15645 Database systems: Hash Tables
Lec7 Hash Tables
Background
Data Structures in DBMS: Internal Meta-data, Core Data Storage, Temporary Data Structures, Table Indexes
Design Decisions: Data Organization (how we layout data in memory/pages and what information to store to support efficient access.) and Concurrency (enable multiple thread s to access the data structure at the same time)
Hash Tables: unordered associative array that maps keys to values; Space complexity is O(n), Time Complexity is average O(1), worst O(n).
Unrealistic Assumptions: Number of elements is known ahead of time and fixed; Each key is unique; Perfect hash function guarantees no collisions.
Hash functions
We care how to map a large key space into a smaller domain, the main goal is the trade-off between being fast vs. collision rate.
Examples: CRC-64 (1975)、MurmurHash (2008)、Google CityHash (2011)、Facebook XXHash (2012, state-of-the-art)、Google FarmHash (2014)、RapidHash (2019)
Static Hashing Schemes
Linear Probe Hashing
Single giant table of fixed-length slots.
Resolve collisions by linearly searching for the next free slot in the table.
- To determine whether an element is present, hash to a location in the table and scan for it.
- Store keys in table to know when to stop scanning.
- Insertions and deletions are generalizations of lookups
The table’s load factor determines when it is becoming too full and should be resized.
Load Factor = Active Keys / # of Slots; Allocate a new table twice as large and rehash entries
Key-Value Entries:
- Fixed-length: inline store or optionally store the key’s hash with the key for faster comparisons.
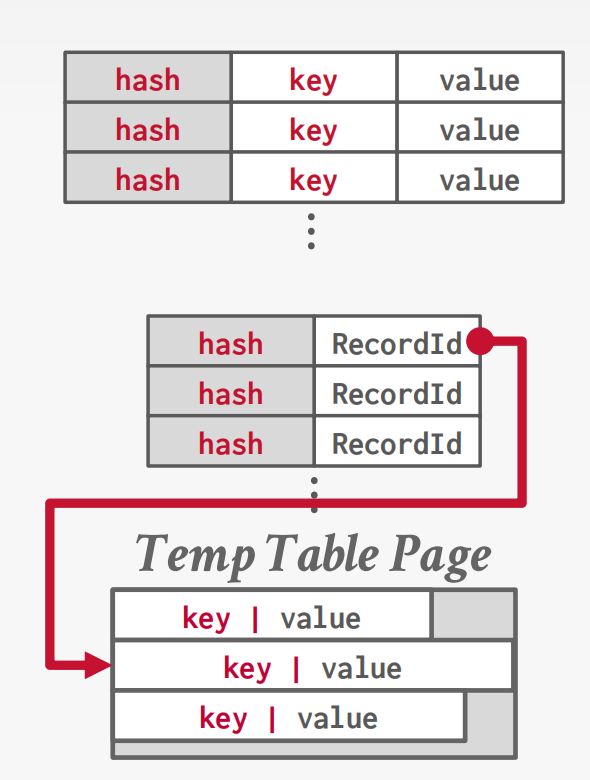
- Variable-length: Insert the kv data in separate a private temporary table and store hash + RecordId
Delete Strategy:
- Movement: After deletion, scan forward and rehash each key until hitting an empty slot to fill the gap. Expensive; no DBMS uses this.
- Tombstone: Mark the slot as deleted. Lookups skip over it; inserts can reuse it. Needs periodic GC. This is what everyone uses.
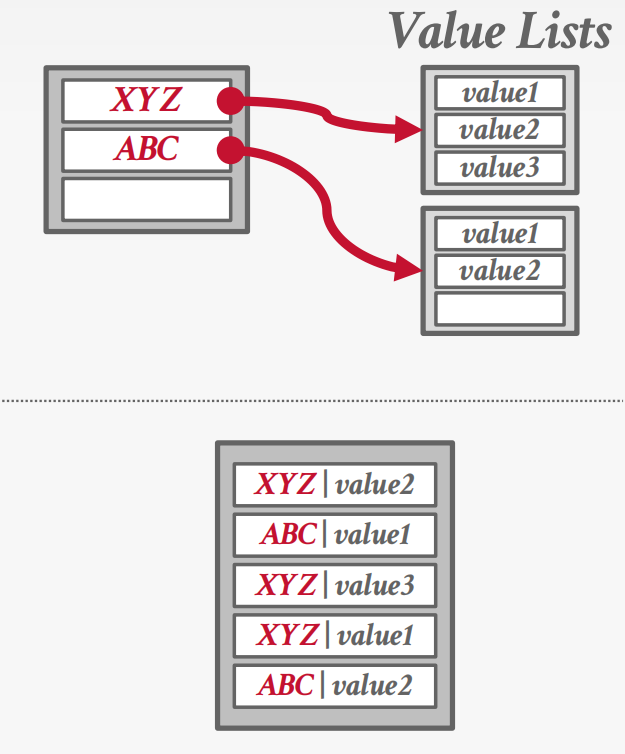
Non-unique Keys:
- Separate Linked List
- Redundant Keys
Optimization:
- Specialization by key type/size: Use different hash table implementations optimized for different key sizes (e.g., short strings vs. long strings) to enable faster comparisons.
- Separate metadata storage: Store a packed bitmap separately to track slot status (empty/tombstone/occupied). Scanning the bitmap is much more cache-friendly than touching every full slot.
- Table + slot versioning: Each slot records the table version when written. To clear the entire table, just increment the global version — any slot with a stale version is treated as empty. O(1) bulk invalidation.
Cuckoo Hashing
Use multiple hash functions to find multiple locations in the hash table to insert records.
- On insert, check multiple locations and pick the one that is empty.
- If no location is available, evict the element from one of them and then re-hash it find a new location.
Dynamic Hashing Schemes
Previous hash tables require the DBMS to know the number of elements it wants to store. Otherwise it must rebuild the table if it needs to grow/shrink in size.
Dynamic hash tables incrementally resize themselves as needed.
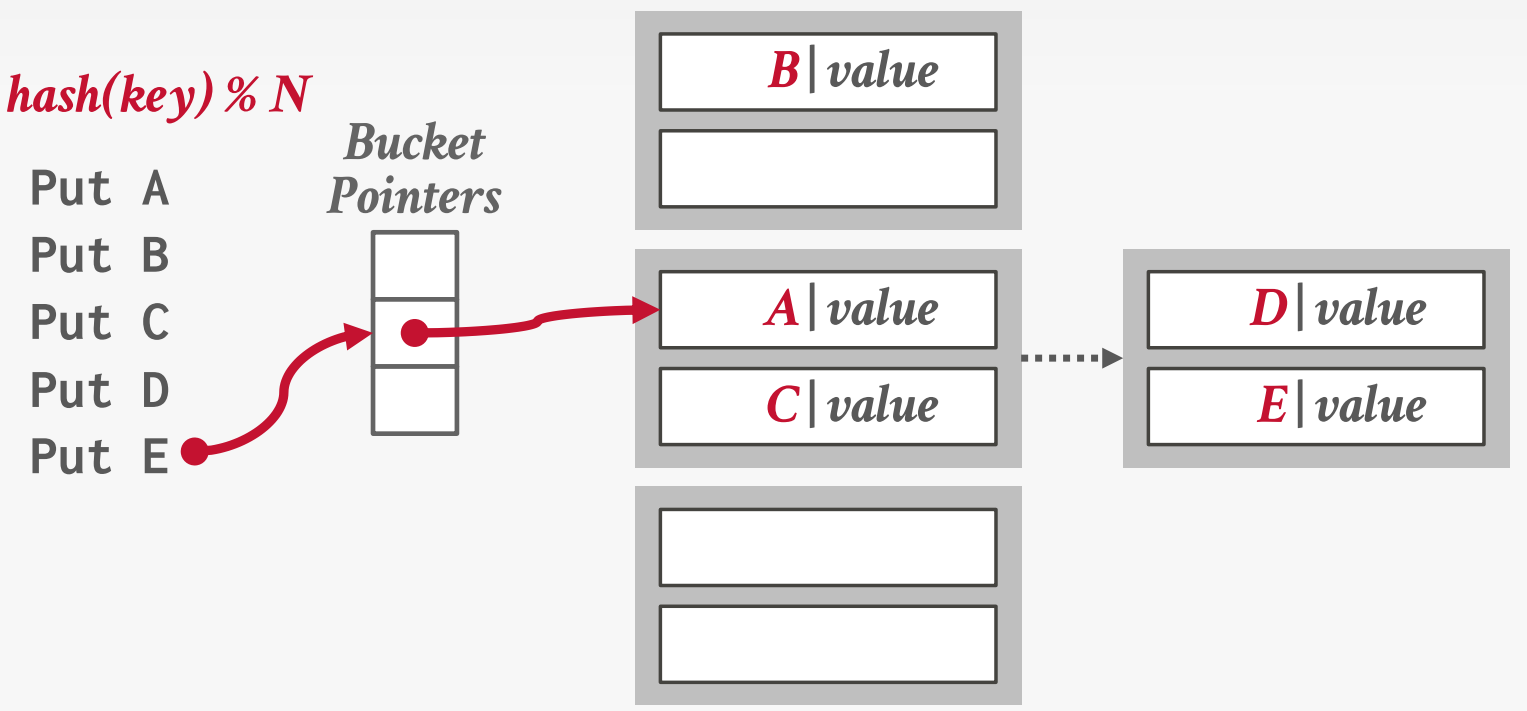
Chained Hashing
Maintain a linked list of buckets for each slot in the hash table.
Resolve collisions by placing all elements with the same hash key into the same bucket.
We can add a bloom filter toe help filter non-exist key.
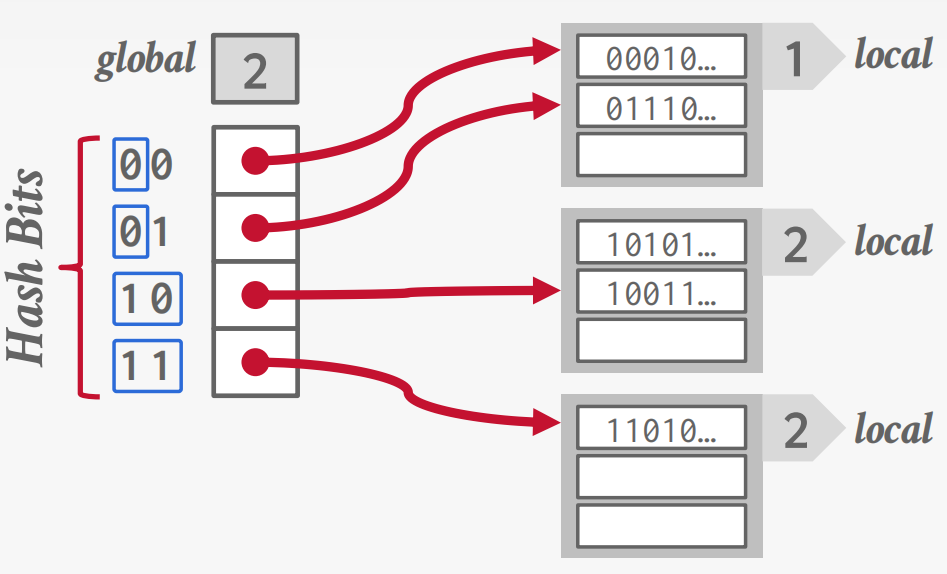
Extendible Hashing
Chained-hashing approach that splits buckets incrementally instead of letting the linked list grow forever.
Multiple slot locations can point to the same bucket chain.
Reshuffle bucket entries on split and increase the number of bits to examine.
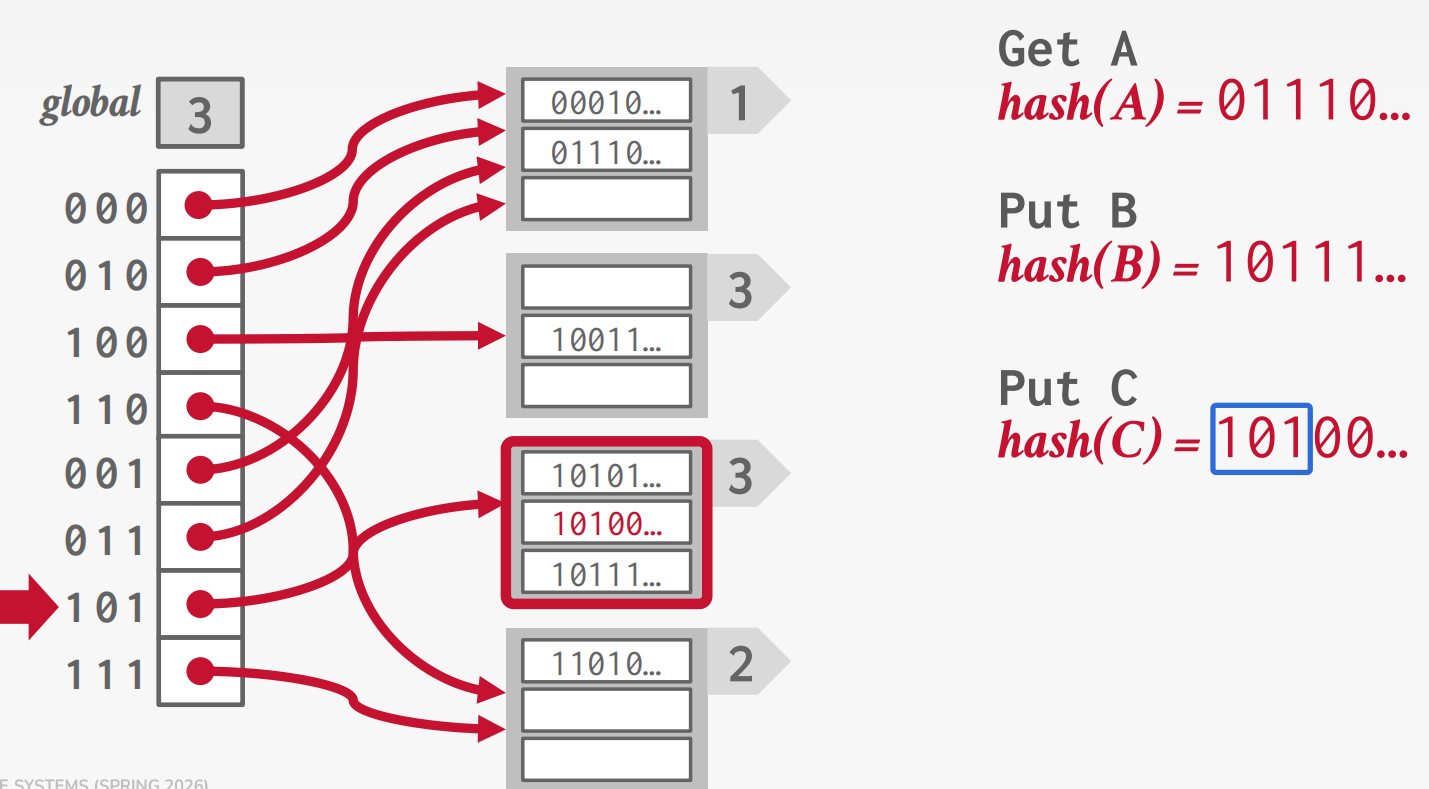
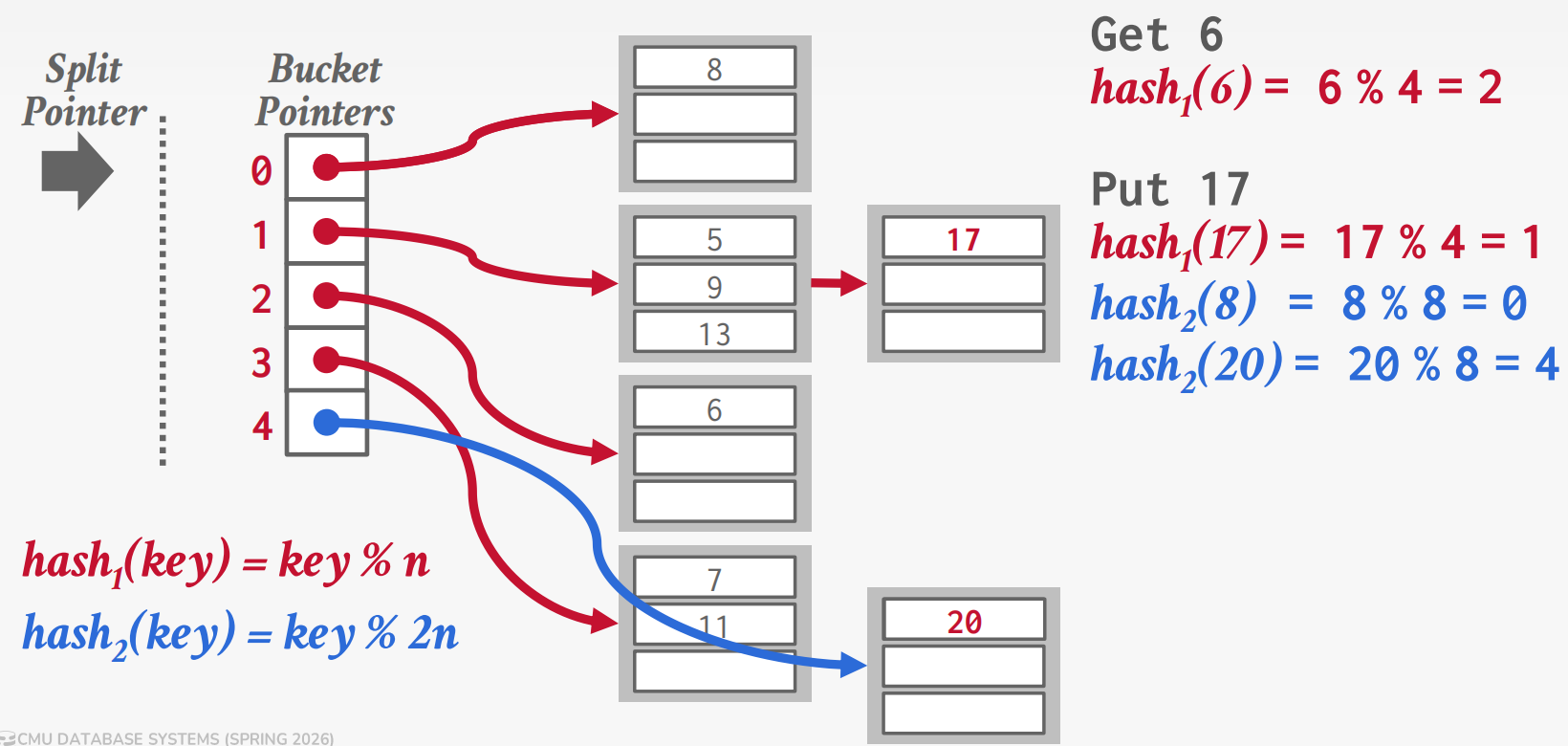
Linear Hashing
Linear Hashing: Maintains a split pointer that
advances sequentially. When any bucket overflows, split the bucket at
the split pointer (not the overflowed one), using
hash2 = key % 2n to redistribute its entries between the
old bucket and a new one.
Lookup rule: Compute hash1(key). If
result < split pointer, that bucket was already split, so use
hash2(key) instead. If result ≥ split pointer,
hash1 is correct.
Round completion: When the split pointer reaches the
end, all buckets have been split. Drop hash1, promote
hash2 to the new hash1, create
hash2 = key % 4n, reset pointer to 0. At most two hash
functions coexist at any time.