
11711 Advanced NLP: Multimodal Modeling
Lec11 Multimodal Modeling I (Multi-to-Text)
Big Picture
This part of the course focuses on multi-to-text systems:
- Input can include images (and text).
- Output is text.
- Core challenge: map image content into a sequence of vectors a language model can use.
Representing Images as Tokens
For text, we already have token embeddings.
For images, we need an encoder: \[
f_{\text{enc}}(x_{\text{image}}) \rightarrow z_1,\dots,z_L
\] where each \(z_i\) is a
vector token.
Vision Transformer (ViT)
ViT turns an image into a sequence of patch embeddings, then applies a standard Transformer.
Given: \[ x_{\text{image}} \in \mathbb{R}^{H \times W \times C} \]
Split into patches of size \(P \times P\): \[ N=\frac{HW}{P^2}, \quad x_p \in \mathbb{R}^{N \times (P^2C)} \]
Project each patch to model dimension \(D\): \[ x = x_p W_e, \quad W_e \in \mathbb{R}^{(P^2C)\times D}, \quad x \in \mathbb{R}^{N\times D} \]
Then add position embeddings and process with Transformer layers.


Key intuition from lecture:
- Early layers capture local/structural signals.
- Later layers attend to broader semantic regions.
- ViT scales well with pretraining compute.
CLIP: Learn Vision from Language Supervision
CLIP (Radford et al., 2021) learns a shared embedding space for images and text.
- Image encoder: \(f_I(x)\)
- Text encoder: \(f_T(y)\)
- Paired image-text should be close; mismatched pairs should be far.
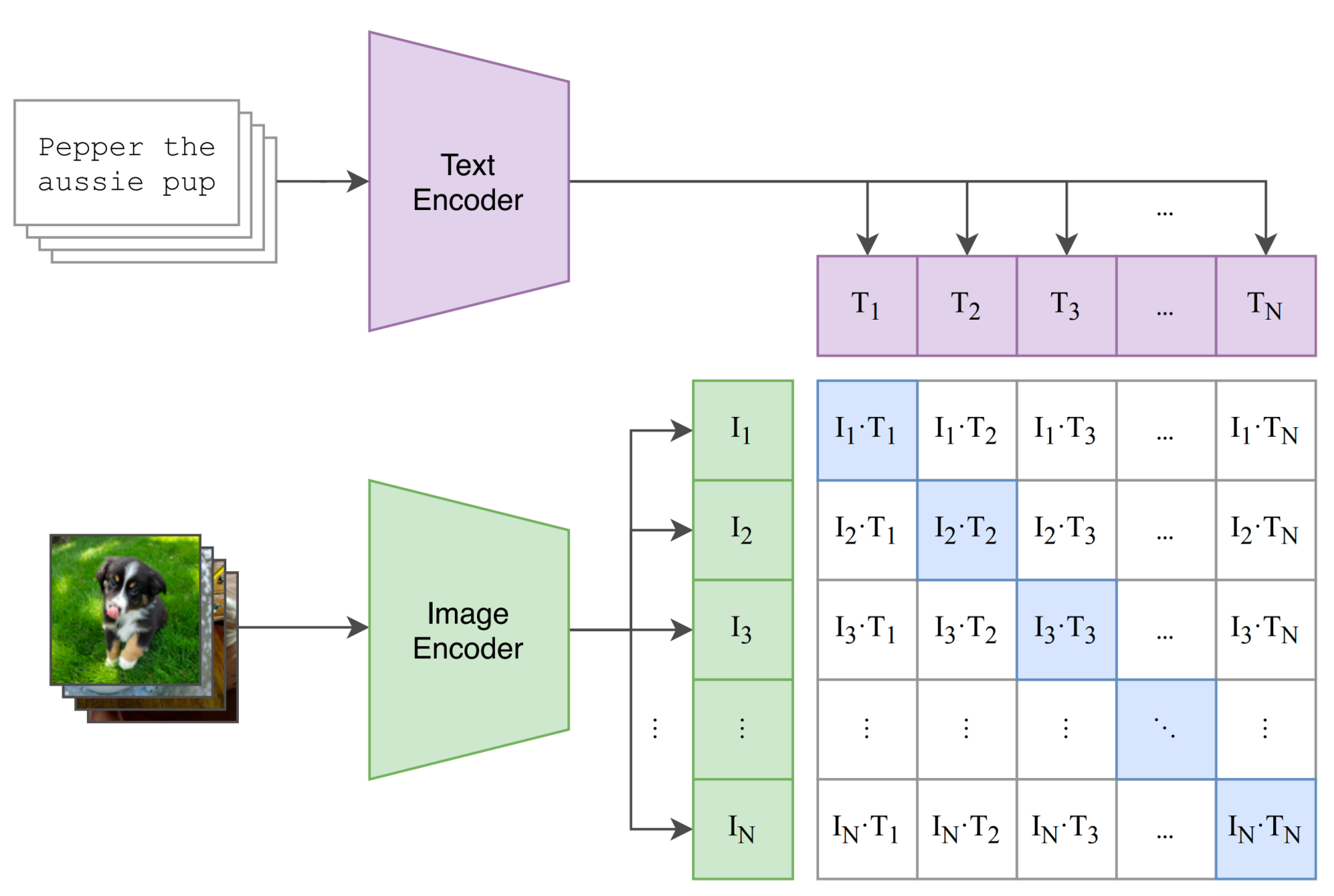
For a batch of \(N\) aligned pairs \((x_n,y_n)\), define similarities: \[ s_{ij}=\frac{f_I(x_i)^\top f_T(y_j)}{\tau} \]
Symmetric contrastive objective: \[ \mathcal{L}_{\text{img}}=-\frac{1}{N}\sum_{i=1}^N \log \frac{e^{s_{ii}}}{\sum_j e^{s_{ij}}}, \quad \mathcal{L}_{\text{text}}=-\frac{1}{N}\sum_{i=1}^N \log \frac{e^{s_{ii}}}{\sum_j e^{s_{ji}}} \] \[ \mathcal{L}_{\text{CLIP}}=\frac{1}{2}\left(\mathcal{L}_{\text{img}}+\mathcal{L}_{\text{text}}\right) \]
Why it mattered:
- Uses natural language descriptions instead of only class labels.
- Scales to web-scale image-text data.
- Enables strong zero-shot transfer.
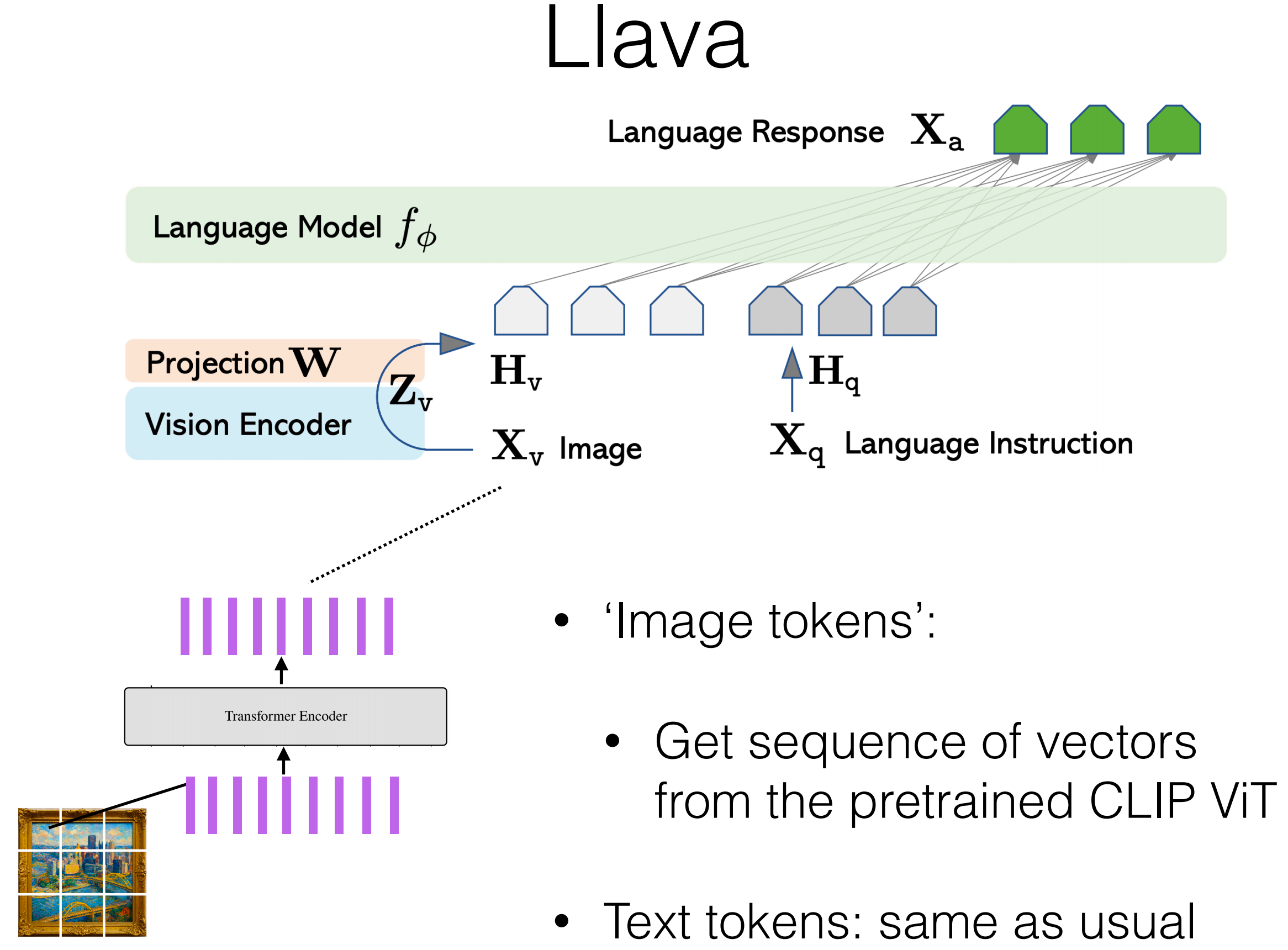
LLaVA-style Combination with a Language Model
General pipeline from lecture:
- Preprocess image (patching/cropping).
- Encode image with a vision encoder (often CLIP ViT).
- Linearly project vision features to LM embedding dimension.
- Concatenate visual tokens with text tokens.
- Train/fine-tune on image-text instruction data.
- For image positions, skip token-level LM loss.
A simple form: \[ h_v=\text{Proj}(f_I(x_{\text{image}})), \quad p_\theta(y_t\mid y_{<t},x_{\text{text}},h_v) \]
Case Notes Mentioned in Lecture
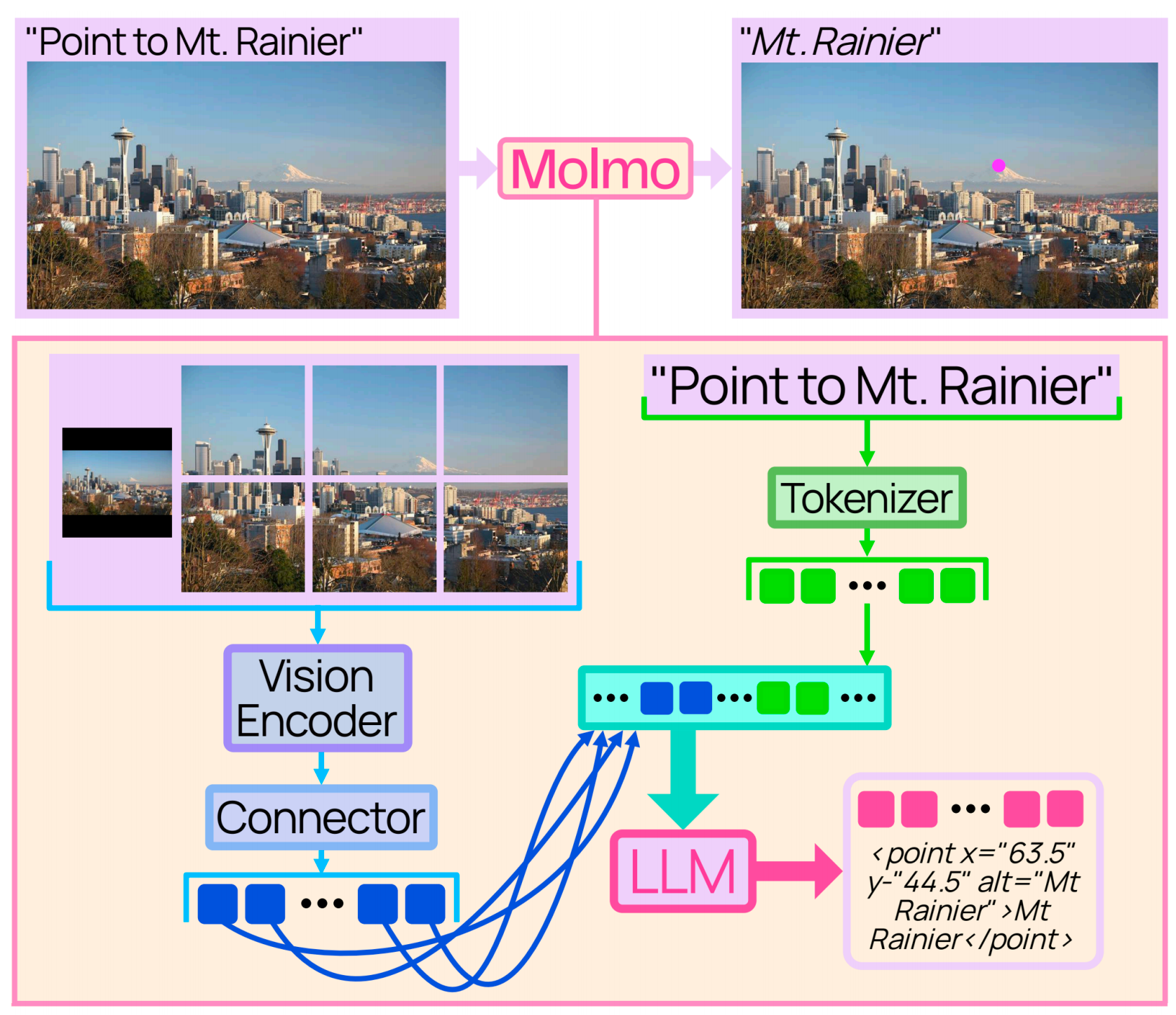
- Molmo (AI2): CLIP ViT-L/14 (336px), then pooling/projection before feeding LM; uses full image + crops.
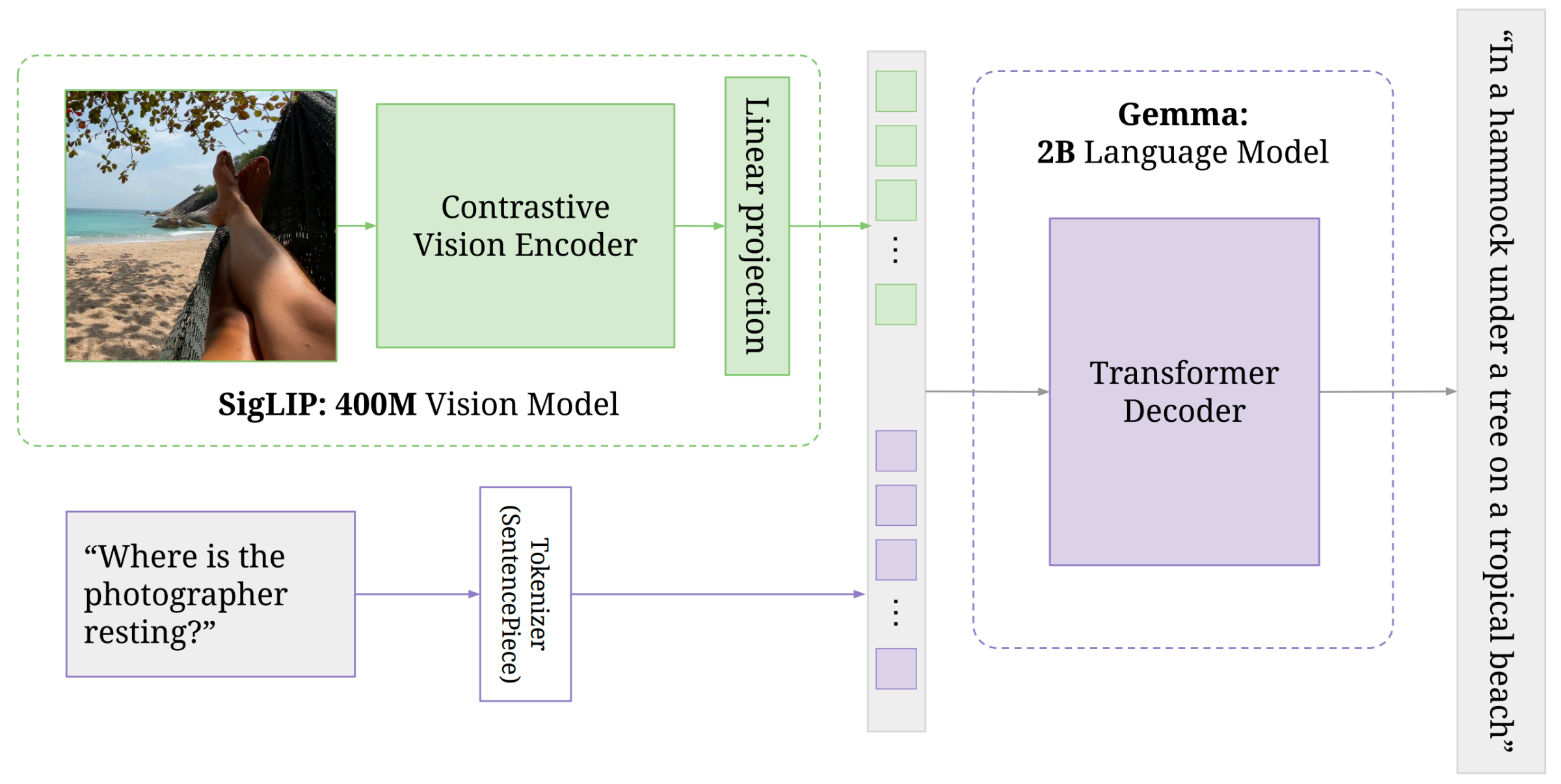
- PaliGemma (Google): lecture highlighted that jointly updating vision encoder + LM can outperform freezing one side.
Lec11 Takeaways
- ViT gives a clean tokenization interface for images.
- CLIP gives strong, scalable image representations through contrastive learning.
- Multimodal assistants are mostly about interface design between vision tokens and LM tokens.
Lec12 Multimodal Modeling II (Generating Images)
Generative Paradigms
Lecture compared four families:
Autoregressive (AR): model \(p(x_t\mid x_{<t})\).

VAE: encode to latent \(z\), decode back.

GAN: generator vs discriminator game.

Diffusion: denoise from noise to data.
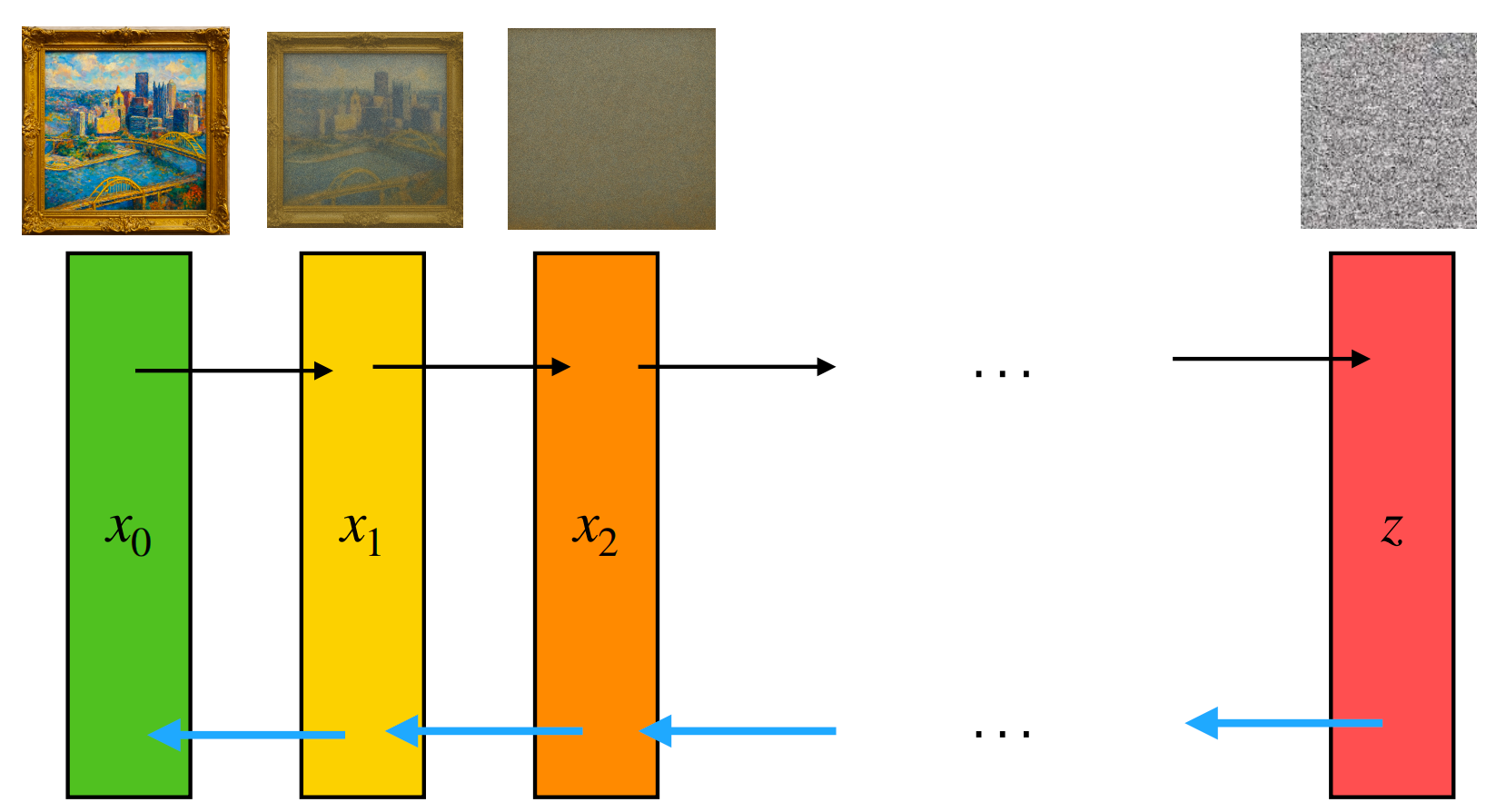
Attempt 1: Pixel-level Autoregression
Flatten image into a long sequence of pixel values: \[ x_{\text{img}} \rightarrow (x_1,\dots,x_T),\quad x_t\in\{0,\dots,255\} \] \[ \mathcal{L}_{\text{MLE}}=-\sum_{t=1}^{T}\log p_\theta(x_t\mid x_{<t}) \]
Examples discussed: PixelRNN, Image Transformer, iGPT.
Main bottlenecks:
- Sequence length explodes (e.g., \(1024\times1024\times3\approx 3\)M tokens).
- Pixel tokens are low-level; learning semantics is data-hungry.
Attempt 2: Learn Discrete Image Tokens
Core idea: learn an image tokenizer/de-tokenizer so the LM models a shorter, semantic token sequence.
VAE Refresher
Standard objective: \[ \mathcal{L}_{\text{VAE}}(x)= -\mathbb{E}_{q_{\theta_{\text{enc}}}(z\mid x)}[\log p_{\theta_{\text{dec}}}(x\mid z)] +D_{\text{KL}}\!\left(q_{\theta_{\text{enc}}}(z\mid x)\|p(z)\right) \]
Equivalent view via ELBO: \[ \log p(x)\ge \mathbb{E}_{q(z\mid x)}[\log p(x\mid z)] -D_{\text{KL}}(q(z\mid x)\|p(z)) \]
VQ-VAE: Continuous to Discrete
Encoder gives continuous latent: \[ z_e(x)\in\mathbb{R}^{d} \]
Quantize by nearest codebook entry: \[ k^*=\arg\min_j\|z_e(x)-e_j\|_2,\quad z_q(x)=e_{k^*} \]
Train with reconstruction + codebook + commitment terms: \[ \mathcal{L}= -\log p(x\mid z_q(x)) +\|\text{sg}[z_e(x)]-e\|_2^2 +\beta\|z_e(x)-\text{sg}[e]\|_2^2 \]
Then model discrete image tokens autoregressively.

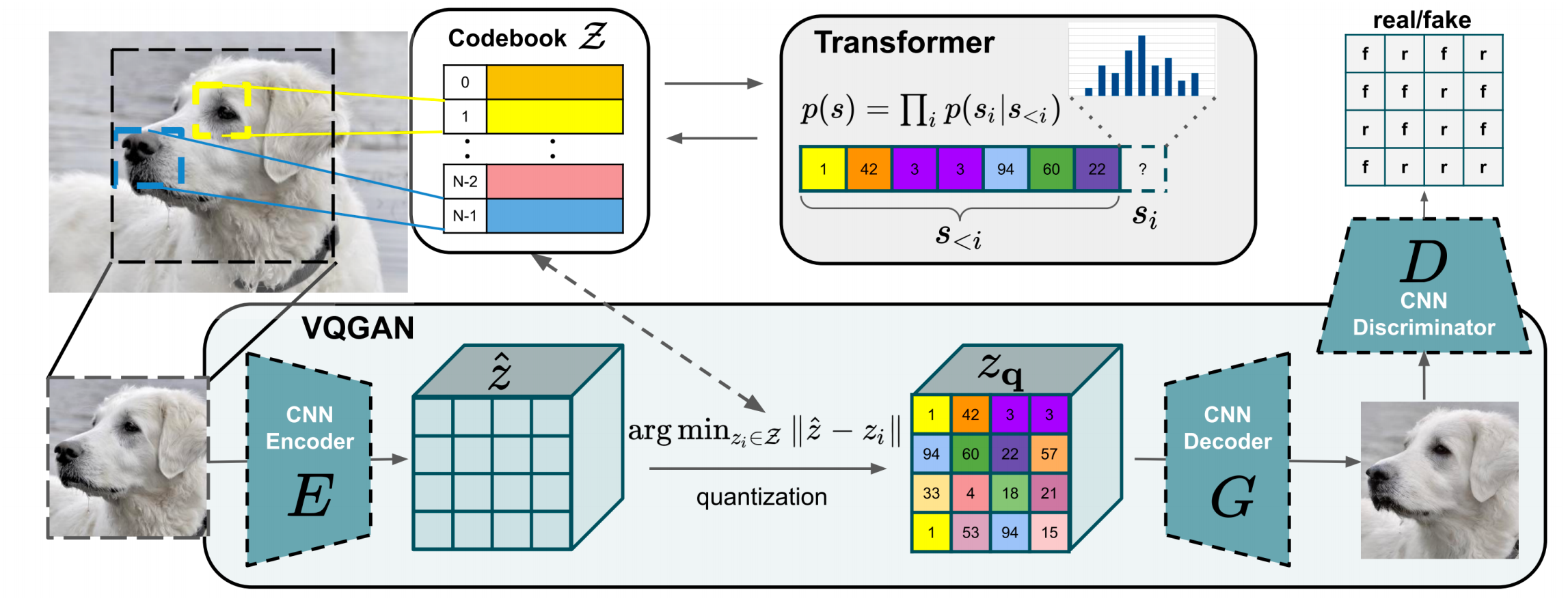
VQ-GAN
VQ-GAN improves VQ-VAE by adding adversarial/perceptual signals in tokenizer training, then training an AR Transformer on resulting token sequences.
Practical gain from lecture:
- Sequence becomes much shorter (example: \(32\times32=1024\) tokens) than raw pixels.
- Better tradeoff between generation quality and AR modeling feasibility.
Unifying Text and Image Tokens
After tokenizer training:
- Add image tokens to LM vocabulary.
- Train/fine-tune on mixed text+image token streams.
- Decode image tokens back to pixels using de-tokenizer.
Examples discussed: DALL-E (2021), Chameleon (Meta, 2024).
Lec12 Takeaways
- Pure pixel AR is conceptually simple but hard to scale.
- Discrete tokenizers (VQ-VAE/VQ-GAN) are the key bridge for AR multimodal models.
- Tradeoff: unified token modeling vs information loss from tokenization.
Final Summary
- Lec11: how to encode images for text generation (ViT + CLIP + LM integration).
- Lec12: how to generate images with token-based generative modeling.
- Together they frame multimodal systems as:
representation (encode) + alignment (shared space) + generation (decode).
This post is based on CMU 11-711 Advanced NLP lecture materials (Multimodal Modeling I & II, Sean Welleck).


