
11868 LLM Sys: GPU Programming & Acceleration
GPU Programming
Neural Network Layer and low-level operators
A simple feedforward neural network for text classification consists of a sequence of standard layers. The input text is first mapped to vectors using an embedding layer, followed by linear layers with ReLU activations. An average pooling operation aggregates token representations into a single vector, and a softmax layer produces the final class probabilities.
At a lower level, these neural network layers are implemented using a small set of basic operations. Matrix multiplication is used in linear layers, element-wise operations handle activations, and reduction operations such as averaging are used for pooling. Efficient execution of these operations relies heavily on GPUs.
Components of A GPU Server
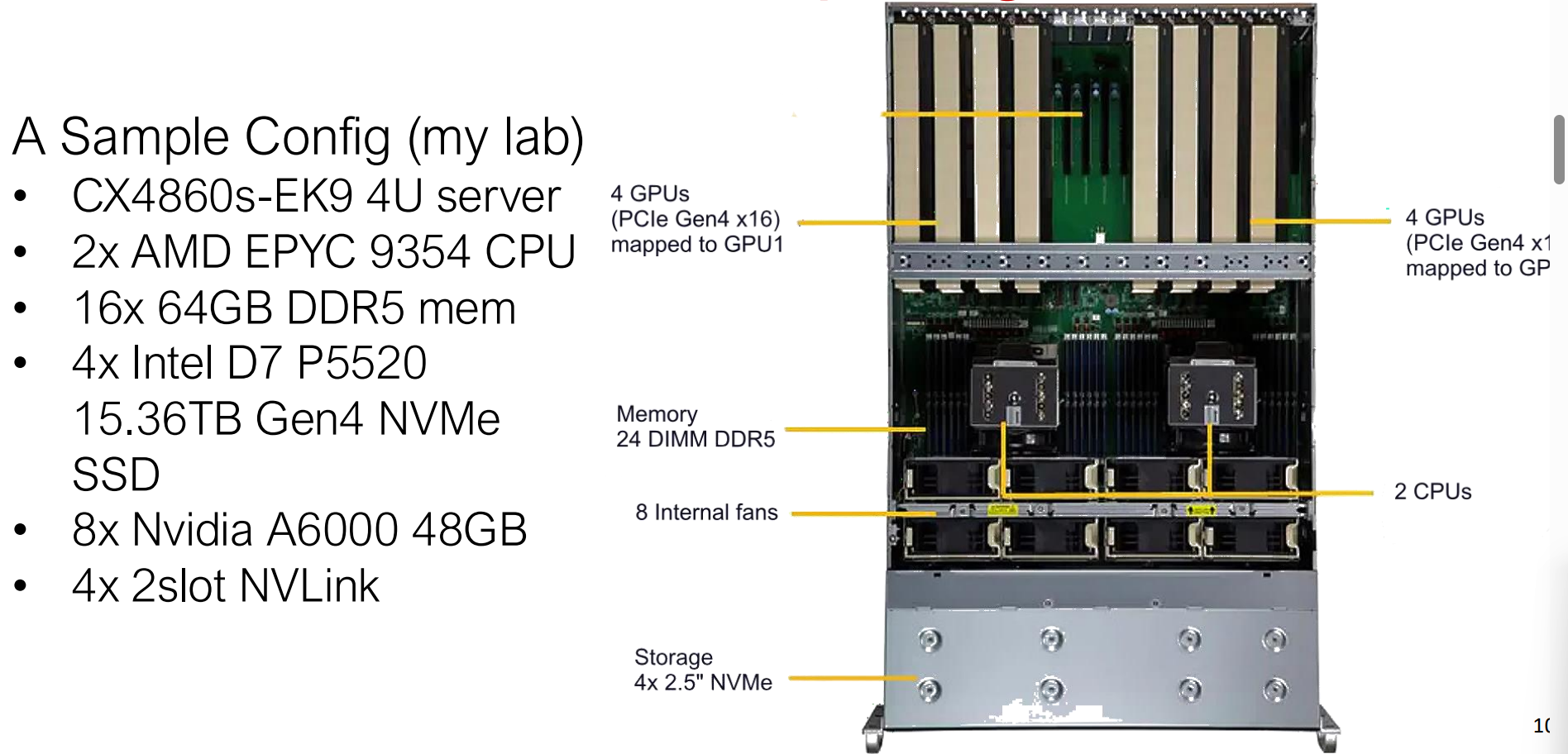
This figure illustrates a modern 4U computing server designed for high-performance and AI workloads. It combines dual AMD EPYC CPUs with multiple NVIDIA GPUs connected via PCIe and NVLink, alongside high-bandwidth DDR5 memory and NVMe storage to support large-scale parallel computation.
GPU Architecture
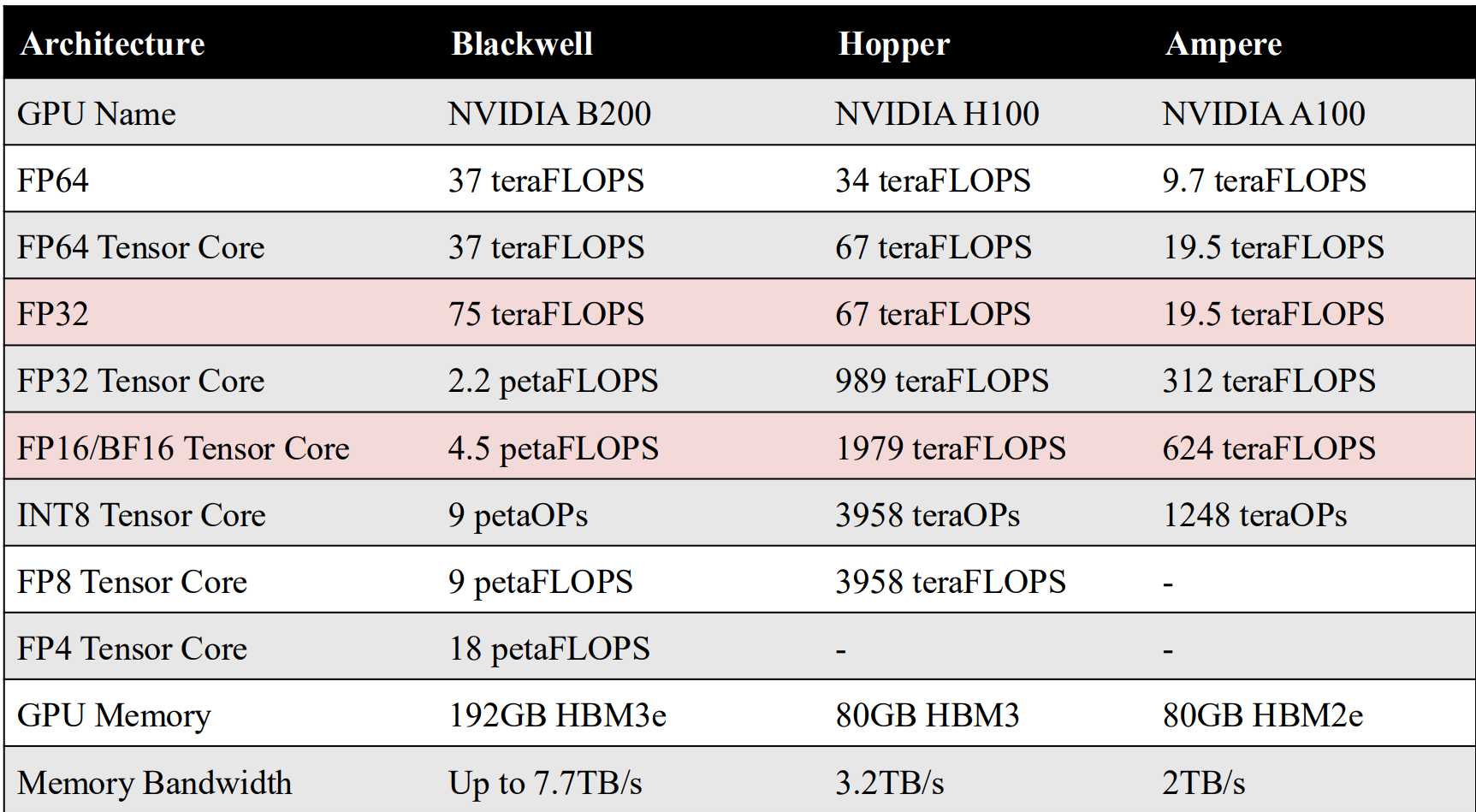
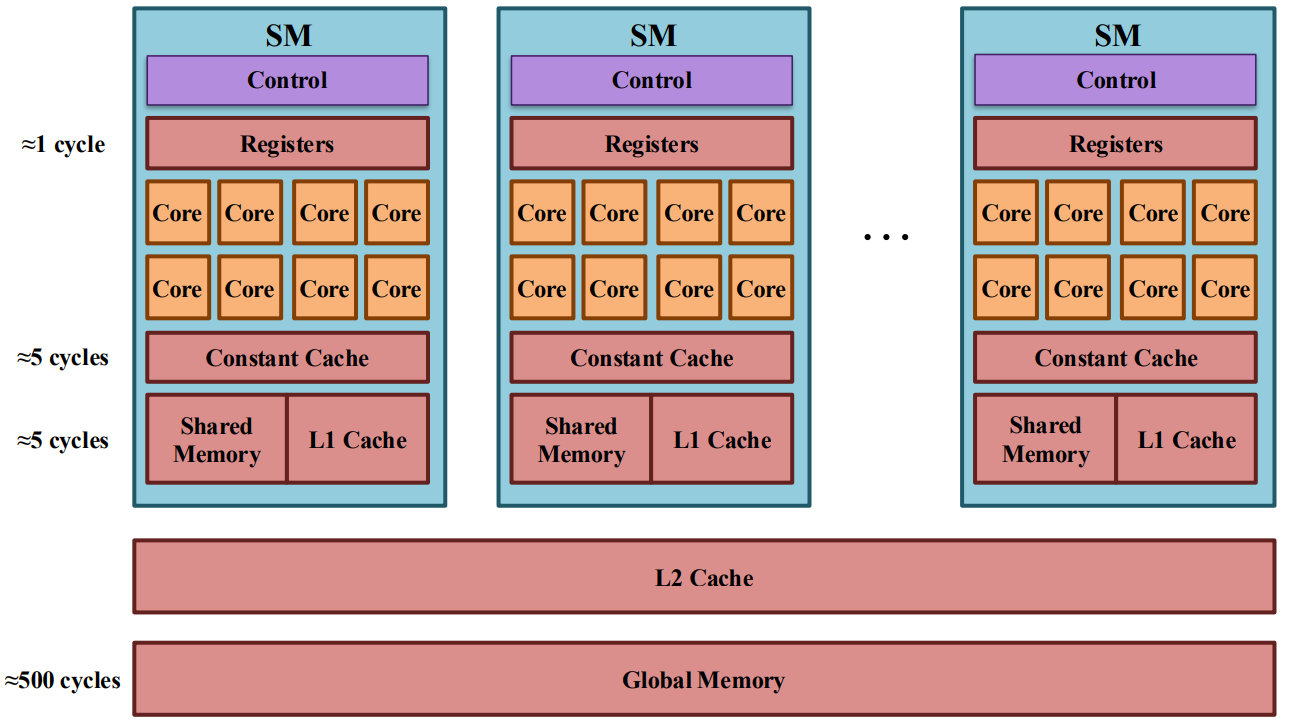
Modern GPUs achieve high performance by prioritizing throughput-oriented parallelism rather than single-thread latency. Instead of a few complex cores like CPUs, a GPU consists of many Streaming Multiprocessors (SMs), each of which contains a large number of simple compute cores designed to execute the same operations in parallel.
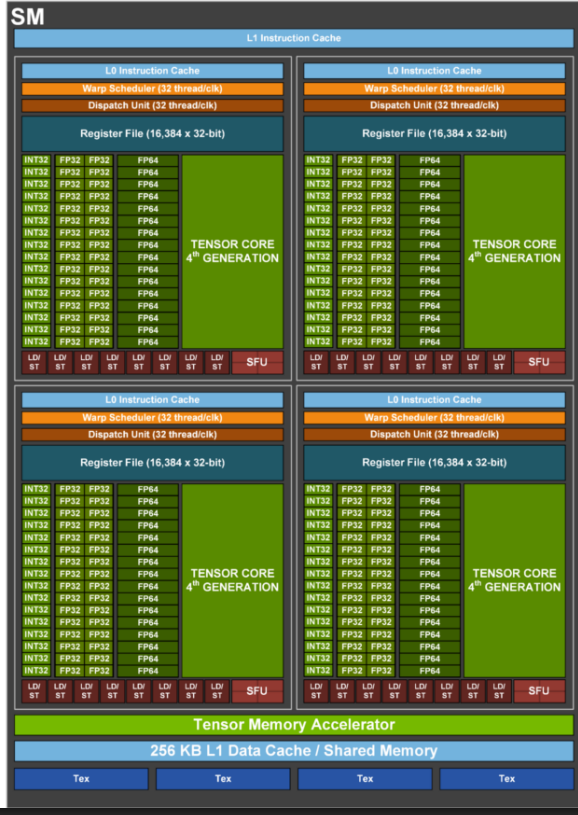
An SM is the fundamental execution unit of a GPU. Each SM is divided into four partitions, and each partition contains 32 CUDA cores, matching the size of a warp, which is the basic scheduling and execution unit in NVIDIA GPUs. A warp consists of 32 threads that execute the same instruction in lockstep (SIMT: Single Instruction, Multiple Threads). As a result, a single SM contains 128 cores and can execute up to 128 FP32 operations per cycle under ideal conditions.
Within each partition, a warp scheduler selects a ready warp every cycle, while the dispatch unit issues its instruction to the appropriate execution units (e.g., FP32 cores, Tensor Cores, or load/store units). GPUs do not schedule individual threads; instead, they schedule warps. When one warp stalls due to memory access, the scheduler can immediately switch to another ready warp with negligible overhead, allowing GPUs to effectively hide memory latency through massive concurrency.
Each SM also contains a large register file (the fastest on-chip storage) and a shared L1 cache / shared memory, which enable fast data reuse and communication between threads within a block. Newer architectures such as NVIDIA H100 significantly increase the L1/shared memory capacity and enhance Tensor Cores, further optimizing the SM for large-scale matrix and tensor computations commonly found in deep learning workloads.
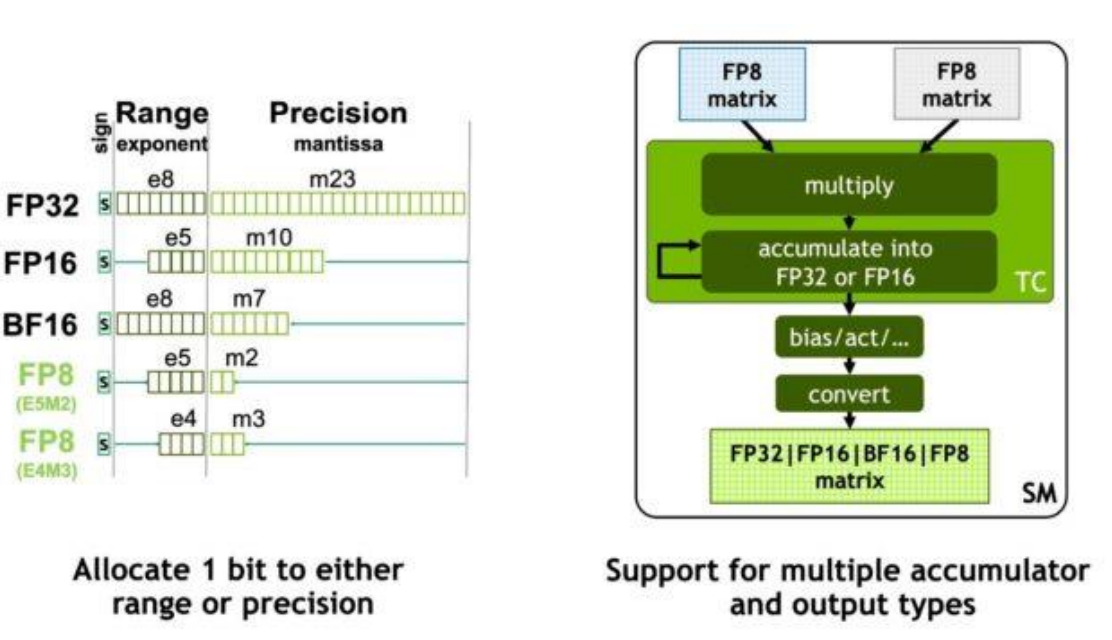
H100 introduces FP8 to further improve throughput and reduce memory bandwidth requirements for large-scale AI workloads. By supporting multiple FP8 formats and accumulating results in higher precision, the architecture achieves both high performance and numerical stability.
Transformer Engine is a hardware–software co-designed system in H100 that automatically manages precision, scaling, and accumulation to safely use FP8 for Transformer workloads.
CPU vs. GPU
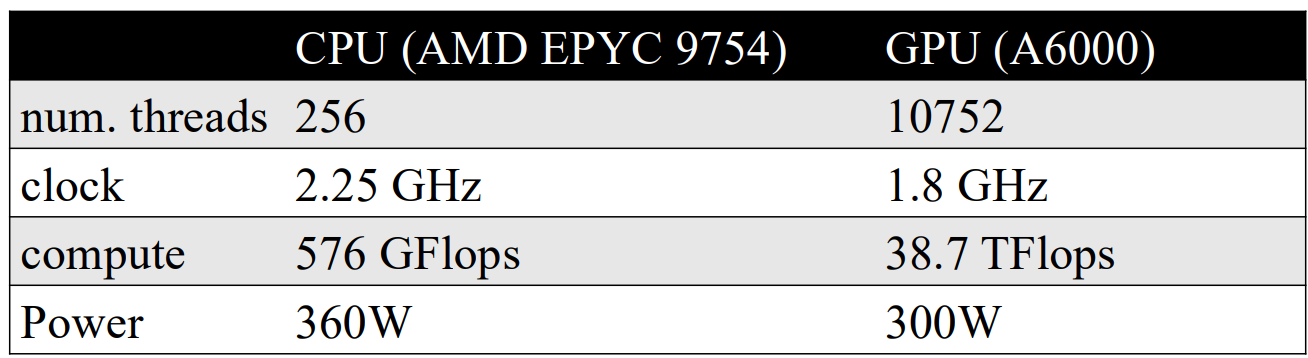
Program Execution on GPU
In the CUDA programming model, the CPU acts as the host that controls execution and launches GPU kernels, while the GPU serves as a device optimized for massively parallel computation. Kernels are executed using a SIMT model, where threads are organized into blocks and grids and mapped onto multiple SMs for parallel execution.
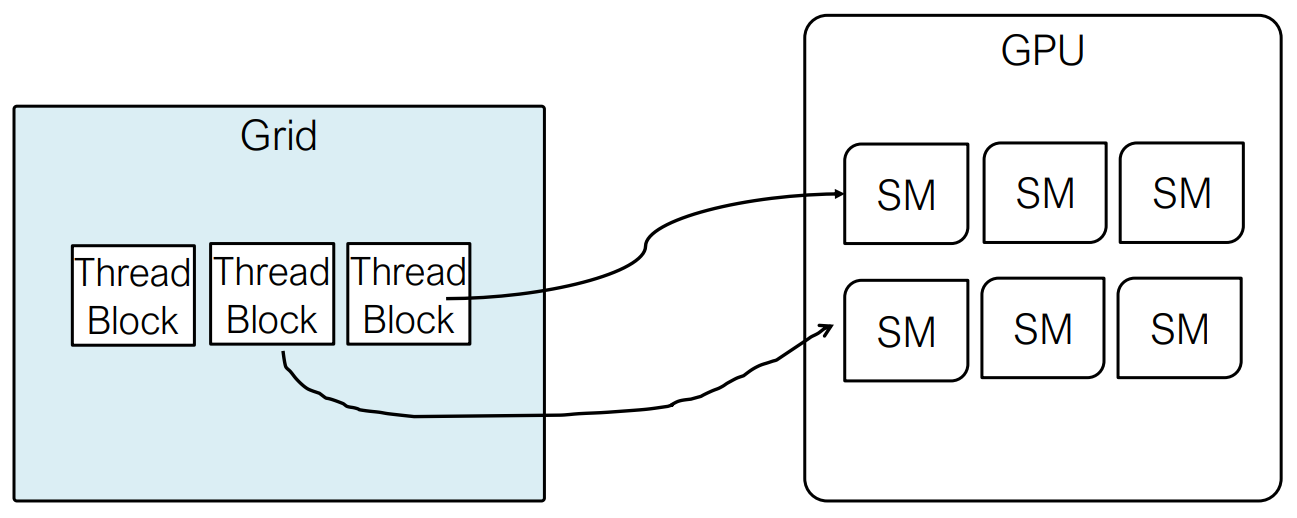
How Kernel Threads are Executed
When a CUDA kernel is launched, threads are first organized into thread blocks, which are then assigned to Streaming Multiprocessors (SMs). Within an SM, each thread block is further partitioned into warps, and warp is the fundamental unit used by the GPU to create, manage, schedule, and execute threads.
A warp consists of 32 threads. All threads in a warp start execution at the same program address, but each thread maintains its own program counter and register state. At any given cycle, a warp executes one common instruction across all 32 threads, following the SIMT (Single Instruction, Multiple Threads) execution model. Although threads within a warp can take different control-flow paths due to branching, divergent paths are serialized by the hardware, which can reduce performance.
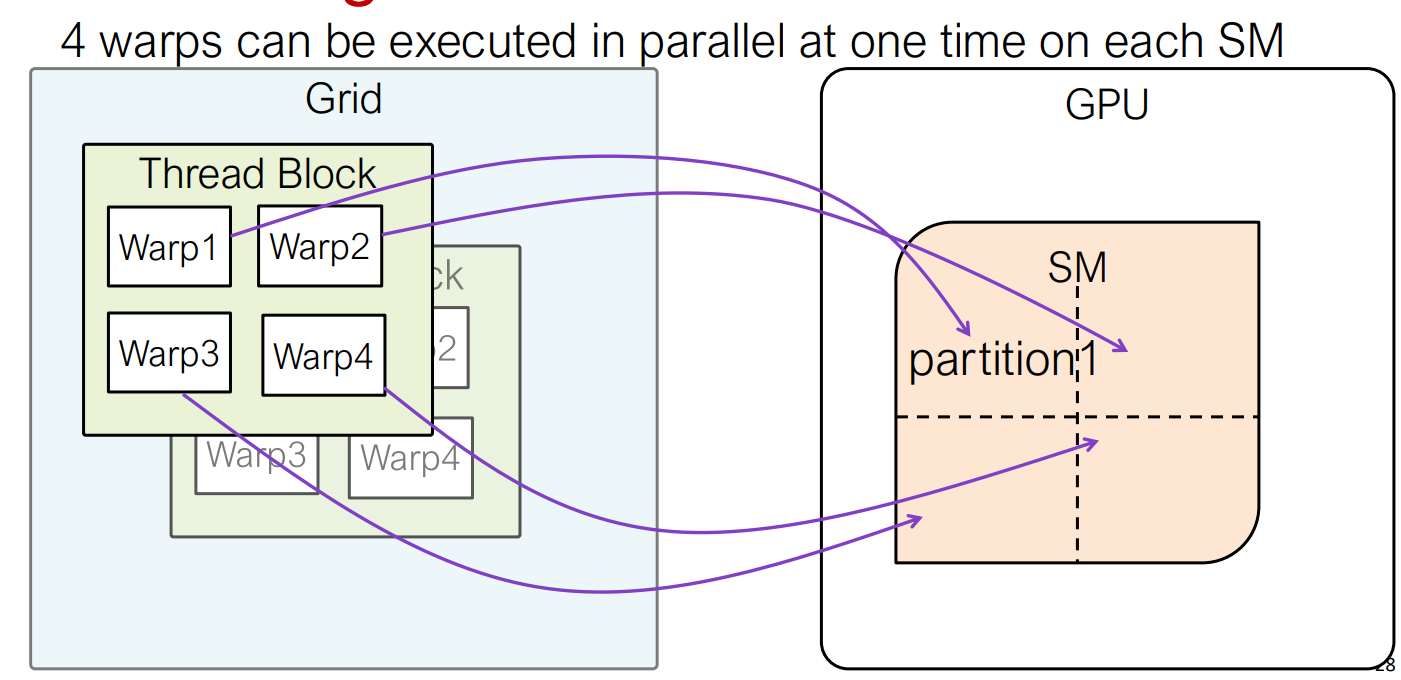
Warp Execution Model on an SM
Once a warp is assigned to an SM, its execution context remains resident on the SM for the entire lifetime of the warp. This context includes the program counter, register values, and any shared memory used by the warp. Because all active warps keep their contexts on-chip, switching between warps does not require saving or restoring state, making warp-to-warp context switching effectively instantaneous.
At runtime, each SM contains one or more warp schedulers, which continuously select a warp with active and ready threads. The selected warp’s next instruction is then issued (dispatched) to the appropriate execution units, such as FP32 cores, Tensor Cores, or load/store units. If a warp stalls due to a long-latency operation (e.g., global memory access), the scheduler can immediately switch to another ready warp, allowing the SM to hide memory latency through concurrency.
Although NVIDIA GPUs expose a SIMT programming model, warp execution is implemented using SIMD-style vector execution with predication and masking at the hardware level.
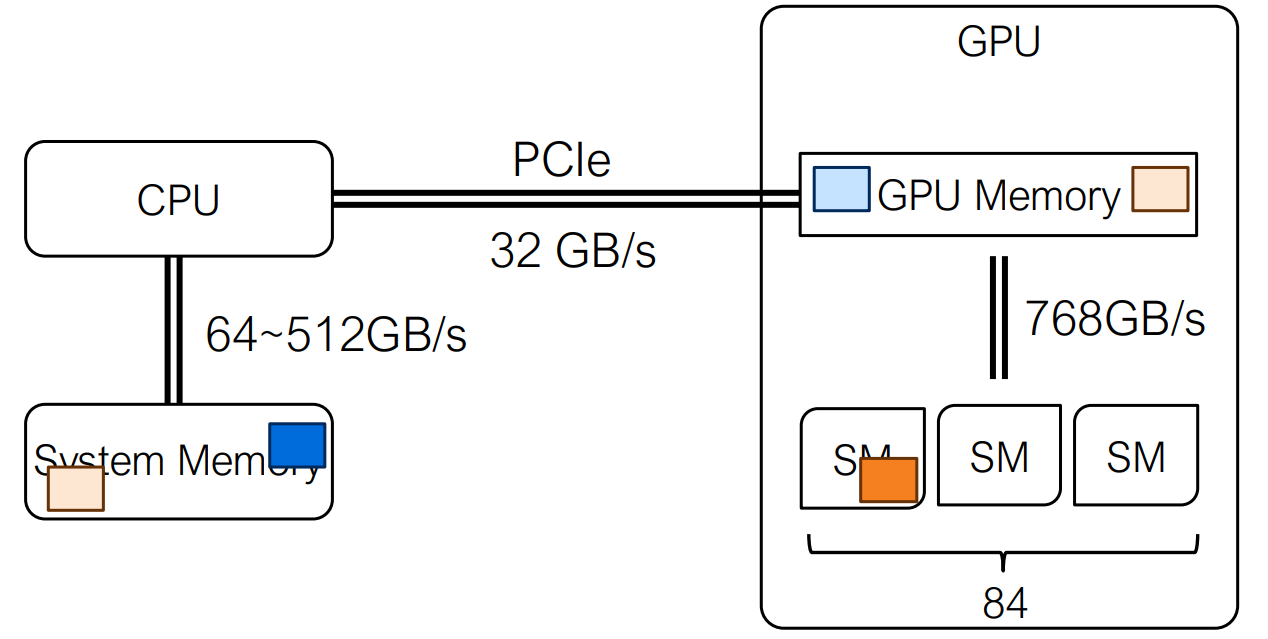
CPU-GPU Data Movement
CUDA Kernel
A CUDA kernel is a function that runs on the GPU. From a programming perspective, a kernel describes the execution logic for a single thread, and the code itself is written in a serial manner. Parallelism does not come from the code structure, but from the fact that the kernel is executed simultaneously by a large number of threads.
When a kernel is launched, thousands of threads may
execute the same kernel function concurrently. Each thread uses its
thread index (e.g., threadIdx,
blockIdx) to determine which portion of the data it
operates on. This follows the SPMD (Single Program, Multiple Data)
model: the same program is replicated across many threads, each working
on different data elements.
Key characteristics of CUDA kernels:
- The kernel code is serial per thread
- Massive parallelism is achieved by many threads executing the same kernel
- Thread indices are used to map threads to data
- The programmer expresses what one thread does, not how threads are scheduled
Compiling CUDA Code
CUDA programs follow a heterogeneous programming model, where a single source file contains both host (CPU) code and device (GPU) code. The CUDA compiler, NVCC, acts as a compiler driver that separates these two parts and compiles them differently.
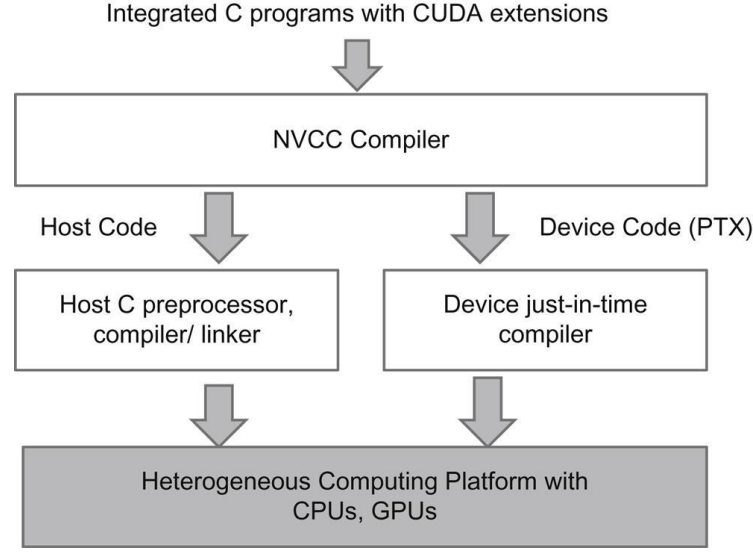
During compilation:
- Host code is passed to a standard C/C++ compiler
(e.g.,
gccorclang) and compiled into CPU-executable code. - Device code (CUDA kernels) is compiled into PTX, an intermediate representation for NVIDIA GPUs.
At runtime, the PTX code is just-in-time (JIT) compiled by the NVIDIA driver into machine code specific to the target GPU architecture. This design allows the same CUDA binary to run on different GPU generations without recompiling the source code.
PTX serves as an intermediate representation rather than final machine code. At runtime, the NVIDIA driver JIT-compiles PTX into architecture-specific GPU instructions, enabling the same CUDA binary to run across different GPU generations.
Basic GPU CUDA operations
In CUDA, all GPU operations are orchestrated by the CPU. The host
explicitly allocates device memory using cudaMalloc,
transfers data between host and device with cudaMemcpy,
launches GPU kernels, and finally releases device memory with
cudaFree. This explicit memory management model reflects
CUDA’s heterogeneous design, where the GPU acts as a compute accelerator
controlled by the CPU.
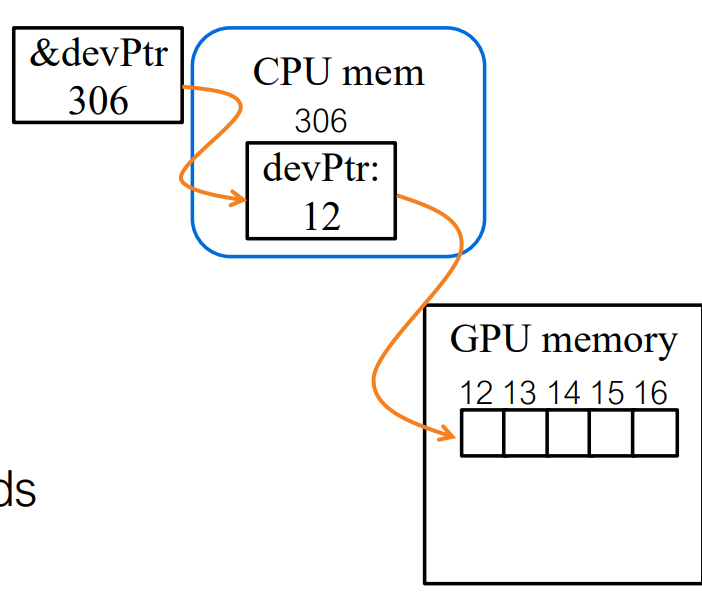
GPU Memory
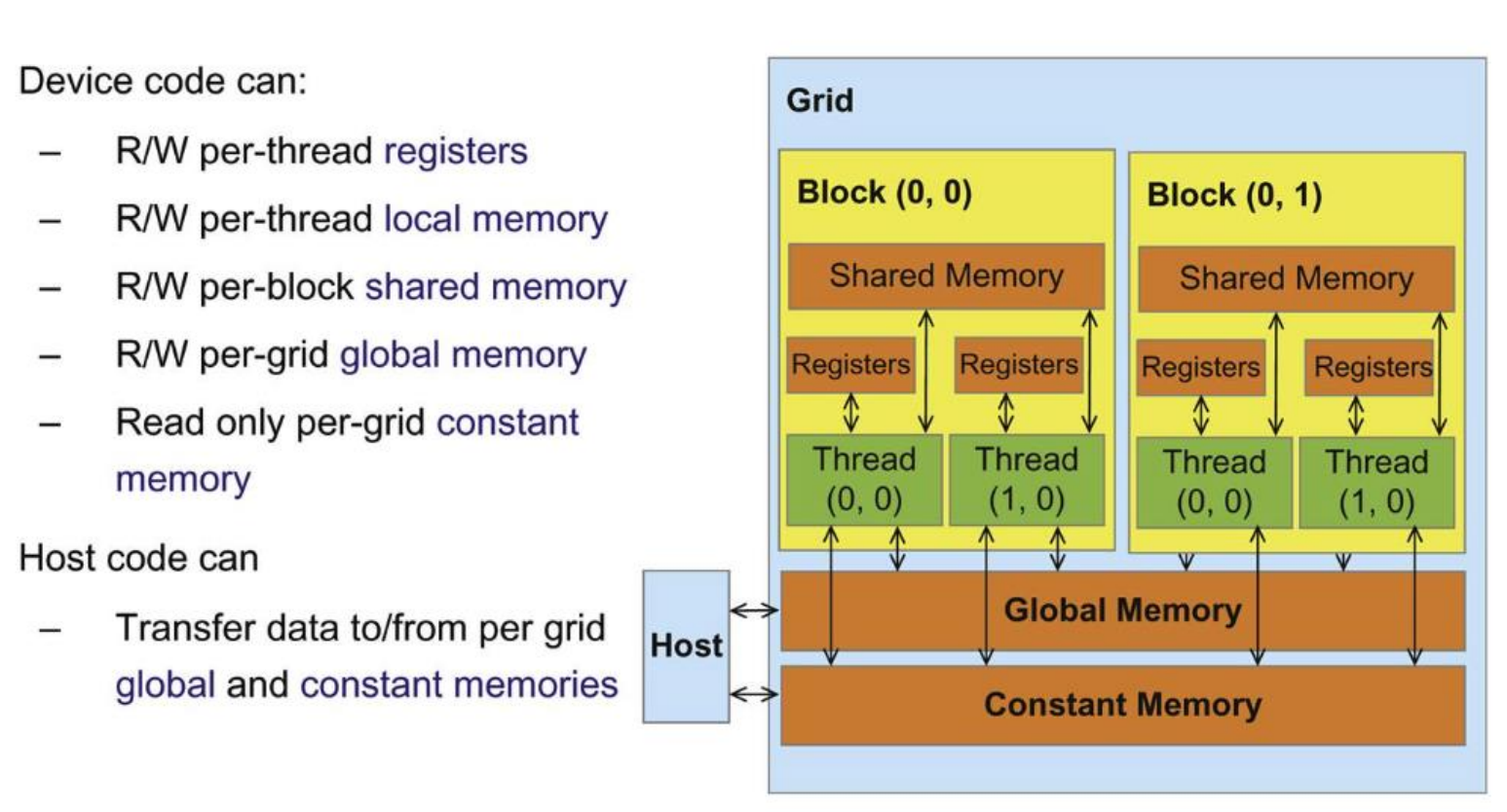
CUDA provides a hierarchical memory model. Each thread has private registers, which are the fastest memory to access.
Threads within the same thread block can communicate
through shared memory, which is explicitly
declared with __shared__ and has much lower latency than
global memory.
In contrast, global memory is accessible by all threads across all blocks and persists across kernel launches, but it has the highest access latency.
Data Movement
Data movement between the CPU and GPU is explicitly managed by the
programmer using cudaMemcpy. Memory can be copied
from host to device or from device to
host, with the transfer size specified in bytes. Since CPU–GPU
data transfers are relatively expensive, performance-critical
applications aim to minimize such transfers and maximize data reuse on
the GPU.

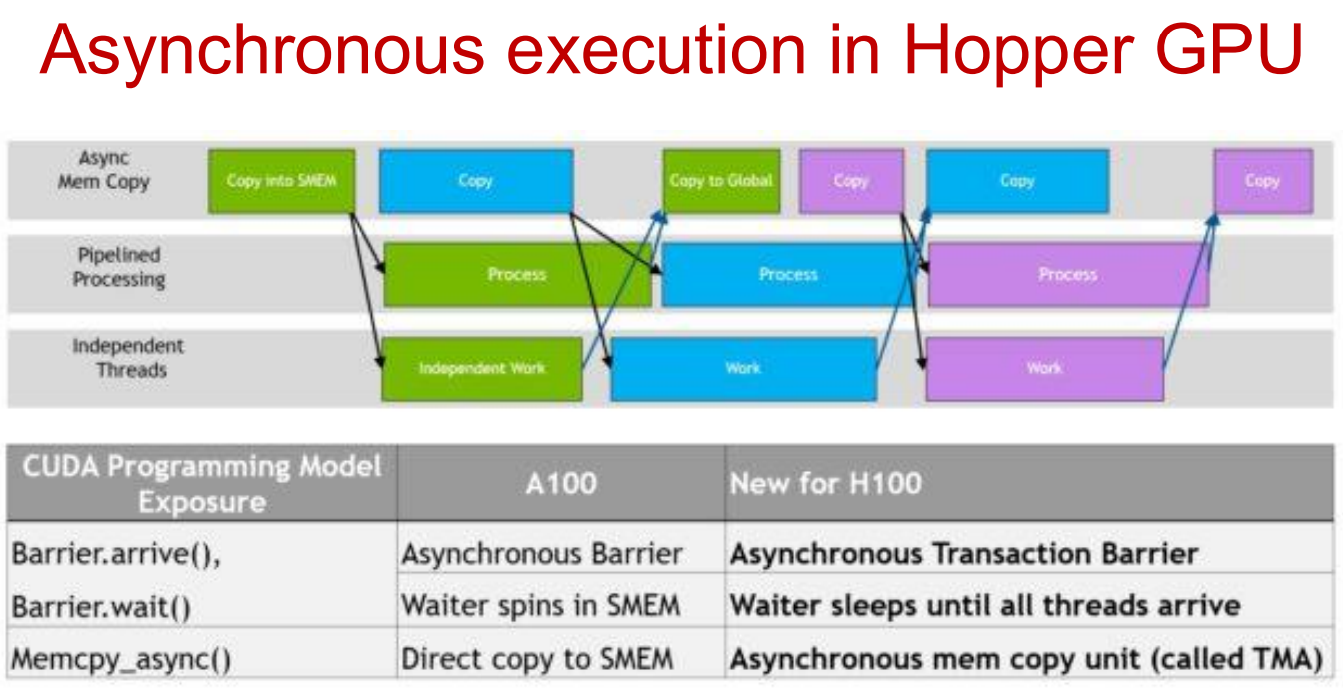
On each Streaming Multiprocessor (SM), instructions are issued to execution units through a limited number of issue slots per cycle. An issue slot represents the hardware capacity to dispatch an instruction from a warp in a given cycle, and thus directly limits instruction throughput on the SM.
In pre-Hopper architectures (e.g., A100), warps waiting for memory operations—such as asynchronous copies into shared memory—still participate in scheduling. Even when a warp is stalled on a barrier, it repeatedly checks readiness, occupying issue slots and reducing overall SM utilization.
Hopper introduces a key change in this execution model. With the Tensor Memory Accelerator (TMA), memory transfers are offloaded to a dedicated hardware unit, and warps waiting on copy completion are put into a sleep state. Sleeping warps are removed from the scheduler’s active set and no longer consume issue slots. As a result, issue slots are exclusively used by warps that are ready to execute computation, enabling higher instruction throughput and more effective overlap between memory movement and compute.
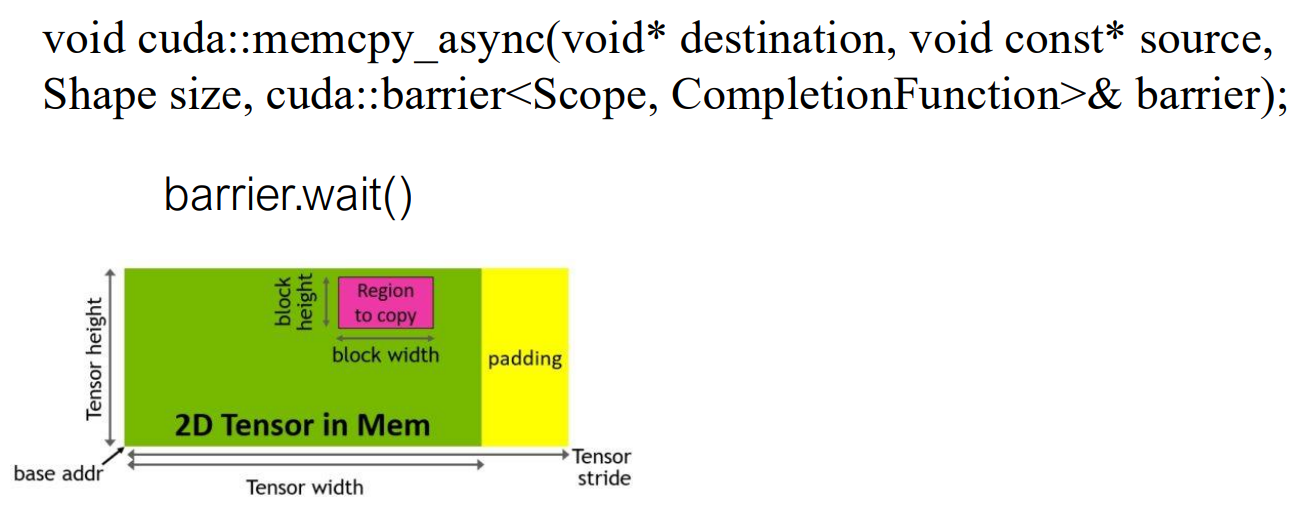
Declaration of Host/Device function
| Keyword | Call on | Execute On | Used |
|---|---|---|---|
__global__ |
host(CPU) | device(GPU) | GPU kernel |
__device__ |
device | device | GPU Func |
__host__ |
host | host | Normal CPU Func |
CUDA distinguishes host and device functions using explicit
qualifiers. A __global__ function defines a GPU kernel,
which is launched from the CPU but executed in parallel by many threads
on the GPU. Each thread runs the same kernel code and uses its thread
and block indices to determine which portion of the data it
processes.
Calling Kernel at Runtime
In CUDA, a kernel’s parallel execution configuration is specified at runtime by the host (CPU) rather than being fixed at compile time. When launching a kernel, the host explicitly defines the grid–block–thread hierarchy, which determines how many GPU threads will execute the kernel.
A kernel is launched using the special syntax:
1 | kernelFunc<<<Dg, Db>>>(args); |
Here, Dg (grid dimension) and Db (block
dimension) can be specified either as integers or as dim3
objects:
1 | dim3 Dg(4, 2, 1); |
Dgdefines the size of the grid, i.e., the number of thread blocks.Dbdefines the size of each block, i.e., the number of threads per block.
The total number of blocks is Dg.x * Dg.y * Dg.z, and
the total number of threads per block is
Db.x * Db.y * Db.z, which must not exceed 1024 on current
NVIDIA GPUs.
Device Runtime Variables
Once a kernel is launched, each thread executing on the GPU must be able to identify which block it belongs to and which thread it is within that block. CUDA provides a set of built-in device-side variables for this purpose, which are automatically generated by the compiler.
These variables include:
gridDim(dim3): dimensions of the gridblockIdx(uint3): index of the current block within the gridblockDim(dim3): dimensions of a blockthreadIdx(uint3): index of the current thread within the block
All kernel threads execute the same code, but by using these variables, each thread can compute a unique global index. A common pattern is:
1 | int i = blockIdx.x * blockDim.x + threadIdx.x; |
This allows threads to map naturally to elements of arrays or other data structures stored in global memory.
Calling a CUDA Kernel from the CPU
In practice, the host typically computes the grid and block sizes
based on the input problem size. For example, when processing a vector
of length n, a common approach is to choose a fixed number
of threads per block and compute the number of required blocks using
integer division with rounding up:
1 | int n = 1024; |
When this launch occurs:
- The CPU issues the kernel launch with the specified grid and block configuration.
- The GPU creates the grid of blocks and schedules them onto available Streaming Multiprocessors (SMs).
- Each block is further divided into warps, and threads execute the kernel code in parallel.
- Each thread determines which data element it operates on using
blockIdx,blockDim, andthreadIdx.
GPU Acceleration
Memory Access Efficiency
CUDA Device Memory Model

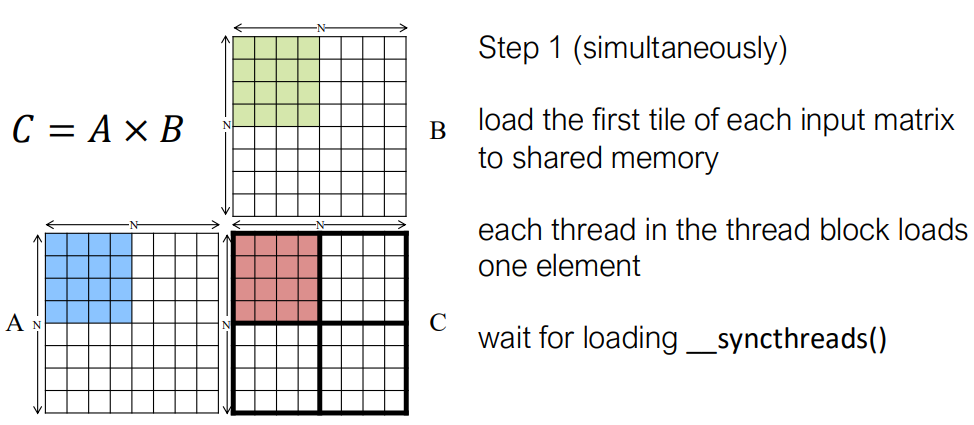
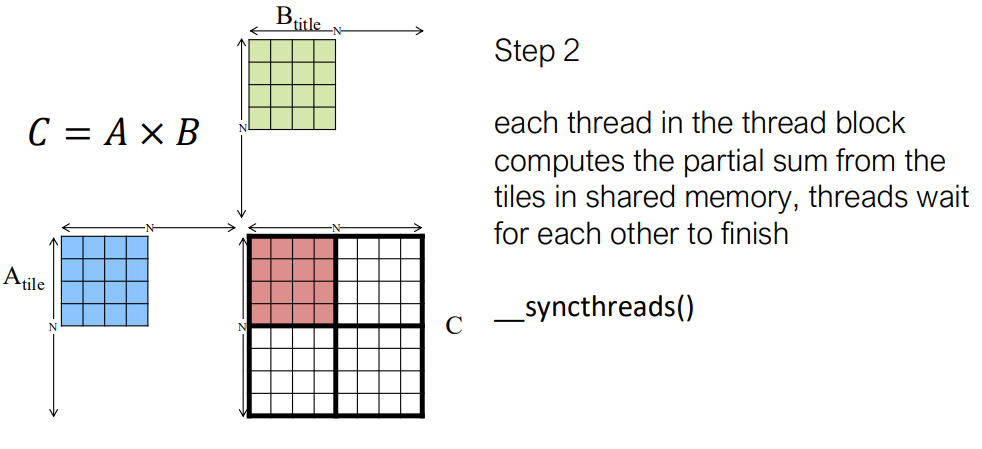
Tiling for Matrix Multiplication
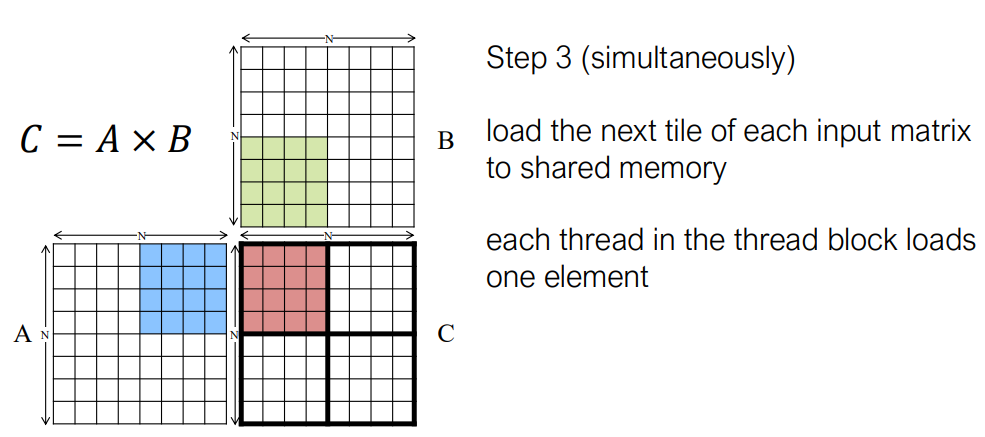
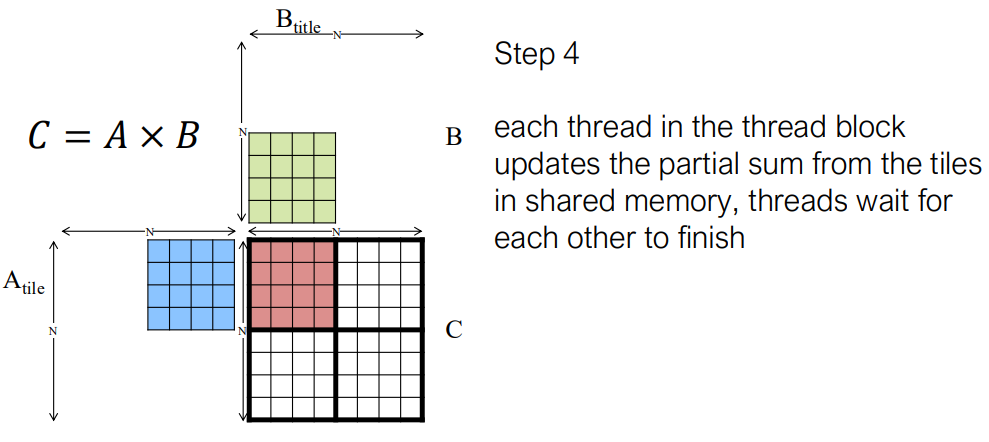
A implement in cuda cpp:
1 | __global__ void MatrixMultiplyKernel( |
Matrix Transpose on GPU: Coalescing, Shared Memory, and Bank Conflicts
A Coalesced Transpose Kernel
1 | __global__ void smem_cuda_transpose(int m, float* a, float* c) { |
What this fixes
✅ Global memory reads are coalesced ✅ Global memory writes are coalesced
But…
❌ Shared memory bank conflicts appear
Shared Memory Banks: The Real Bottleneck
- Shared memory is divided into 32 banks
- Each bank serves one 32-bit word per cycle
- A warp can access shared memory in 1 cycle only
if:
- Each thread accesses a different bank
smem[threadIdx.x][threadIdx.y] this code actually cause
the bank conflict.
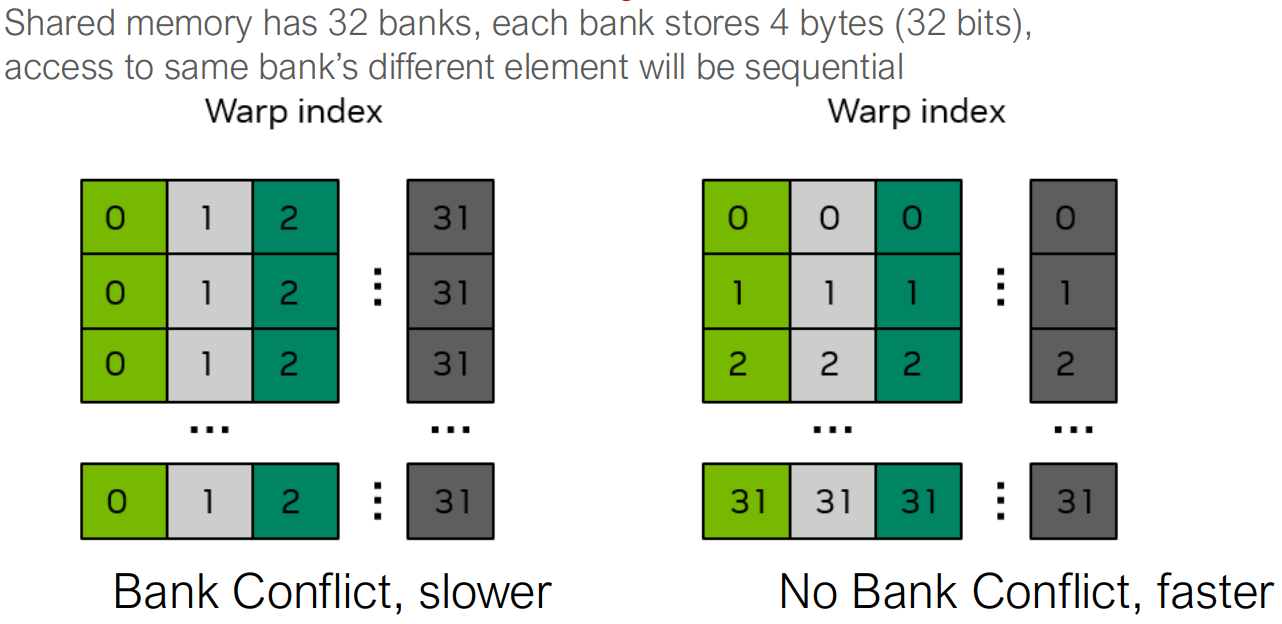
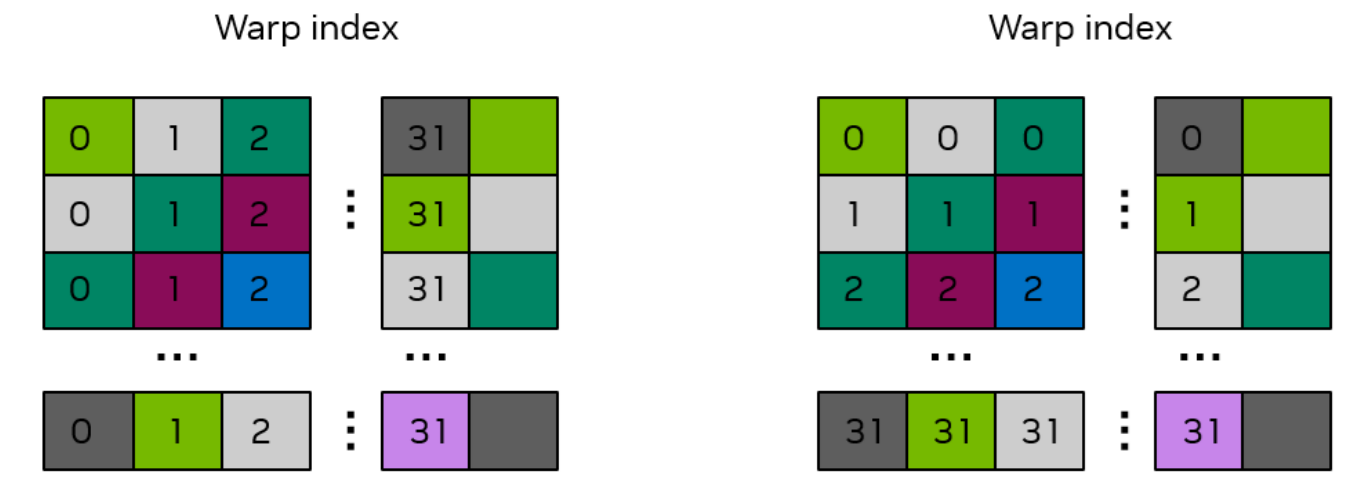
The Fix: Padding Shared Memory
1 | __global__ void smem_cuda_transpose(int m, float* a, float* c) { |
Sparse Matrix Multiplication
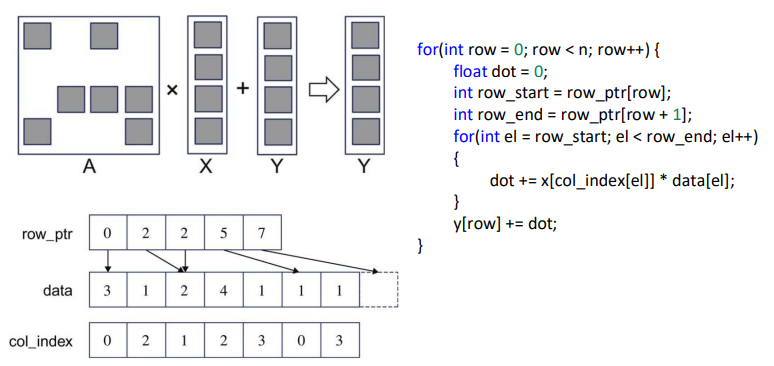
1 | __global__ void SpMVCSRKernel( |
cuBLAS
cuBLAS stands for CUDA Basic Linear Algebra Subroutines.
It is NVIDIA’s highly optimized GPU implementation of the classic BLAS interface, targeting operations such as:
- Vector operations (Level-1 BLAS)
- Matrix-vector operations (Level-2 BLAS)
- Matrix-matrix operations (Level-3 BLAS, especially GEMM)
Programming Model
cuBLAS uses a handle-based API:
1 | cublasHandle_t handle; |
All cuBLAS operations require a valid cublasHandle_t,
which stores execution context such as the CUDA stream and math
mode.
Level-1 BLAS: Vector Dot Product
Compute the dot product of two vectors: \[ \text{result} = x^T y \]
1 | cublasStatus_t cublasSdot( |
Key points:
nis the number of elementsincx,incyspecify the stride between elementsxandymust reside in device memoryresultis written to host memory
This is a basic building block for norms, projections, and reductions.
Level-2 BLAS: Matrix–Vector Multiplication
Compute: \[ y = \alpha A x + \beta y \]
1 | cublasStatus_t cublasSgemv( |
Key points:
Ais an \(m \times n\) matrix stored in column-major ordertranscontrols whetherAis transposedldais the leading dimension ofA- All vectors and matrices are in device memory
This operation is common in iterative solvers and neural network layers.
Level-3 BLAS: Matrix–Matrix Multiplication (GEMM)
Compute: \[ C = \alpha A B + \beta C \]
1 | cublasStatus_t cublasSgemm( |
Key points:
- This is the most important cuBLAS API
A,B,Care all stored in column-major layoutm,n,kdefine matrix shapes- Internally uses tiling, shared memory, and Tensor Cores (when available)
GEMM is the performance backbone of deep learning and scientific computing.

