
Makefile Introduction
Makefile 概念介绍
本文主要介绍如何使用“基于目标的分层”方法来理解一个工具,编写概念,定义设计或部署一组代码。
本文首先是“Makefile 介绍”,然后是“基于目标的分层方法介绍”。
关于程序编译
Makefile 解决的是编译的问题。Makefile 最初是用来解决 C 语言的编译问题的,所以与 C 的关系特别密切,但并不是说 Makefile 只能用来解决 C 的编译问题。你用来处理 Java 一点问题没有,但对于 Java,显然 ant 比 Makefile 处理得更好。
比如说,你有 foo.c、bar.c、main.c 三个 C 文件,你要编译成一个 app.executable,你会怎么做呢?你会执行这样的命令:
1 | gcc -Wall -c foo.c -o foo.o |
按照程序员的惯例,凡是要一次次重新执行的命令,都应该写成脚本。所以,简单来说,你会把上面这个命令序列写成一个 build.sh,每次编译你只要执行这个脚本问题就解决了。
但这个脚本有问题,假设我修改了 foo.c,但我没有修改 bar.c 和 main.c,那么执行这个脚本是很浪费的,因为它会无条件也重新编译 bar.c 和 main.c。
这个脚本更合理的写法应该是这样的:
1 | [ foo.o -ot foo.c ] && gcc -Wall -c foo.c -o foo.o |
如果你面对一个问题,不要尝试重新去定义这个问题,而是看它和原来的问题相比,多出来的问题是什么,尝试解决那个多出来的问题就好了。那么这里,多出来的问题就是文件修改时间比较。这个就是 Makefile 要解决的基本问题了。我们定义一种新的“脚本语言”(只是不用 sh/bash/tch 来解释,而是用 make 来解释),可以用很简单的方法来说明我们需要做的文件比较。这样上面的脚本就可以写成这个样子了:
1 | #sample1 |
上面那个 Makefile 中,foo.o: foo.c 定义了一个“依赖”,说明 foo.o 是靠 foo.c 编译成的,它后面缩进的那些命令,就是简单的 shell 脚本,称为规则(rule)。而 Makefile 的作用是定义一组依赖,当被依赖的文件比依赖的文件新,就执行规则。这样,前面的问题就解决了。
IDE 中封装了 Makefile 的使用,但想要具体控制特定文件的编译细节,最终仍然需要面对这些问题,IDE 和 make 工具的对比,两者解决的是问题的不同层次。
Makefile 中的依赖定义构成了一个依赖链(树),比如上面这个 Makefile
中,app.executable 依赖于 main.o,main.o 又依赖于
main.c,所以,当你去满足
app.executable(这个目标)的依赖的时候,它首先去检查 main.o
的依赖,直到找到依赖树的叶子节点(main.c),然后进行时间比较。这个判断过程由
make 工具来完成,所以,和一般的脚本不一样。Makefile
的执行过程不是基于语句顺序的,而是基于依赖链的顺序的。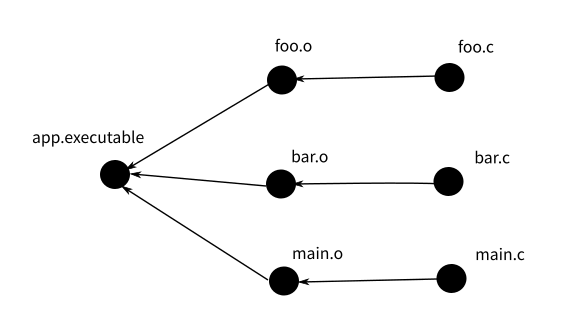
phony 依赖
make 命令执行的时候,后面跟一个“目标”(不带参数的话默认是第一个依赖的目标),然后以这个目标为根建立整个依赖树。依赖树的每个节点是一个文件,任何时候我们都可以通过比较每个依赖文件和被依赖文件的时间,以决定是否需要执行“规则”
但有时,我们希望某个规则总是被执行。这时,很自然地,我们会定义一下永远都不会被满足的依赖。
可能会这么写:
1 | test: |
test 这个文件永远都不会被产生,所以,你只要执行这个依赖,rule 是必然会被执行的。这种形式看起来很好用,但由于 make 工具默认认为你这是个文件,当它成为依赖链的一部分的时候,很容易造成各种误会和处理误差。
所以,简化起见,Makefile 允许你显式地把一个依赖目标定义为假的(Phony):
1 |
|
这样 make 工具就不用多想了,也不用检查 test 这个文件的时间了,反正 test 就是假的,如果有人依赖它,无条件执行就对了。
宏
前面的 sample1 明显还是有很多多余的成份,这些多余的成份可以简单通过引入“宏”定义来解决,比如上面的 Makefile,我们把重复的东西都用宏来写,就成了这样了:
1 | #sample2 |
还是有“多余”的成份在,因为明明依赖中已经写了 foo.o 了,rule 中还要再写一次,我们可以把依赖的对象定义为 $@,被依赖的对象定义为 $^(这是当前 gnumake 的设计),这样就可以进一步化简:
1 | #sample3 |
很明显,这还是有重复,我们可以把重复的定义写成通配符:
1 | #sample4 |
实际上,你要化简,还有很多手段,比如 gnumake 其实是默认定义了一组 rule 的,上面这个整个你都可以不写,就这样就可以了:
1 | #sample5 |
这里其实没有定义 .o 到 .c 的依赖,但 gnumake 默认如果 .c 存在,.o 就依赖对应的 .c,而 .o 到 .c 的 rule,是通过宏默认定义的。你只要修改 CC,LDLIBS 这类的宏,就能解决大部分问题了。所以你又省掉了一组定义,这就可以写得很短。
头文件问题
现在我们把问题搞得复杂一点,增加三个头文件。比如 foo.h、bar.h 和 common.h,前两者定义 foo.c 和 bar.c 的对外接口,给 main.c 使用,common.h 定义所有文件都要用到的通用定义(foo.h 和 woo.h 中包含 common.h)。这样前面这个 sample1 就有毛病了。照理说,foo.h 更新的时候,foo.o 和 main.o 都需要重新编译,但根据那个定义,根本就没有这个比较。
我们的定义必须写成这个样子:
1 | #sample4+ |
(注:这个例子我们在 .o.c 依赖的规则中使用了 $< 宏,它和 $^ 的区别是,它不包括依赖列表中的所有文件,而仅仅是列表中的第一个文件)
这就又增加了复杂度了——头文件包含关系一变化,我就得更新这个 Makefile 的定义。这带来了升级时的冗余工作。按我们前面考虑一样的策略,我们尝试在已有的名称空间上解决这个问题。Makefile 已经可以定义依赖了,但我们不知道这个依赖本身。这个事情谁能解决?——把这个过程想一下——其实已经有人解决这个问题了,这个包含关系谁知道嘛?当然是编译器。编译器都已经用到那个头文件了,当然是它才知道这种包含关系是什么样的。比如 gcc 本身直接就提供了 -M 系列参数,可以自动帮你生成依赖关系。比如你执行 gcc -MM foo.c 就可以得到
1 | foo.o: foo.c foo.h common.h |
本文引自开头的链接,由于能力有限及需求不高,剩余的看的不是很懂,目前就到这里。





