
11868 LLM Sys: Tokenization and Embedding
Tokenization and Embedding
What is Tokenization?
Tokenization is the process of splitting text into basic units (tokens) that can be processed by language models. Many words don’t map to a single token - for example, “indivisible” might be split into multiple subword tokens.
The general pipeline is: 1. Tokenizer: Split text into token IDs 2. Embedding table lookup: Convert token IDs to vector representations
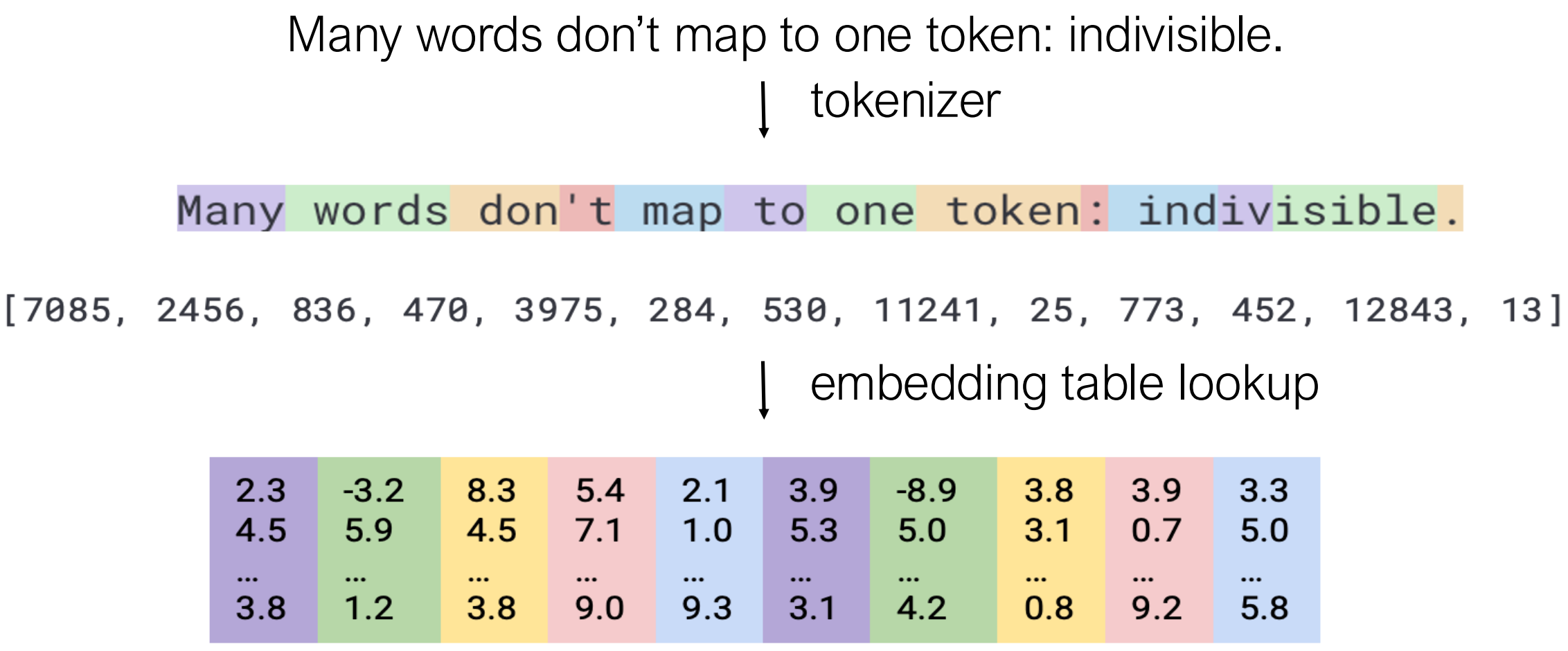
Simple Tokenization Approaches
Word-level Tokenization
Approach: Break text by spaces and punctuation
Examples: - English, French, German, Spanish work
well - Special treatment: numbers replaced by special token
[number]
Example: 1
2
3"The most eager is Oregon which is enlisting 5,000 drivers in the country's biggest experiment."
↓
["The", "most", "eager", "is", "Oregon", "which", "is", "enlisting", "5,000", "drivers", ...]
Challenge: What exactly is a “word”? - Clitics: “Bob’s” - Compounds: “handyman” - Multi-word expressions: “do-it-yourself” - Contractions: “isn’t”
Pros and Cons: - ✅ Easy to implement - ❌ Out-of-vocabulary (OOV) tokens (e.g., “Covid”) - ❌ Tradeoff between vocabulary size and unknown tokens: - Smaller vocab → fewer parameters, more OOV - Larger vocab → more parameters, less OOV - ❌ Hard for languages without spaces (Chinese, Japanese, Korean, Khmer)
Character-level Tokenization
Approach: Each letter and punctuation is a token
1 | "The most eager is Oreg..." |
Pros: - ✅ Very small vocabulary (except for languages like Chinese) - ✅ No OOV tokens
Cons: - ❌ Longer sequences - ❌ Tokens don’t represent semantic meaning
Subword-level Tokenization
Goal
- Moderate size vocabulary
- No OOV tokens
- Represent rare words by sequences of subwords
Byte Pair Encoding (BPE)
Origin: Originally developed for data compression by Philip Gage (1994)
Algorithm for Building Vocabulary: 1. Initialize vocabulary with all characters as tokens (plus end-of-word symbol) and their frequencies 2. Loop until vocabulary size reaches capacity: 1. Count successive pairs of tokens in corpus 2. Rank and select the most frequent pair 3. Merge the pair to form a new token, add to vocabulary 3. Output final vocabulary
Example:
1 | Initial corpus: |
Tokenization Process: 1. Split text by space or other delimiters 2. Repeat: - Greedily find the longest prefix that matches a token in BPE dictionary - Split and process remaining parts until no more text left
Example Output: 1
2
3"The most eager is Oregon which is enlisting 5,000 drivers in the country's biggest experiment."
↓
["The", "most", "eager", "is", "Oregon", "which", "is", "en", "listing", "5,000", "driver", "s", "in", "the", "country", "'s", "big", "g", "est", "experiment", "."]
Code Examples:
- Official example: llmsys_code_examples/tokenization
- My implementation: See CS336
Assignment 1: BPE Tokenizer for a complete from-scratch
implementation with parallel pre-tokenization, including:
- BPE training algorithm with incremental pair updates
- Parallel corpus processing using multiprocessing
- Memory optimization techniques
- Full encoder/decoder implementation
- Code: GitHub - CS336 Transformer
Information-Theoretic Vocabulary (VOLT)
Motivation
Finding the optimal vocabulary traditionally requires: - Multiple full training and testing cycles - Trying different vocabulary sizes (1k, 10k, 30k tokens) - Evaluating NLG/MT performance for each configuration
Challenge: Can we predict good vocabulary without full training?
Measuring Vocabulary Quality
1. Compression Metrics: - Bytes Per Token (BPT): \[BPT = \frac{\text{utf8 bytes}}{\text{tokens}}\]
- Normalized Sequence Length (NSL): \[NSL = \frac{\text{tokens}}{\text{tokens in LLaMA}}\]
2. Normalized Entropy: \[\mathcal{H}(v) = -\frac{1}{l_v}\sum_{i \in v} P(i)\log P(i)\]
where \(l_v\) is the average number of characters for all tokens in vocabulary \(v\).
Interpretation: Measures semantic-information-per-character. Smaller is better (less ambiguity, easier to generate).
Example: 1
2
3
4
5Vocabulary 1: {a: 200, e: 90, c: 30, t: 30, s: 90}
→ H(v) = 1.37
Vocabulary 2: {a: 100, aes: 90, cat: 30}
→ H(v) = 0.14 ✓ Better!
Marginal Utility of Vocabulary (MUV)
Definition: \[M_{v_k \rightarrow v_{k+m}} = -\frac{H(v_k) - H(v_{k+m})}{m}\]
- Value: Normalized Entropy (semantic information)
- Cost: Vocabulary size
- MUV: Negative gradient of normalized entropy with respect to size
- Interpretation: How much value each added token brings
Key Finding: MUV Predicts Performance
Empirical observations: - Maximum MUV correlates with best BLEU scores - MUV and BLEU are correlated on ~2/3 of tasks - MUV serves as a coarse-grained evaluation metric for vocabulary quality
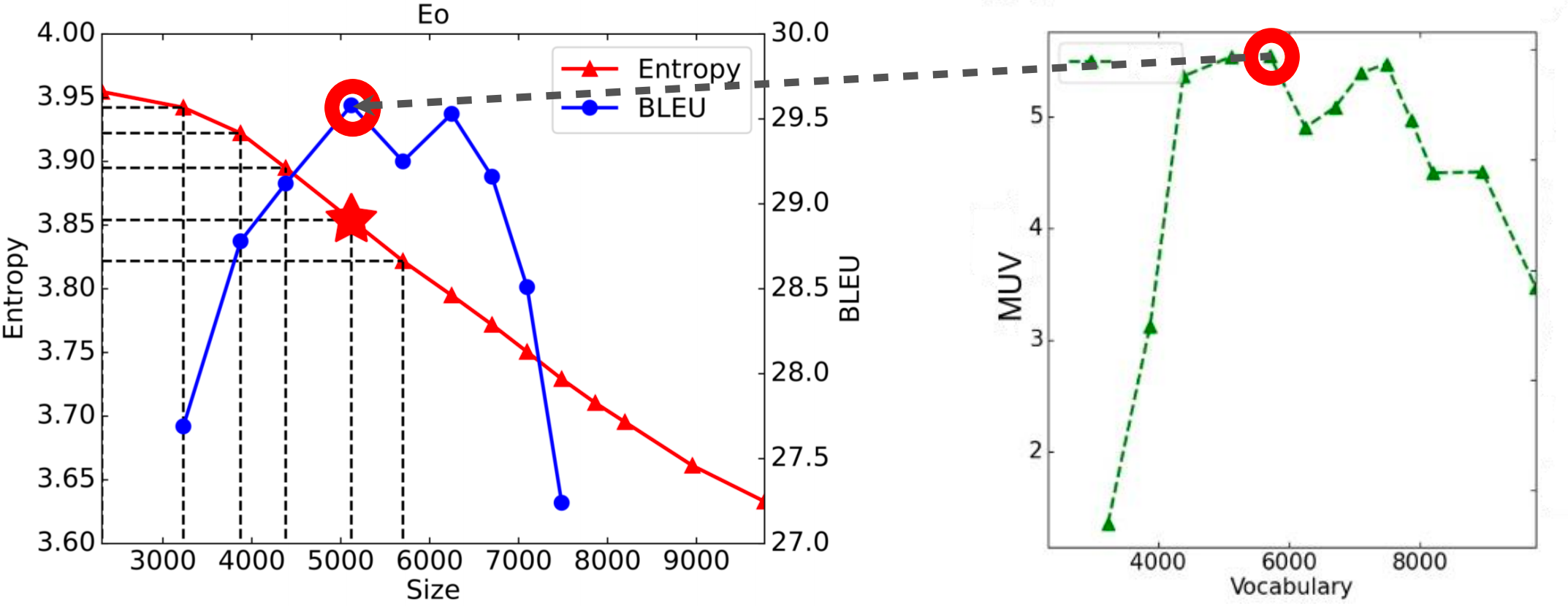
Practical Considerations in LLMs
1. Corpus Deduplication and Filtering
LLaMA 3 Deduplication Strategy: - URL-level dedup: Remove duplicate URLs - Document-level dedup: Using MinHash - Line-level dedup: Using SHA-1 64-bit hash for every 30M docs - Removes boilerplate (navigation menus, cookie warnings, contact info)
Filtering: - N-gram repeats within one line - “Dirty word” counting - Token distribution KL divergence too different from corpus
2. Modern Subword Tokenization Methods
Byte-level BPE (BBPE): - Treats language as sequence of Unicode bytes - Universal for all languages - No need for language-specific preprocessing
WordPiece: - Similar to BPE, but merges pairs that maximize \(P(b|a)\) - Used in BERT
SentencePiece: - Uniform treatment of spaces and punctuation - Replaces space ’ ’ with _ (U+2581) - Then splits into characters and applies BPE - Language-agnostic approach
3. Handling Code: Pre-tokenization
Use regular expressions to split sequences intelligently:
GPT-4 Pattern: 1
(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}|...
Components: - English contractions - Words (with optional leading non-alphanumeric) - Digits (1-3 at a time) - Non-alphanumeric characters - Line breaks - Trailing whitespace
Example: .append → single token (keeps
method names intact)
4. Handling Numbers
Challenge: Traditional tokenization treats each digit separately, making arithmetic difficult.
xVal Approach (Golkar et al., 2023): - Replace
numbers with special [NUM] token - Add continuous numerical
embedding alongside discrete token embedding - Dual-head decoder: -
Token head: Predicts next token (logits) -
Number head: Predicts numerical value
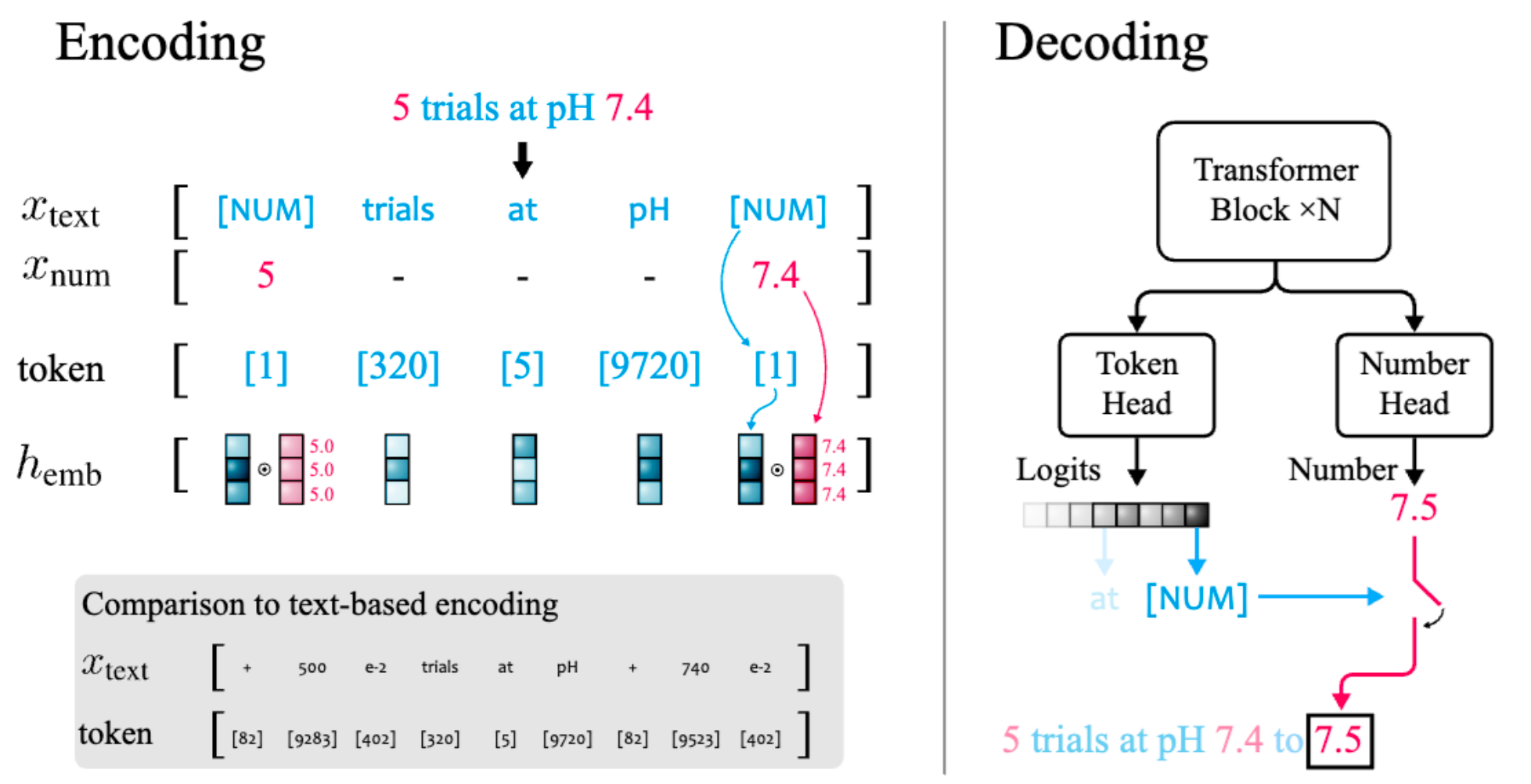
5. Multilingual Vocabulary
LLaMA 3 Evolution: - LLaMA 2: 32k tokens - LLaMA 3.1: 128k tokens - 100k from OpenAI’s tiktoken (reduced from 200k) - 28k allocated to multilingual support
Construction Methods:
- Joint BPE: Combine documents from multiple languages (176 in LLaMA 3), apply BPE on joint corpus
- Per-language BPE + Merge: Generate same number of tokens for each language, then merge
- ALP Balancing: Allocate capacity by balancing Average Log Probability across languages
Vocabulary Sharing Benefits:
Shared tokens enable cross-lingual transfer. Example - “television”
in multiple languages: 1
2
3
4English: television Spanish: televisión
French: television Italian: television
Dutch: televisie Portuguese: televisão
Swedish: television Finnish: televisio
Similar spellings → shared subword tokens → multilingual understanding
Vocabulary Sharing and Multilingual Performance
Experimental Setup
Research by Yuan et al. (ACL 2024) investigated: 1. Construct 10k instruction fine-tuning dataset using bilingual parallel data 2. Fine-tune LLaMA-7B embedding layer only 3. Evaluate translation performance: - Bilingual: Supervised language pair - Multilingual: All other directions
Four Quadrants of Performance
| Quadrant | Bilingual Perf. | Multilingual Perf. | Example Languages |
|---|---|---|---|
| Reciprocal | ↑ | ↑ | cs, da, fr, de |
| Altruistic | ↓ | ↑ | ar, vi, zh, ko |
| Stagnant | ↓ | ↓ | km, lo, gu, te |
| Selfish | ↑ | ↓ | hi |
Key Insight: Fine-tuning on bilingual data doesn’t always benefit the supervised direction!
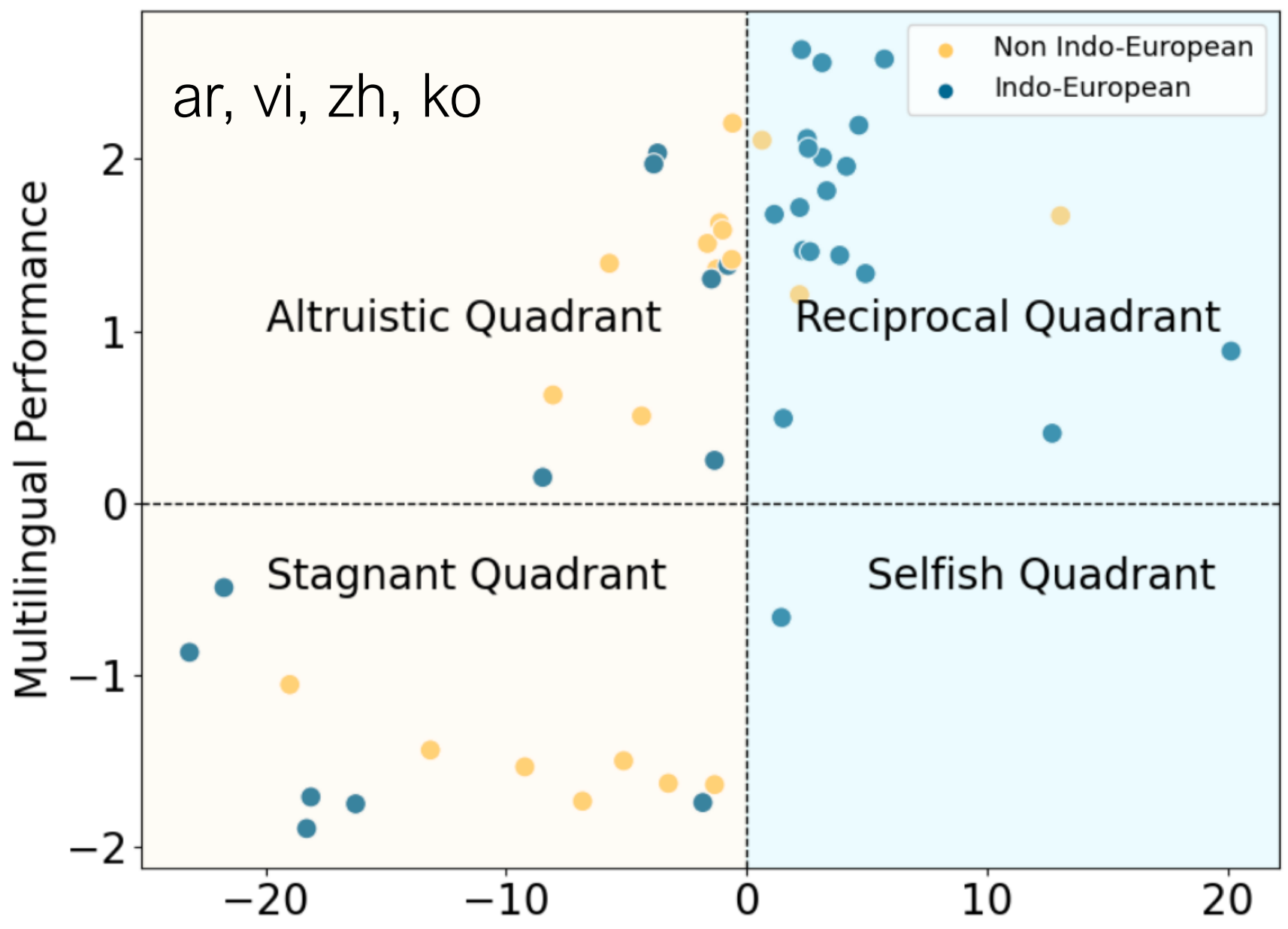
Language Families Matter
- Indo-European languages: Mostly in Reciprocal quadrant
- Non-Indo-European languages: More varied distribution, including Altruistic and Stagnant quadrants
Stagnant Quadrant: Over-tokenization Problem
Root Cause: Byte-BPE produces longer byte sequences than character counts for some languages.
Example: 1
饕 [tāo] (gluttonous) → three tokens: [227, 234, 260]
Solution - Shortening: - Remove common byte prefixes (e.g., 227 for many Chinese characters) - Improves both bilingual and multilingual performance
Experimental Results: 1
2
3
4Direction: en→km en→lo en→gu en→te
Full FT: 10.1 7.0 10.0 17.0
Extend: 11.9 6.9 0.5 7.2
Shorten: 12.7 9.4 11.3 21.6 ✓ Best
Recommendation: Shortening is more effective than extending vocabulary for over-tokenized languages.
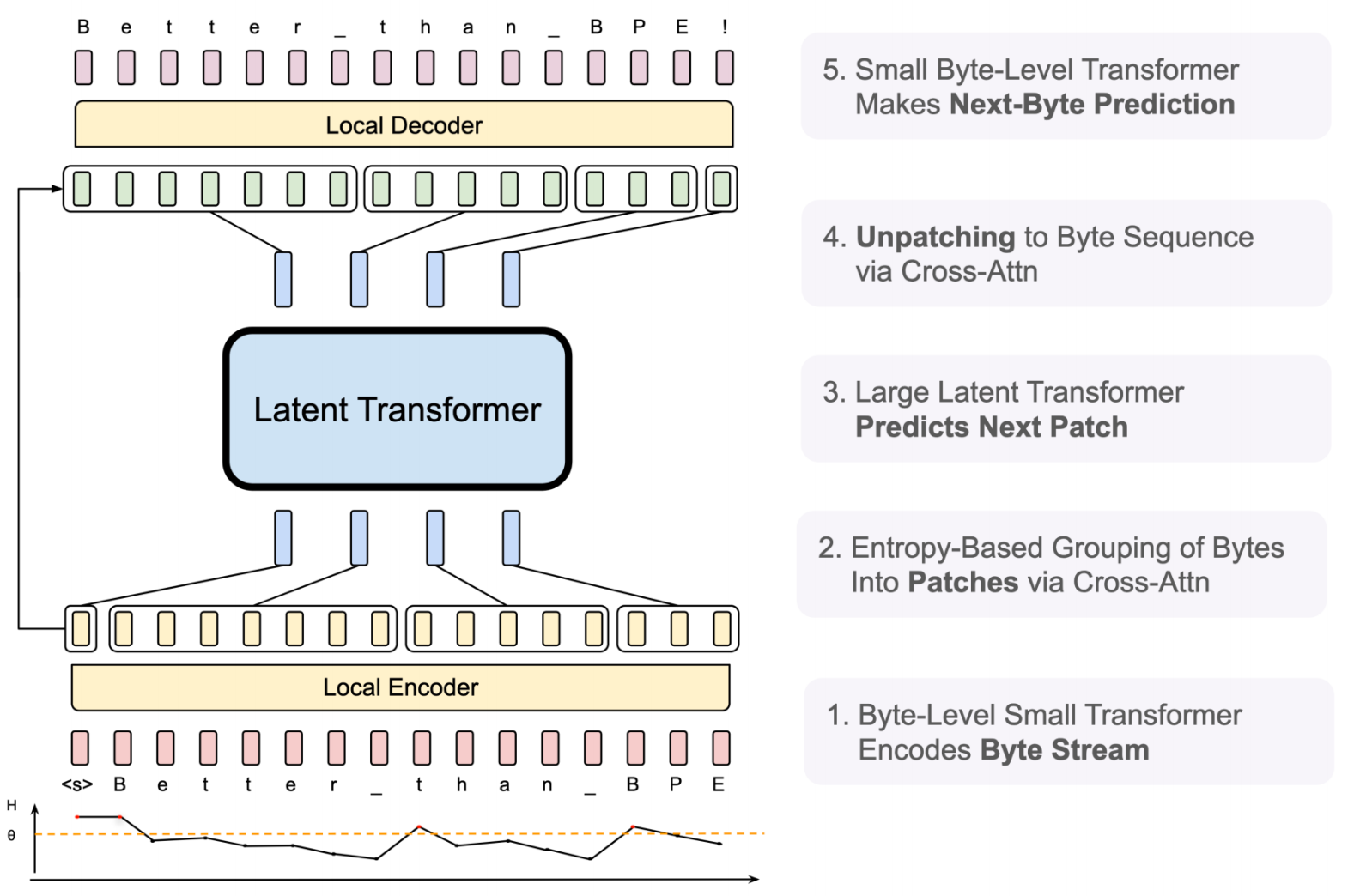
Tokenizer-free Models: Byte Latent Transformer (BLT)
Motivation: Eliminate tokenizer entirely, work directly with bytes.
Architecture (Pagnoni et al., 2024):
- Byte-Level Small Transformer: Encodes byte stream
- Entropy-Based Grouping: Groups bytes into patches via cross-attention
- Large Latent Transformer: Predicts next patch (main computation)
- Unpatching: Converts patches back to byte sequence via cross-attention
- Small Byte-Level Transformer: Makes next-byte prediction
Key Benefits: - ✅ No tokenizer training needed - ✅ Universal across all languages - ✅ Handles any byte stream (text, code, data) - ✅ Dynamic granularity (entropy-based patching)
Trade-offs: - More complex architecture - Two-level transformer hierarchy - Cross-attention overhead
Summary
Key Takeaways
- Subword Tokenization (BPE):
- Iteratively merges most frequent token pairs
- Balances vocabulary size and OOV rate
- Widely used (GPT, LLaMA, etc.)
- Information-Theoretic Vocabulary (VOLT):
- Uses normalized entropy to measure vocabulary quality
- MUV (Marginal Utility of Vocabulary) predicts performance
- Solves entropy-constrained optimal transport problem
- Avoids expensive grid search
- Practical Considerations:
- Pre-tokenization with regex for code
- Special handling for numbers (xVal approach)
- Corpus deduplication at multiple levels
- Multilingual vocabulary allocation
- Multilingual Challenges:
- Vocabulary sharing enables cross-lingual transfer
- Over-tokenization hurts some languages (stagnant quadrant)
- Shortening byte sequences more effective than extending vocabulary
- Language families affect sharing benefits
- Future Direction:
- Tokenizer-free models (BLT) show promise
- Trade-off between simplicity and efficiency
- Dynamic granularity via entropy-based patching
References
- Rico Sennrich et al. “Neural Machine Translation of Rare Words with Subword Units.” ACL 2016.
- Xu, Zhou, Gan, Zheng, Li. “Vocabulary Learning via Optimal Transport for Neural Machine Translation.” ACL 2021.
- Kudo and Richardson. “SentencePiece: A simple and language independent approach to subword tokenization.” EMNLP 2018.
- Dagan et al. “Getting the most out of your tokenizer for pre-training and domain adaptation.” ICML 2024.
- Golkar et al. “xVal: A Continuous Numerical Tokenization for Scientific Language Models.” 2023.
- Zheng et al. “Allocating large vocabulary capacity for cross-lingual language model pre-training.” EMNLP 2021.
- Liang et al. “XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models.” EMNLP 2023.
- Yuan et al. “How Vocabulary Sharing Facilitates Multilingualism in LLaMA?” ACL 2024.
- Pagnoni et al. “Byte Latent Transformer: Patches Scale Better Than Tokens.” 2024.
Demo Tools
Interactive tokenizer demos: - LLaMA Tokenizer - GPT Tokenizer
This post is based on lecture materials from CMU 11-868 LLM Systems by Lei Li.

