是通用指针,提供对容器中每个元素的顺序访问方法;
- 提供对容器中每个元素的顺序访问方法;
- 可以使用 “++” 运算符获取指向下一个元素的迭代器;
- 可以使用 “*” 运算符访问迭代器指向的元素。如果元素类型是类或结构体,还可以使用 “->” 运算符直接访问该元素的成员;
- 一些迭代器还支持通过 “–” 运算符获取指向前一个元素的迭代器;
- 迭代器是通用指针:指针具有相同的特性,因此指针本身是一种迭代器;
- 要独立于 STL 容器使用迭代器,您需要包含头文件
<iterator>。
STL 的基本组成部分 - 函数对象
- 行为像函数的对象,可以像函数一样被调用。
- 函数对象是通用函数:任何普通函数和任何重载了 “()” 运算符的类的对象都可以用作函数对象。
- 要使用 STL 函数对象,您需要包含头文件
<functional>。
STL 的基本组成部分 - 算法
- STL 包含超过 70 种算法,例如:排序算法、消除算法、计数算法、比较算法、变换算法、排列算法和容器管理;
- 可以广泛用于不同对象和内置数据类型;
- 要使用 STL 算法,您需要包含头文件
<algorithm>。
算法示例 - transform 算法
transform 算法顺序遍历由两个迭代器 first 和 last 指向的元素; * 使用每个元素的值作为函数对象 op 的参数; * 通过迭代器 result 顺序输出 op 的返回值; * 遍历完成后,result 迭代器指向最后一个输出元素之后的位置,transform 将返回该迭代器。
例如,以下可能是 transform 算法的一种实现: 1
2
3
4
5
6
7
8
9template <class InputIterator, class OutputIterator, class UnaryFunction>
OutputIterator transform(InputIterator first, InputIterator last, OutputIterator result, UnaryFunction op)
{
for (;first != last; ++first, ++result)
{
*result = op(*first);
}
return result;
}
示例: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//从标准输入读取几个整数,存储在 vector 容器中,输出它们的负值
using namespace std;
int main()
{
const int N = 5;
vector<int> s(N);
for (int i = 0; i < N; i++)
{
cin >> s[i];
}
transform(s.begin(),s.end(), ostream_iterator<int>(cout," "),negate<int>());
cout << endl;
return 0;
}
迭代器
迭代器是算法与容器之间的桥梁: * 迭代器用于访问容器中的元素 * 算法不直接操作容器中的数据,而是通过迭代器间接操作
算法与容器是独立的: * 添加新算法不会影响容器实现 * 添加新容器时,现有算法仍然可以应用
输入流迭代器和输出流迭代器
输入流迭代器 * istream_iterator<T> * 以输入流(如
cin)作为参数构造 * 可以使用 (p++) 获取下一个输入元素 输出流迭代器
ostream_iterator<T> * 构造时需要提供输出流(如
cout) * 可以使用 (*p++) = x 将 x 输出到输出流
两者都属于适配器 * 适配器是用于为现有对象提供新接口的对象 * 输入流适配器和输出流适配器为流对象提供迭代器接口
程序示例: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//从标准输入读取几个实数,输出它们的平方
using namespace std;
double square(double x)
{
return x * x;
}
int main()
{
transform(istream_iterator<double>(cin),istream_iterator<double>(),ostream_iterator<double>(cout,"\t"),square);
//istream_iterator<double>() 调用输入流迭代器的默认构造函数,使其指向输入流的结束位置。
cout << endl;
return 0;
//如果不手动终止程序,它将一直运行,因为输入流始终在等待您的输入
}
迭代器分类
按访问方法分类: 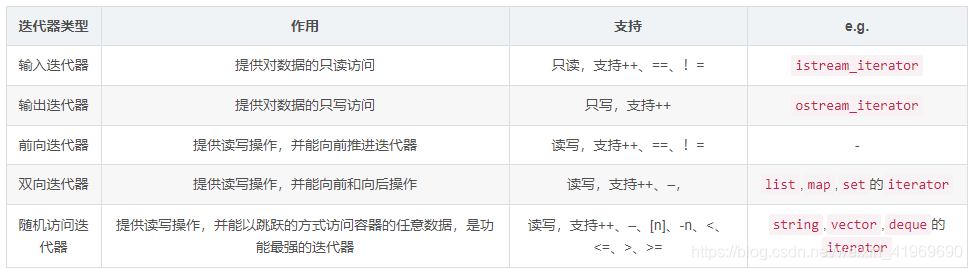
关系图: 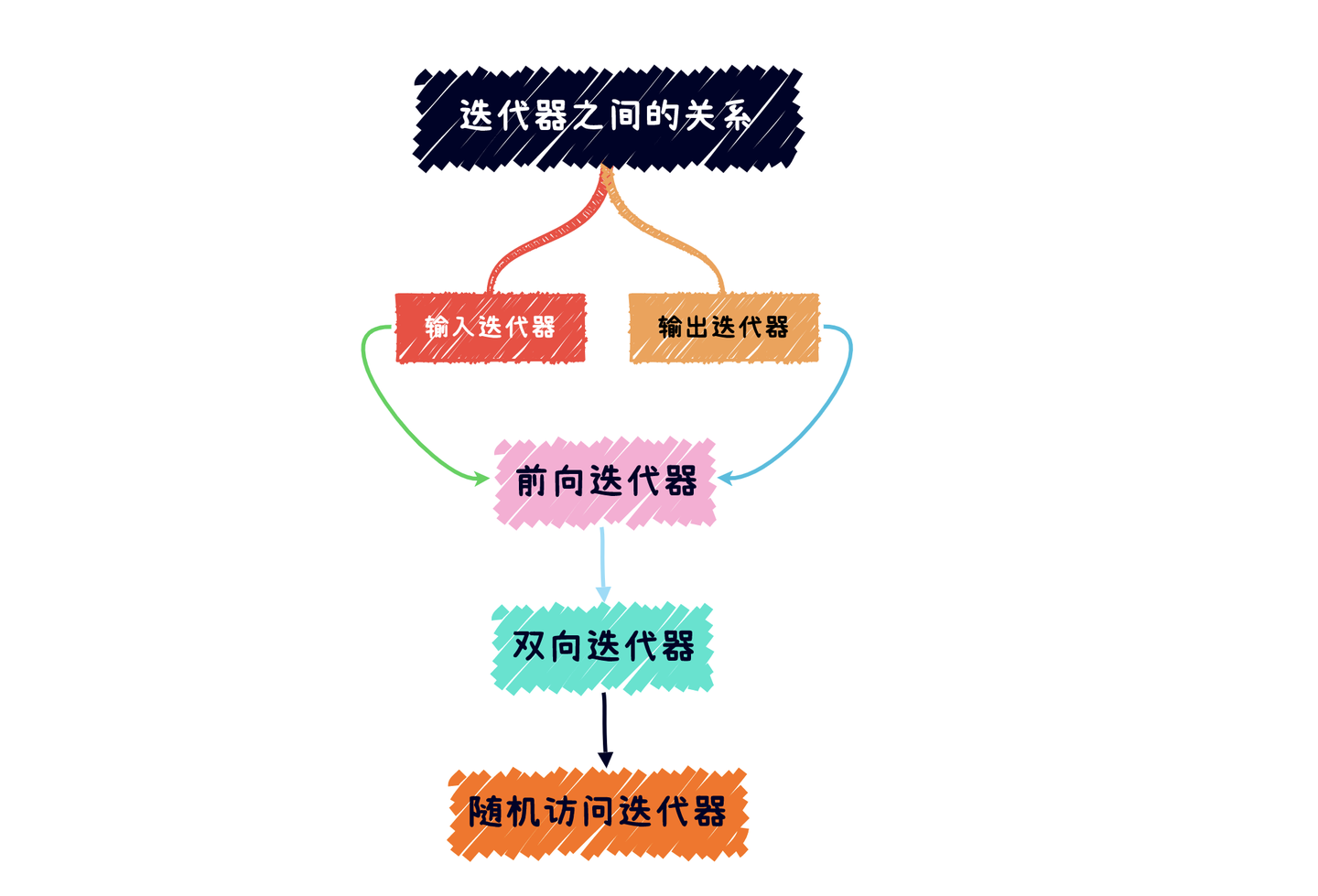
按操作类型分类: 
迭代器范围
- 两个迭代器表示一个范围:[p1, p2),范围包括 p1 但不包括 p2;
- STL 算法通常使用迭代器范围作为输入来传递输入数据;
- 有效范围:p1 在 n 次(n > 0)递增(++)操作后满足 p1 == p2。
程序示例: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31//各种迭代器综合使用的示例
using namespace std;
template <class T, class InputIterator, class OutputIterator>
void mySort(InputIterator first, InputIterator last, OutputIterator result)
{
vector<T> s;
while (first != last)
{
s.push_back(*first);
first++;
}
sort(s.begin(), s.end()); //sort 参数必须是随机访问迭代器
copy(s.begin(), s.end(), result);
}
int main()
{
double a[5] = {1.2, 2.4, 0.8, 3.3, 3.2};
//排序已知数组
mySort<double>(a, a + 5, ostream_iterator<double>(cout, " "));
cout << endl;
//从标准输入读取几个整数,输出排序结果
mySort<int>(istream_iterator<int>(cin), istream_iterator<int>(), ostream_iterator<int>(cout, " "));
cout << endl;
return 0;
}
迭代器辅助函数
- advance(p,n):对 p 执行 n 次增量操作
- distance(first,last):计算两个迭代器 first 和 last 之间的距离
容器
容器的基本功能和分类
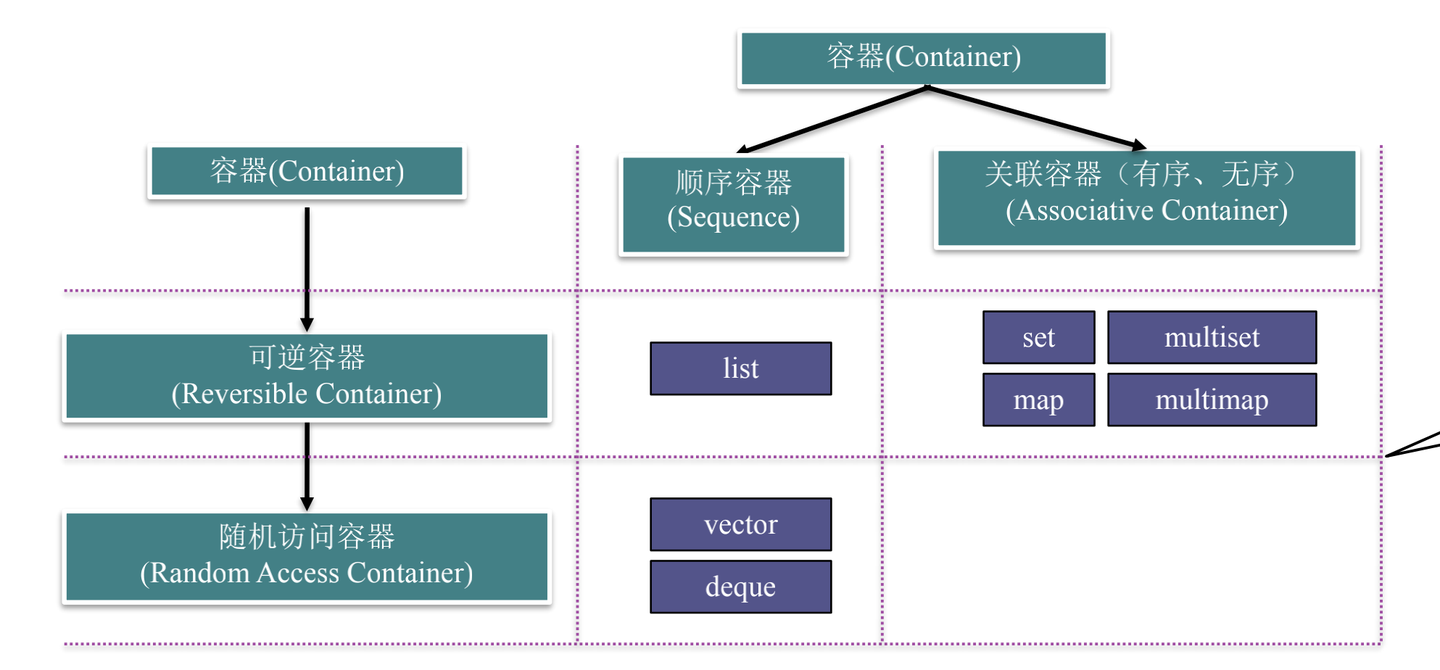
容器的常用功能 * 使用默认构造函数构造空容器 * 支持关系运算符:==、!=、<、<=、>、>= * begin()、end():获取容器的头尾迭代器(实际上指向容器最后一个元素之后的元素) * cbegin()、cend():获取容器的头尾常量迭代器,在不改变容器时更安全 * clear():清空容器 * empty():检查容器是否为空 * size():获取容器中元素的数量 * s1.swap(s2):交换容器 s1 和 s2 的内容
相关数据类型(S 表示容器类型) * S::iterator:指向容器元素的迭代器类型 * S::const_iterator:常量迭代器类型
使用一般容器的 begin()/end(),获得的迭代器都是前向迭代器,而可逆容器提供双向迭代器。
实际上,STL 模板提供的标准容器至少是可逆容器,但一些非标准模板库提供的容器如 slist(单链表)仅提供前向迭代器。
访问可逆容器
STL 为每个可逆容器提供反向迭代器,可以通过以下成员函数获得: * rbegin():指向容器末尾的反向迭代器 * rend():指向容器开头的反向迭代器
反向迭代器的类型名称表示如下(S 表示容器类型): * S::reverse_iterator:反向迭代器类型 * S::const_reverse_iterator:常量反向迭代器类型
反向迭代器是普通迭代器的适配器,其中反向迭代器的 ++ 被映射到前向迭代器的 –。
细节: 迭代器及其反向迭代器可以相互转换。例如:如果 p1 是类型 S::iterator 的迭代器,则使用表达式 S::reverse_iterator(p1) 可以获得与 p1 对应的反向迭代器;也可以使用 base 函数获取与反向迭代器对应的普通迭代器,例如:r1 是通过 S::reverse_iterator(p1) 构造的反向迭代器,则 r1.base() == p1。但 r1 和 p1 不指向同一个元素,r1 指向的元素始终与 p1-1 指向的元素相同。
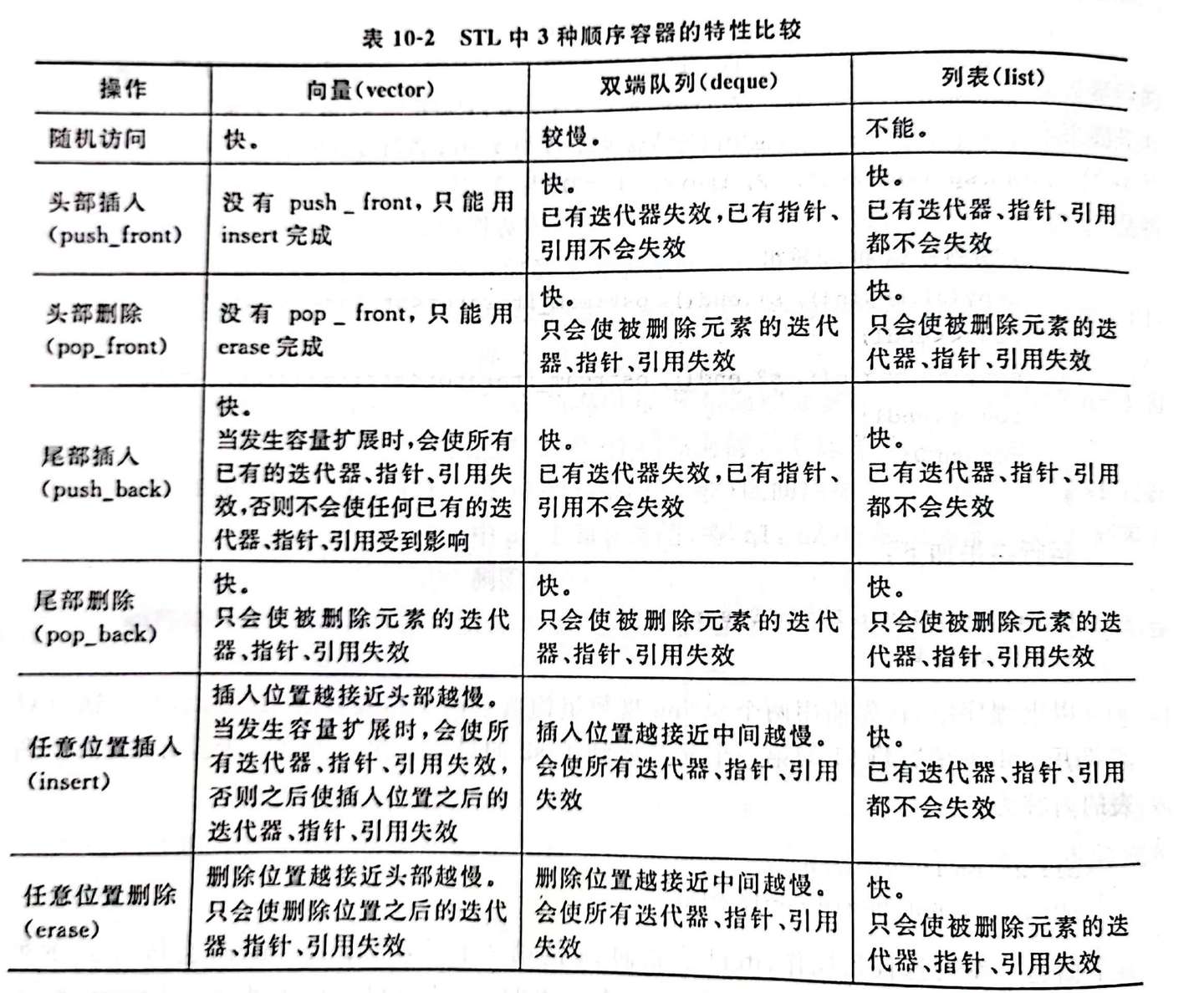
顺序容器
STL 中的顺序容器 * vector * deque * list * forward_list * array
- 元素线性排列,可以随时在指定位置插入和删除元素。
- 必须符合 Assignable 概念(即具有公共复制构造函数并可以使用 “=” 赋值)。
- array 对象具有固定大小,forward_list 具有特殊的添加和删除操作。
顺序容器接口
不包括单链表(forward_list)和数组
- 构造函数
- 列表初始化,例如
vector<int> arr = {1,4,5,7};
- 赋值函数
- assign
- 插入函数
insert(iterator pos, const T& v),在 pos 位置插入后,返回新插入元素的迭代器;- push_front(仅适用于 list 和 deque)、push_back;
- emplace_front、emplace 和 emplace_back,这些操作将元素构造而不是复制到容器中,这些操作分别对应 push_front、insert 和 push_back,允许我们将元素放置在容器的头部、指定位置和尾部。
- 删除函数
- erase、clear、pop_front(仅适用于 list 和 deque)、pop_back
- 直接访问头部和尾部元素
- front、back
- 改变大小
- resize
请记住,头部操作不适合具有连续物理地址的数据结构。
Vector
特性: * 可扩展的动态数组 * 快速随机访问,快速在尾部插入或删除 * 中间或头部插入或删除较慢
Vector 容量:实际分配空间的大小 * s.capacity():返回当前容量 * s.reserve(n):如果容量小于 n,则扩展 s 使其容量至少为 n * s.shrink_to_fit():回收未使用的元素空间,即 size 和 capacity 函数返回值相等
失效: 如果添加元素导致 vector 扩展,则所有迭代器、指针和引用将失效,因为内存空间被重新分配;如果没有扩展,则仅插入(或删除)元素之后的迭代器将失效(因为元素被移动)。
Deque
特性 * 快速在两端插入或删除 * 中间插入或删除较慢 * 随机访问更快,但比 vector 容器慢
Deque 是许多 STL 实现中的分段数组。容器中的元素存储在固定大小的数组段中。此外,容器需要维护一个索引数组,存储这些分段数组的第一个地址,因此 deque 的连续性是一种幻觉。

1 | //首先按降序输出奇数,然后按升序输出偶数。 |
List
底层逻辑是双向链表。
特性 * 在任何位置快速插入和删除元素 * 不支持随机访问
拼接操作 s1.splice(p, s2, q1, q2) 意味着将 [q1, q2) 从
s2 移动到 s1 中指向 p 的元素之前
Forward List
特性: * 单链表中的每个节点仅有指向下一个节点的指针,没有简单的方法获取节点的前驱; * 不定义 insert、emplace 和 erase 操作,但定义了 insert_after、emplace_after 和 erase_after 操作。它们的参数与 list 的 insert、emplace 和 erase 相同,但它们不插入或删除指向迭代器 p1 的元素,而是对 p1 指向的元素之后的节点进行操作; * 不支持 size 操作。
Array
特性: * array 是对内置数组的封装,提供了一种更安全和方便的使用数组的方法 * array 对象的大小是固定的。在定义时,需要指定元素类型和容器大小。 * 不能动态改变容器大小
顺序容器插入迭代器和适配器
顺序容器插入迭代器
概念:用于在容器的头部、尾部或中间指定位置插入元素的迭代器,包括前插入器(front_inserter)、后插入器(back_inserter)和任意位置插入器(inserter)。
1 | list<int> s; |
顺序容器适配器
基于顺序容器构建一些常用的数据结构,是顺序容器的封装: * Stack:第一个压入的元素最后弹出 * Queue:第一个压入的元素第一个弹出 * Priority queue:首先弹出“最大”的元素
Stack 可以使用任何顺序容器作为基础容器,但 queue 仅允许前插入的顺序容器(deque 或 list)
优先队列的本质是最大(最小)二叉堆。
Stack 和 Queue 支持的常见操作
- s1 op s2 op 可以是 ==、!=、<、<=、>、>= 之一,它比较两个容器适配器之间的元素,按字典顺序;
- s.size() 返回 s 中的元素数量;
- s.empty() 返回 s 是否为空;
- s.push(t) 将元素 t 压入 s;
- s.pop() 从 s 中弹出一个元素。对于 stack,每次弹出的元素是最后压入的元素,而对于 queue,每次弹出的元素是第一个压入的元素;
- 不支持迭代器,因为它们不允许访问任意元素。
Stack 和 Queue 的不同操作
Stack 操作: * s.top() 返回对 stack 顶部元素的引用
Queue 操作: * s.front() 获取对队列头部元素的引用 * s.back() 获取对队列尾部元素的引用
优先队列
优先队列也支持像 stack 和 queue
一样的元素压入和弹出,但元素弹出的顺序与元素大小有关。每次弹出的元素始终是容器中的“最大”元素。
1
2template <class T, class Sequence = vector<T>
class priority_queue;
关联容器
关联容器的分类和基本功能
对于关联容器,每个元素都有一个键,容器中元素的顺序按键值的升序排列。
与顺序容器不同,查找元素的时间复杂度为 \(O(n)\),关联容器根据键大小将元素组织成平衡二叉树,时间复杂度为 \(O(\log n)\)。
有序关联容器的分类: * 单一关联容器(set 和 map) *
键值是唯一的,一个键值只能对应一个元素
* 多重关联容器(multiset 和 multimap) *
键值是不唯一的,一个键值可以对应多个元素
* 简单关联容器(set 和 multiset) *
容器只有一个类型参数,如
set
接口 * 构造:列表初始化,例如
map<string, int> id_map = {{"Xiao Ming", 1}, {"Li Hua", 2}} *
插入:insert * 删除:erase * 查找:find *
边界:lower_bound、upper_bound、equal_range * 计数:count
C++11 新标准定义了 4 种无序关联容器 unordered_set、unordered_map、unordered_multiset、unordered_multimap * 不使用比较运算符来组织元素,而是通过哈希函数和键类型的 == 运算符。 * 提供与有序容器相同的操作 * 可以直接使用内置类型关键字定义无序容器。 * 不能直接使用自定义类键类型定义无序容器。如果需要,必须提供我们自己的哈希模板。
Set
Set 用于存储一组不重复的元素。由于 set 的元素是有序的,因此可以高效地查找指定元素,并方便地获取容器中指定大小元素的范围。
1 | pair<set<double>::iterator,bool> r=s.insert(v); |
Map
Map 和 set 都属于单一关联容器。它们的主要区别在于 set 的元素类型是键本身,而 map 的元素类型是由键和附加数据组成的二元元组。
在 set 中通过键查找元素时,通常仅用于确定元素是否存在,而在 map 中通过键查找元素时,除了确定其存在性外,还可以获取相应的附加数据。
1 | courses.insert(make_pair("CSAPP", 3)); |
Multiset 和 Multimap
Multiset 是一个允许重复元素的集合,而 multimap 是一个允许一个键对应多个附加数据的映射。
Multiset 和 set、multimap 和 map 的用法相似,仅在少数成员函数上有细微差别。区别主要体现在移除键必须唯一的限制。
函数对象
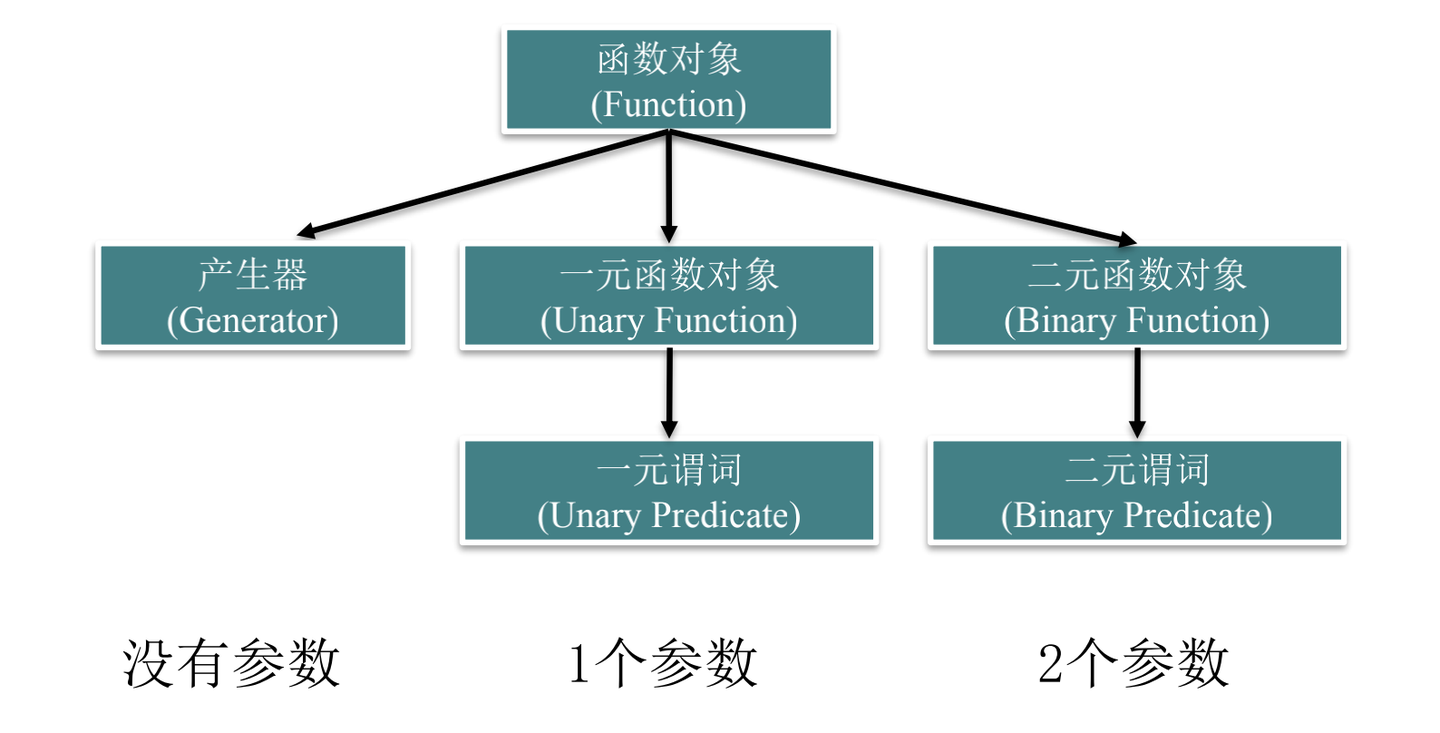
函数对象的基本概念和分类
函数对象实际上是行为像函数的对象。它们可以没有参数或有多个参数,其功能是获取值或改变操作的状态。
任何普通函数和任何重载调用运算符 operator() 的类的对象都满足函数对象的特性
以下是两个结果相同的程序: 1
2
3
4
5
6
7
8
9
10
11
using namespace std;
//定义一个普通函数
int mult(int x, int y) { return x * y; };
int main() {
int a[] = { 1, 2, 3, 4, 5 };
const int N = sizeof(a) / sizeof(int);
cout << "将 a 中所有元素相乘的结果是 " << accumulate(a, a + N, 1, mult) << endl;
return 0;
}
1 |
|
一个普通函数,一个类重载了 ()。
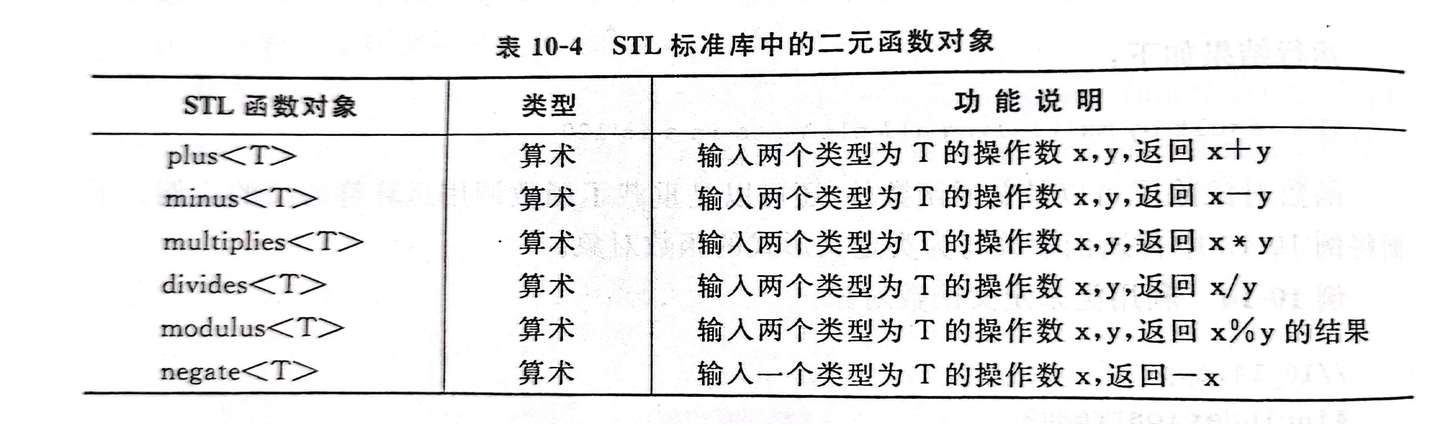
STL 提供的函数对象: * 算术运算的函数对象 * 关系运算和逻辑运算的函数对象(要求返回值为 bool)

Lambda 表达式
Lambda 表达式详细信息 定义:[捕获列表](参数列表)-> 返回类型 {函数体} * 捕获列表可以捕获 lambda 所在函数的局部变量 * 参数列表、返回类型和函数体与普通函数一致 * 可以在函数内部定义,理解为无名内联函数 * auto lambda = [] { return “Hello World!”; }; * cout<< lambda() <<std::endl; //执行与函数对象一致
捕获列表有值捕获、引用捕获和隐式捕获方法 * int size = 10, base = 0;
//局部变量 * auto longer = size{return s.size()>size;}
//值捕获 * auto longer = &size{return
s.size()>size;}//引用捕获 * auto longer = ={return
s.size()>base;}//隐式值捕获 * auto longer = &{return
s.size()>size;}//隐式引用捕获 ## 函数适配器 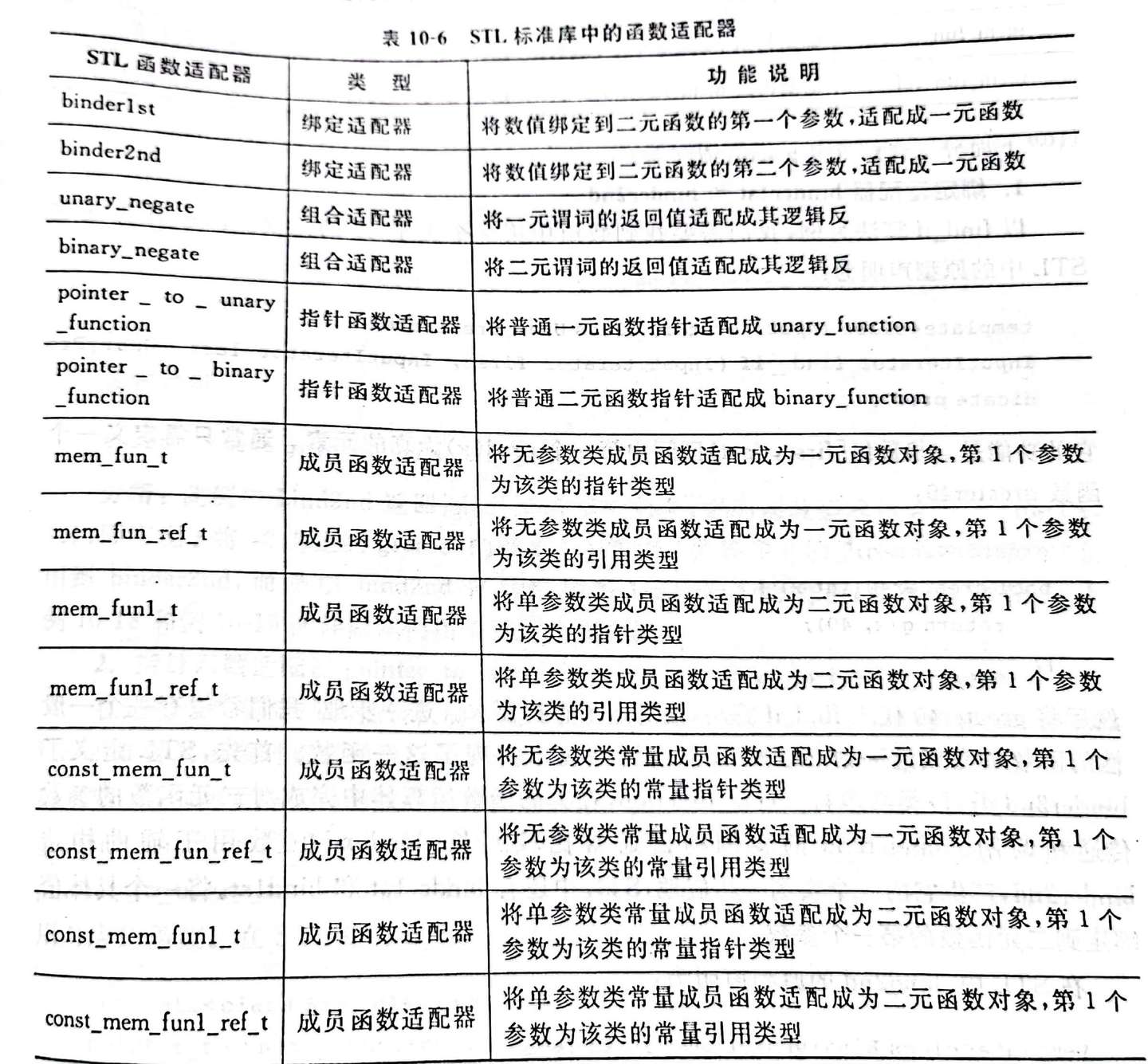
bind2nd 生成 binder2nd 函数适配器的实例 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
using namespace std;
using namespace placeholders; //占位符 _n 的命名空间
int main()
{
int intArr[] = { 30, 90, 10, 40, 70, 50, 20, 80 };
const int N = sizeof(intArr) / sizeof(int);
vector<int> a(intArr, intArr + N);
auto p = find_if(a.begin(), a.end(),bind2nd(greater<>(), 40));
if (p == a.end())
cout << "没有大于 40 的元素" << endl;
else
cout << "第一个大于 40 的元素是: " << *p << endl;
return 0;
}
函数模板的内容远不止这些,逐步在实践中学习
算法
算法的特征: * STL 算法本身是函数模板 * 通过迭代器获取输入数据 * 通过函数对象处理数据 * 通过迭代器输出结果 * STL 算法是通用的,与特定数据类型和容器类型无关
算法分类: * 不可变序列算法 * 可变序列算法 * 排序和搜索算法 * 数值算法
代码中使用的所有算法都可以在图像中找到,因此不再解释。
不可变序列算法
不直接修改操作容器内容的算法,用于查找指定元素、比较两个序列是否相等、计数元素等。

示例: 1
2
3template<class InputIterator, class UnaryPredicate>
InputIterator find_if(InputIterator first, InputIterator last, UnaryPredicate pred;
//在 [first, last) 范围内查找第一个使 pred(x) 为真的元素
可变序列算法
可以修改它们操作的容器对象,包括复制、删除、替换、反转、旋转、交换、分区、去重、填充、洗牌序列和生成序列的算法。


示例: 1
2
3template<class ForwardIterator, class T>
void fill(ForwardIterator first, ForwardIterator last, const T& x);
//将 [first, last) 范围内的所有元素重写为 x。
删除是通过移动(通过 copy assignment (直到 C++11)move assignment (自 C++11 起))范围内的元素,以使不需要删除的元素出现在范围的开头。保留的元素的相对顺序保持不变,容器的物理大小不变。指向新逻辑结束和物理结束之间的元素的迭代器仍然可以解引用,但元素本身具有未指定的值(根据 MoveAssignable 后置条件)。
排序和搜索算法
- 对序列进行排序
- 合并两个有序序列
- 搜索有序序列
- 对有序序列进行集合操作
- 堆算法


1 | template <class RandomAccessIterator , class UnaryPredicate> |
sort 要求 first 和 last 为随机迭代器类型,因为 sort 的具体实现使用快速排序,使用随机迭代器是出于效率考虑。
数值算法
查找序列中元素的“和”、部分“和”、相邻元素的“差”或两个序列的内积。查找“和”的“+”、查找“差”的“-”以及查找内积的“+”和“·”都可以通过函数对象指定。

示例: 1
2
3template<class InputIterator, class OutputIterator, class BinaryFunction> ▫ OutputIterator partial_sum(InputIterator first, InputIterator last, OutputIterator result, BinaryFunction op);
//查找 [first, last) 范围内元素的部分“和”(所谓部分“和”是与输入序列长度相同的序列,其中第 n 项是输入序列前 n 个元素的“和”)
//使用函数对象 op 作为 "+" 运算符,通过 result 输出结果,返回指向输出序列最后一个元素之后的迭代器
综合示例 - 银行账户管理







