
11711 Advanced NLP: Quantization
Lec19 Quantization
This lecture addresses a fundamental deployment challenge: modern LLMs are too large to fit on commodity hardware. Quantization reduces the number of bits used to represent each model weight, dramatically shrinking memory requirements while preserving most of the model’s quality.
Motivation
The core problem is straightforward: models are large.
Consider Qwen3-8B as an example: - 8 billion parameters × 16 bits (BFloat16) = 16 GB just for weights - With ~1.5× overhead for activations during inference → ~24 GB total - A MacBook Air (16 GB shared memory) cannot run this without swapping to disk - A T4 GPU (16 GB VRAM) runs out of memory entirely
Quantization offers a direct solution: represent each weight with fewer bits. A 4-bit quantized version of Qwen3-8B is only ~6 GB, comfortably fitting on either device.
Representing Numbers on a Computer
Before understanding quantization, we need to understand how numbers are stored.
Unsigned Integers
Each bit represents a power of 2. An 8-bit unsigned integer (U8) sums the powers at positions where the bit is 1:
\[ 01010110_2 = 1 \times 2^6 + 1 \times 2^4 + 1 \times 2^2 + 1 \times 2^1 = 64 + 16 + 4 + 2 = 86 \]
| Type | Bits | Range |
|---|---|---|
| U8 | 8 | 0 to 255 |
| U16 | 16 | 0 to 65,535 |
| U32 | 32 | 0 to 4,294,967,295 |
Signed Integers
The leftmost bit acts as a sign bit. Negative numbers use two’s complement: flip all bits and add 1.
- INT8: 8-bit, range [-128, 127]
- INT16, INT32 follow the same pattern with wider ranges
Floating Point
Floating-point numbers represent real values using three components: sign, exponent, and significand (mantissa):
\[ \text{value} = (-1)^{\text{sign}} \times (1.\text{significand}) \times 2^{\text{exponent} - \text{bias}} \]
The bias allows storing the exponent as an unsigned integer. This is essentially binary scientific notation: \(1.101 \times 2^3 = (1 + 0.5 + 0.125) \times 8 = 13\).
Worked example (Float32):
| Sign | Exponent (8 bits) | Significand (23 bits) |
|---|---|---|
| 0 | 10000001 = 129 | 01100…0 |
- Exponent − bias: \(129 - 127 = 2\)
- Significand: \(1 + 0 \times 2^{-1} + 1 \times 2^{-2} + 1 \times 2^{-3} = 1.375\)
- Value: \(1.375 \times 2^2 = 5.5\)
Floating Point Types
| Format | Total Bits | Sign | Exponent | Significand |
|---|---|---|---|---|
| Float32 (full precision) | 32 | 1 | 8 | 23 |
| Float16 (half precision) | 16 | 1 | 5 | 10 |
| BFloat16 | 16 | 1 | 8 | 7 |
BFloat16 is a notable design choice: it keeps the same exponent range as Float32 (so it can represent the same magnitude of numbers) but sacrifices significand precision. This makes BFloat16-to-Float32 conversion trivial (just pad the significand with zeros) and avoids overflow issues during training, at the cost of less precision for values close together. Most modern LLMs (e.g., Qwen3-8B) store weights in BFloat16.
Quantizing for Inference
What Is Quantization?
Quantization maps values from a large set to a smaller set. The simplest example: rounding a real number to the nearest integer.
\[ Q(x) = \text{round}(x) \]
The quantization error is the difference between the original and quantized value. For instance, \(Q(1.4) = 1\) (error = 0.4) and \(Q(0.8) = 1\) (error = 0.2).
Why Quantize LLMs?
In large Transformers, the feed-forward and attention projection layers account for ~95% of parameters and 65-85% of computation (Ilharco et al., 2020). The goal is to: 1. Quantize these parameters to fewer bits (e.g., BFloat16 → INT8 or INT4) 2. Use low-bit-precision matrix multiplication 3. Reduce memory so large models can run on consumer hardware
8-Bit Quantization: Absmax
Absmax quantization scales the entire input tensor into the INT8 range \([-127, 127]\) using the absolute maximum value:
\[ X_{i8} = \text{round}\left(\frac{127 \cdot X_{f16}}{\max_{ij}(|X_{f16_{ij}}|)}\right) \]
The scaling factor is \(s = \frac{127}{\max(|X|)}\). To dequantize, simply divide by the scale.
1 | import numpy as np |
Matrix multiplication with absmax uses vector-wise quantization: quantize each row of \(X\) and each column of \(W\) separately, multiply in INT8 (accumulating into INT32), then dequantize:
\[ XW = \frac{1}{s_x s_w} Z_{i32} \approx \frac{1}{s_x s_w} Q(X) Q(W) \]
8-Bit Quantization: Zero-Point
Zero-point quantization maps the full float range \([\min, \max]\) to the full INT8 range \([-128, 127]\), using both a scale and an offset:
\[ \text{INT8} = \text{round}(s \cdot \text{FP}) + \text{offset} \]
where:
\[ s = \frac{255}{\max - \min}, \quad \text{offset} = -\text{round}\left(\frac{255}{\max - \min} \cdot \min\right) - 128 \]
To dequantize:
\[ \text{FP} = \frac{\text{INT8} - \text{offset}}{s} \]
Zero-point quantization is better for asymmetric data (e.g., activations after ReLU, which are all non-negative). Absmax would waste half the integer range on negative values that never appear.
The Outlier Problem
Both methods normalize based on the min/max of the tensor. When outliers are present, the scale factor is dominated by the extreme values, causing all other values to cluster into a tiny portion of the integer range.
| Scenario | Absmax MSE | Zero-Point MSE |
|---|---|---|
| Without outlier | 0.000001 | 0.000001 |
| With outlier (100.0) | 0.060013 | 0.014756 |
The error increases by 4-5 orders of magnitude with a single outlier. This is not a theoretical concern — real Transformer LMs exhibit systematic outlier features.
LLM.int8() (Dettmers et al., 2022)
Dettmers et al. observed that Transformer LMs develop outlier features: specific columns of the activation matrices with values far larger than the rest. In models with \(\geq\) 6.7B parameters, outliers appear in 100% of layers. Naive 8-bit quantization collapses at this scale — accuracy drops catastrophically.
The key insight: only ~0.1% of activation features are outliers. So the solution is a mixed-precision decomposition:
- Identify outlier columns in activations (columns where magnitude exceeds a threshold)
- Extract the outlier columns from \(X\) and corresponding rows from \(W\)
- Perform the outlier part in FP16 (high precision)
- Perform the regular part in INT8 (low precision, vector-wise absmax)
- Merge the two results
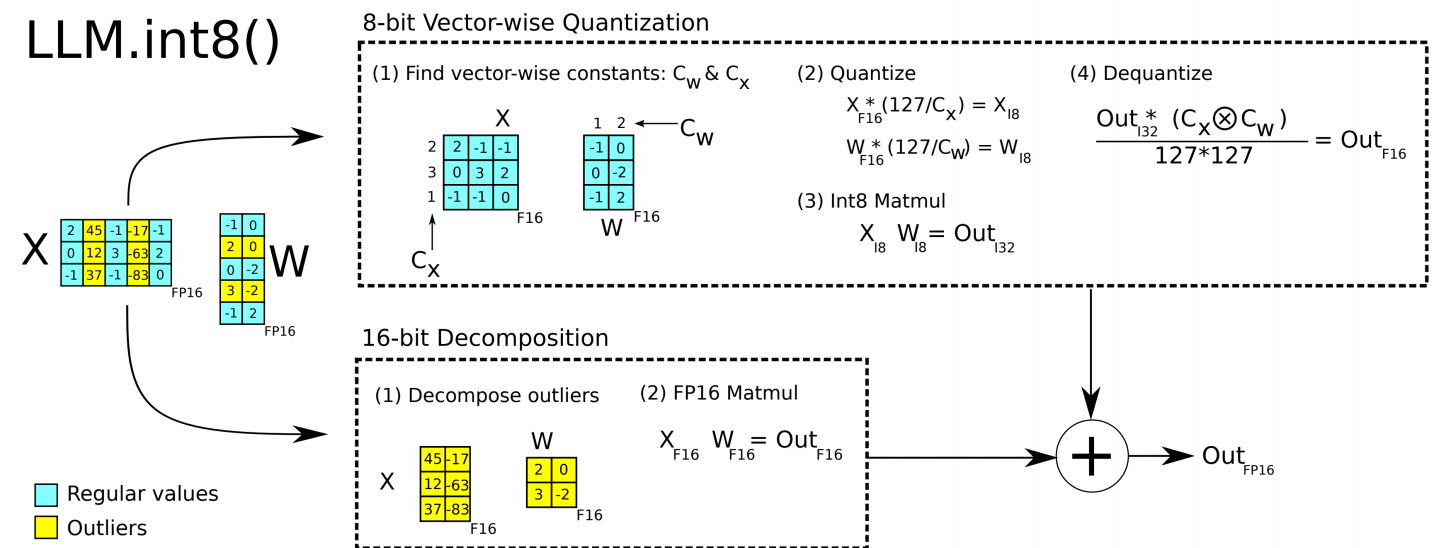
This achieves accuracy matching the FP16 baseline across all model sizes tested (up to 175B parameters), while the naive 8-bit baseline degrades sharply after 6.7B.
| Method | 125M | 1.3B | 2.7B | 6.7B | 13B |
|---|---|---|---|---|---|
| 32-bit Float | 25.65 | 15.91 | 14.43 | 13.30 | 12.45 |
| Int8 absmax | 87.76 | 16.55 | 15.11 | 14.59 | 19.08 |
| Zeropoint LLM.int8() | 25.69 | 15.92 | 14.43 | 13.24 | 12.45 |
(Validation perplexity — lower is better)
GGML/GGUF/Llama.cpp
GGML is a tensor library with its own quantization methods, designed for efficient CPU and GPU inference.
An example quantization scheme, Q4_K: - Groups weights into super-blocks of 8 blocks, each block containing 32 weights - Each weight is stored as 4 bits - Per-block scale and offset stored as 6-bit values
Two common presets: - Q4_K_S: Use Q4_K for all tensors (smaller, slightly less accurate) - Q4_K_M: Use higher-precision Q6 for half of certain attention and FFN tensors (better quality)
GGML supports multiple backends: Metal (Apple Silicon), ARM, CUDA, and more.
GGUF is the file format for storing model architectures and quantized weights. Llama.cpp is an inference library built on GGML/GGUF, enabling local LLM inference:
1 | llama-server -hf Qwen/Qwen3-8B-GGUF:Q4_K_M --port 8080 |
Example file sizes for Qwen3-8B-GGUF:
| Quantization | Bits | Size |
|---|---|---|
| Q4_K_M | 4 | 5.03 GB |
| Q5_K_M | 5 | 5.85 GB |
| Q6_K | 6 | 6.73 GB |
| Q8_0 | 8 | 8.71 GB |
Different tensors within the same model can use different quantization levels. For instance, in Q4_K_M, normalization weights stay in F32 while attention and FFN weights use Q4_K or Q6_K.
Beyond Integers: NVFP4
New hardware-native data types are emerging. NVFP4 is a 4-bit floating-point format (E2M1: 1 sign, 2 exponent, 1 mantissa) introduced with NVIDIA’s Blackwell architecture. It uses: - Per-block scaling with FP8 (E4M3) scale factors for each 16-value block - Per-tensor scaling with FP32 for global normalization
This moves quantization from integer-only to low-bit floating point, better preserving the distribution of weight values.
Quantizing & Training
Quantization-Aware Training (QAT)
Post-training quantization (PTQ) applies quantization to a pre-trained model without further training. Quantization-Aware Training (QAT) takes a different approach: fine-tune the model with simulated quantization so that the weights learn to be robust to quantization errors.
The key mechanism is inserting a fake quantize-dequantize operation into the forward pass:
1 | # QAT: x_fq is still in float, but has been through quantize + dequantize |
The model trains in full precision but “sees” quantization noise during forward passes, learning weight configurations that are more resilient when actually quantized. During inference, the fake quantize nodes are replaced with real quantization.
QAT consistently outperforms PTQ, especially at lower bit widths. For example, Kimi-K2-Thinking uses native INT4 quantization via QAT in its post-training stage, achieving lossless 2x speed-up in low-latency mode.
Fine-Tuning: QLoRA (Dettmers et al., 2023)
QLoRA combines quantization with LoRA to dramatically reduce the GPU memory needed for fine-tuning:
| Component | LoRA | QLoRA |
|---|---|---|
| Base model | 16-bit | 4-bit |
| Adapters | 16-bit | 16-bit |
| Optimizer states | 32-bit (GPU) | 32-bit (CPU, paged) |
The key ideas: 1. 4-bit NormalFloat (NF4): Quantize the frozen base model to 4-bit using a data type optimized for normally-distributed weights 2. Double quantization: Quantize the quantization constants themselves to save additional memory 3. Paged optimizers: Offload optimizer states to CPU RAM, paging them to GPU only when needed
This allows fine-tuning a 65B-parameter model on a single 48GB GPU — a task that would otherwise require multiple high-end GPUs.
Lec19 Takeaways
- Quantization is essential for deployment: reducing from 16-bit to 4-bit shrinks model size by ~4x, making billion-parameter models accessible on consumer hardware
- Outliers break naive quantization: Transformer LMs develop systematic outlier features at scale; mixed-precision decomposition (LLM.int8()) solves this by handling the ~0.1% of outlier features in high precision
- Format diversity is growing: from integer-based (INT8, INT4) to floating-point (NVFP4, FP8), with hardware co-design driving new formats
- QAT beats PTQ: training with quantization-aware noise produces models that degrade less when actually quantized
- QLoRA democratizes fine-tuning: combining 4-bit quantization with LoRA and memory paging makes fine-tuning large models feasible on modest hardware
Final Summary
| Topic | Key Idea |
|---|---|
| Number representation | Float32/16, BFloat16 trade precision for range; BFloat16 keeps Float32’s exponent range |
| Absmax quantization | Scale by absolute max to map into [-127, 127]; simple but sensitive to outliers |
| Zero-point quantization | Uses scale + offset to map full range; better for asymmetric distributions |
| LLM.int8() | Mixed-precision: outlier features (~0.1%) in FP16, rest in INT8 |
| GGML/Llama.cpp | Block-based quantization (Q4_K, Q6_K) with per-block scales; supports Metal/CUDA |
| QAT | Insert fake quantize-dequantize during training to learn quantization-robust weights |
| QLoRA | 4-bit base model + 16-bit LoRA adapters + CPU-paged optimizers for efficient fine-tuning |
Key takeaway: Quantization is not just a deployment optimization — it is a first-class concern in the LLM lifecycle, with methods spanning inference (PTQ, LLM.int8()), training (QAT), and fine-tuning (QLoRA), each navigating the fundamental tradeoff between model size and quality.
References
- Dettmers et al., “LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale,” 2022
- Dettmers et al., “QLoRA: Efficient Finetuning of Quantized Language Models,” 2023
- Ilharco et al., “High Performance Natural Language Processing,” 2020
- GGML / Llama.cpp: github.com/ggml-org/llama.cpp
- NVIDIA, “Introducing NVFP4 for Efficient and Accurate Low-Precision Inference”
- HuggingFace Quantization Overview: huggingface.co/docs/transformers/quantization/overview
This post is based on lecture materials from CMU 11-711 Advanced NLP by Sean Welleck (Lecture 19: Quantization).

