11711 Advanced NLP: Architectures
Lec4 Recurrent Neural Networks
Motivation: N-gram and feedforward models have limited context (N-1 tokens). RNNs provide theoretically infinite context.
Three Types of Sequence Models
- Recurrence: Condition representations on an encoding of history
- Convolution: Condition representations on local context
- Attention: Condition representations on weighted average of all tokens
Basic RNN (Elman, 1980)
A sequence model \(f_\theta(x_1, \ldots, x_{|x|}) \rightarrow h_1, \ldots, h_{|x|}\) that transforms a hidden state at each step:
\[h_t = \sigma(W_h h_{t-1} + W_x x_t + b)\]
where \(\sigma\) is activation (tanh, relu), \(h_t \in \mathbb{R}^d\) is hidden state, parameters \(\theta = \{W_h \in \mathbb{R}^{d \times d}, W_x \in \mathbb{R}^{d \times d_{in}}, b \in \mathbb{R}^d\}\)
For language modeling: \(p_\theta(\cdot \mid x_{<t}) = \text{softmax}(W h_t)\)
RNN Training
Backpropagation Through Time (BPTT): Unroll the RNN into a DAG computation graph, run standard backprop.
- Same parameters at each step; gradients are accumulated
- Training objective (MLE): \(\min -\sum_{x \in D_{train}} \sum_t \log p_\theta(x_t \mid x_{<t})\)
- Parallelization is difficult: Computing loss at step \(t\) requires \(h_t\), which depends on \(h_{t-1}, h_{t-2}, \ldots\)
RNN Inference
Generate one token → use new hidden state → repeat until
[EOS]
- Pros: Only need to store previous hidden state (constant memory), \(O(1)\) per step, \(O(T)\) total for length \(T\)
- Cons: Sequential, cannot parallelize
Vanishing Gradients
Gradients decrease as they propagate back: \(\frac{\partial L}{\partial h_0}\) becomes tiny.
Why? \(\frac{\partial h_T}{\partial h_t} = \prod_{t'=t}^{T} \frac{\partial h_{t'+1}}{\partial h_{t'}}\), where \(\frac{\partial h_{t'+1}}{\partial h_{t'}} = \text{diag}(\tanh'(\cdot)) W\)
When dominant eigenvalue of \(W < 1\), gradients vanish exponentially. Implication: Cannot model long-range dependencies!
Gating: The Solution
Basic idea: Pass information across timesteps with learned gates.
\[h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t\]
where \(z_t = \sigma(W_z x_t + U_z h_{t-1})\) is update gate, \(\tilde{h}_t\) is candidate state.
- When \(z \to 0\): retain long-term info (\(\frac{\partial h_{t_2}}{\partial h_{t_1}} = 1\))
- When \(z > 0\): incorporate new hidden state
GRU (Cho et al., 2014)
2-gate architecture: - Update gate \(z_t\): should I update the previous hidden state? - Reset gate \(r_t = \sigma(W_r x_t + U_r h_{t-1})\): should I use hidden state in update?
\[\hat{h}_t = \tanh(W_h x_t + U_h(r_t \odot h_{t-1})), \quad h_t = (1-z_t) \odot h_{t-1} + z_t \odot \hat{h}_t\]
LSTM (Hochreiter & Schmidhuber, 1997)
4-gate architecture with additional context vector. In practice, GRU/LSTM are drop-in replacements for vanilla RNN.
Encoder-Decoder
Motivation: Conditional generation \(p_\theta(y_1, \ldots, y_T \mid x)\) (e.g., translation, summarization)
Architecture: Encode input \(x\) into context vector \(c \in \mathbb{R}^d\), use it in decoder: - Initialize decoder hidden state - Include in recurrent update: \(W[h_t; x_t; c]\) - Include in output layer: \(\text{softmax}(W[h_t; c])\)
Training: \(\min_\theta \sum_{(x,y) \in D} \sum_t -\log p_\theta(y_t \mid y_{<t}, x)\)
Limitation: Single context vector for all tokens — can we do better?
Attention (Bahdanau et al., 2015)
Key idea: Compute a different context vector at each decoder step as a weighted sum of encoder states.
- Keys: Encoder states \(h_1^{enc}, \ldots, h_N^{enc}\)
- Query: Current decoder hidden state \(h\)
- Attention scores: \(\alpha_n = \text{score}(h, h_n^{enc})\)
- Context vector: \(c = \sum_{n=1}^{N} \alpha_n h_n^{enc}\)
Score functions: - Dot product: \(\text{score}(q, k) = q^\top k\) - Bilinear: \(\text{score}(q, k) = q W k\) - Nonlinear: \(\text{score}(q, k) = w^\top \tanh(W[q; k])\)
Usage: \(\text{logits} = \tanh(W_{out}[c_t; h_t])\)
Key Takeaways
- RNN: sequence model with recurrent hidden state (theoretically infinite context)
- Vanilla RNN suffers from vanishing gradients → use GRU/LSTM
- Encoder-decoder for conditional generation
- Attention: dynamic context vector via weighted sum of encoder states
- RNN training is sequential (hard to parallelize) → motivates Transformers (next lecture)
Lec5 Transformers
This content is kind of like CS336-Lec3 Architectures & Hyperparameters
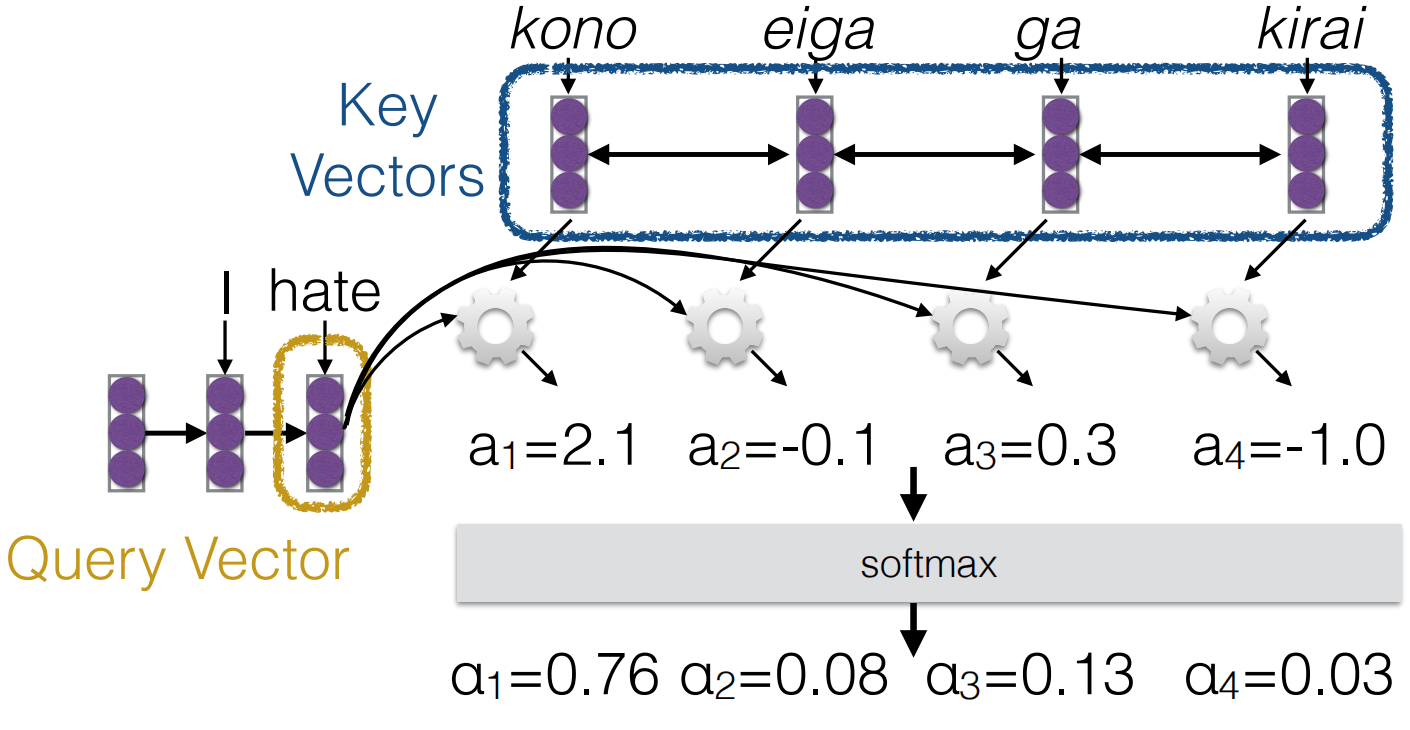
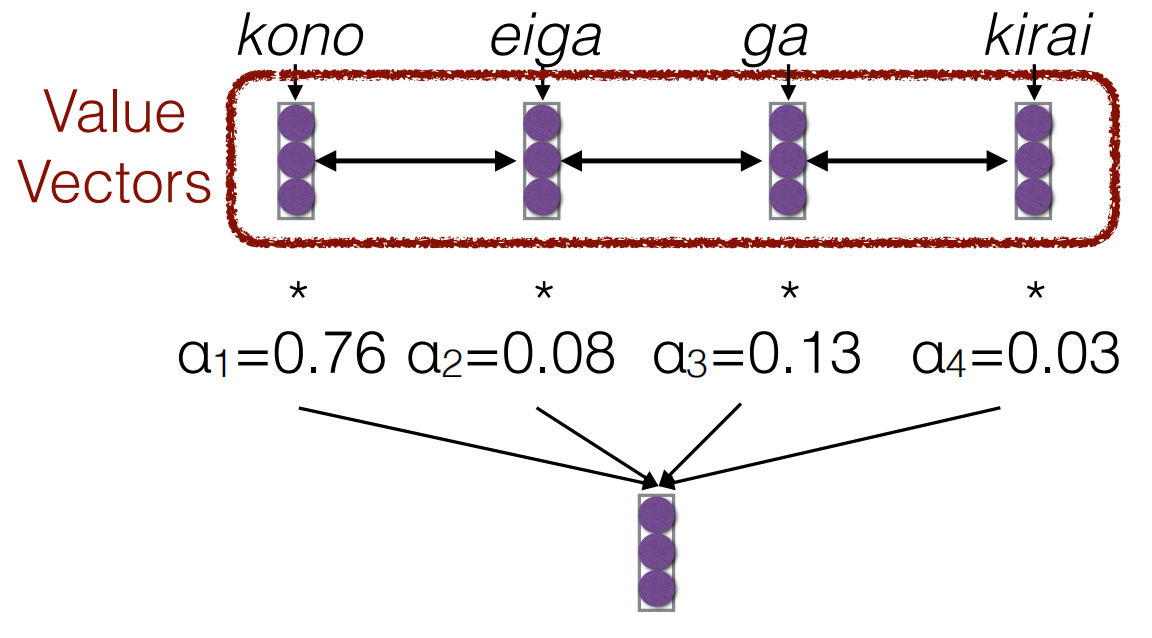
Attention Score Functions: The most
frequently used function is Scaled Dot Product.
this solve the problem that scale of dot product increases as dimensions
get larger. \[
a(q, k) = \frac{q^\top k}{\sqrt{|k|}}
\]
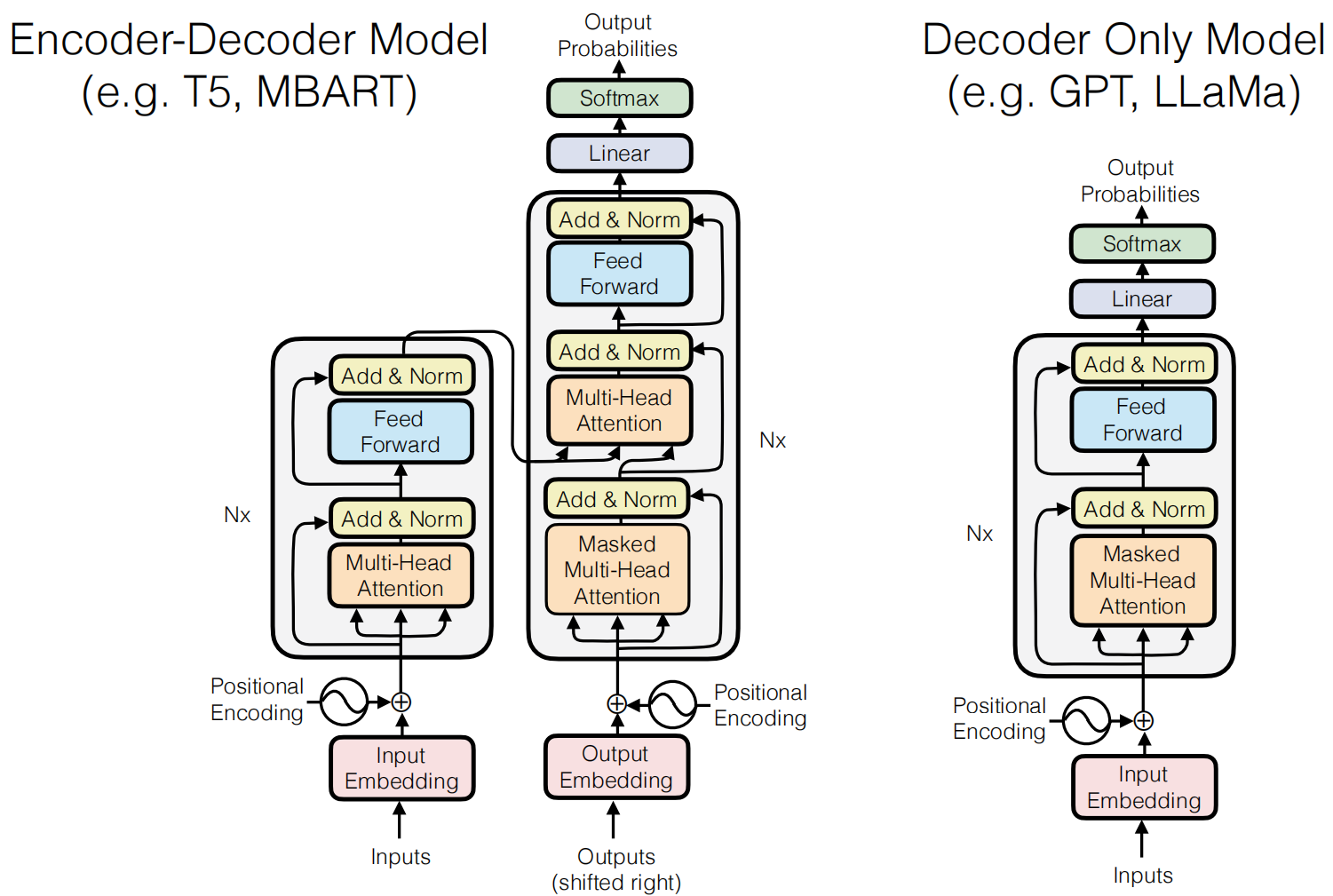
Intuition for Multi-heads: Information from different parts of the sentence can be useful to disambiguate in different ways.