
15618 Parallel Programming Lecture (1-4) Notes
[toc]
Lec 1 Why Parallelism? Why Efficiency?
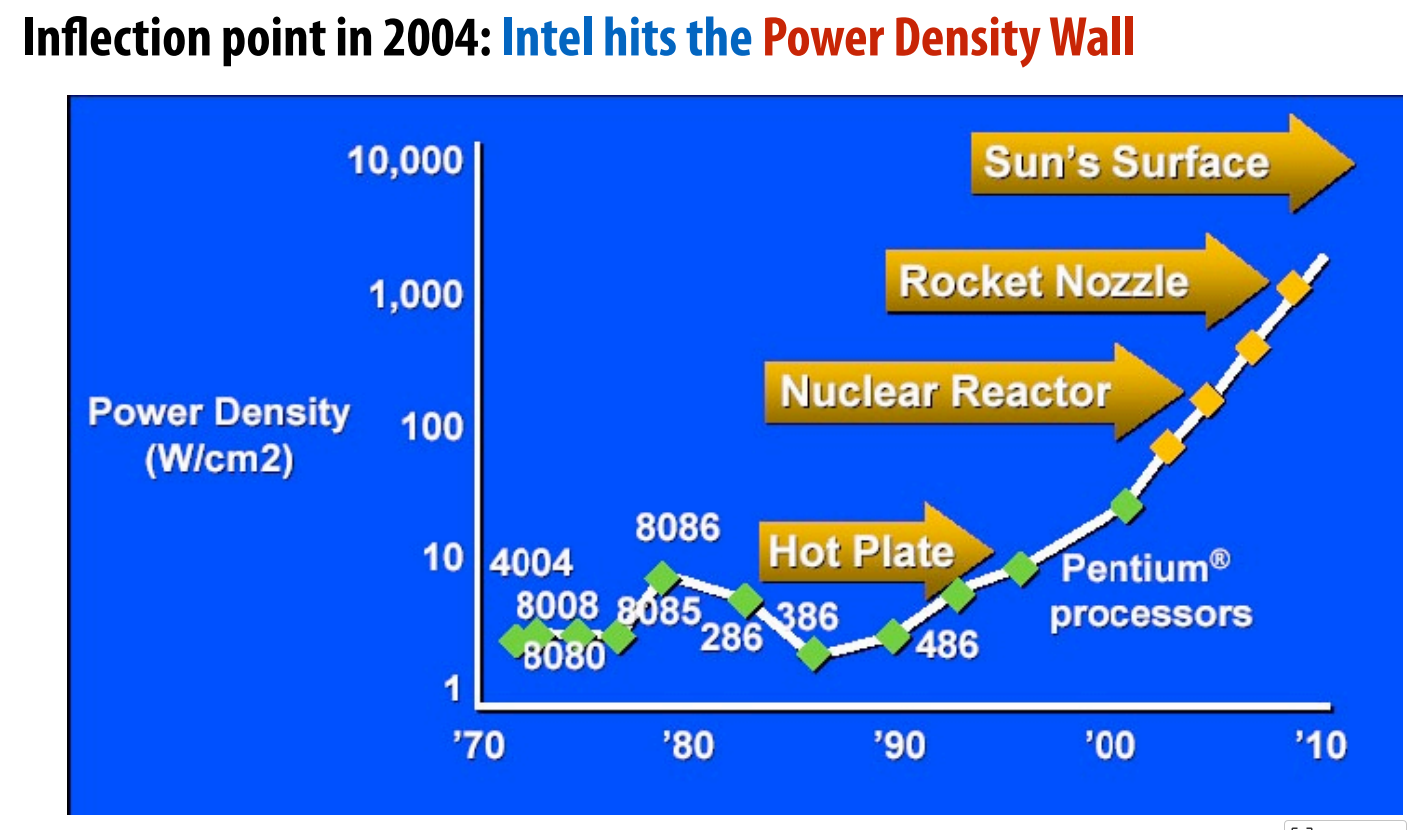
A brief history of processor performace
Wider data path (bits width)
More efficient pipelining (3.5 Cycles Per Instruction (CPI) → 1.1 CPI )
Instruction level parallelism(ILP) e.g., superscalar processing
Faster clock rates(most important) e.g., 10 MHz → 200 MHz → 3 GHz

What is a parallel computer?
A common definition:
A parallel computer is a collection of processing elements that cooperate to solve problems quickly. \[ Speedup(using\ P\ processors) = \frac{execution\ time (using\ 1\ processor)}{execution\ time (using\ P\ processors)} \] Some overservation of the speedup:
- Communication limited the maximum speedup achieved (may dominate a parallel computation)
- Minimizing the cost the communication improves speedup
- Imbalance in work assignment limited speedup
- Improving the distribution of work improved speedup
Shift in CPU Deisgn Philosophy
Maximize performace(ILP) -> Maximize performance per area (cpres/chip) -> Maximize performance per Watt
upshot: major focus on efficiency of cores
Lec 2 A Moredern Multi-Core Processor
Parallel execution
Compute sin(x) using Taylor expansion: sin(x) = x - x³/3! + x⁵/5! - x⁷/7! + …
1 | void sinx(int N, int terms, float* x, float* result) |
The idea to boost the efficiency of the progeam is as follows.
Multi Cores
Use increasing transistor count to add more cores to the processor
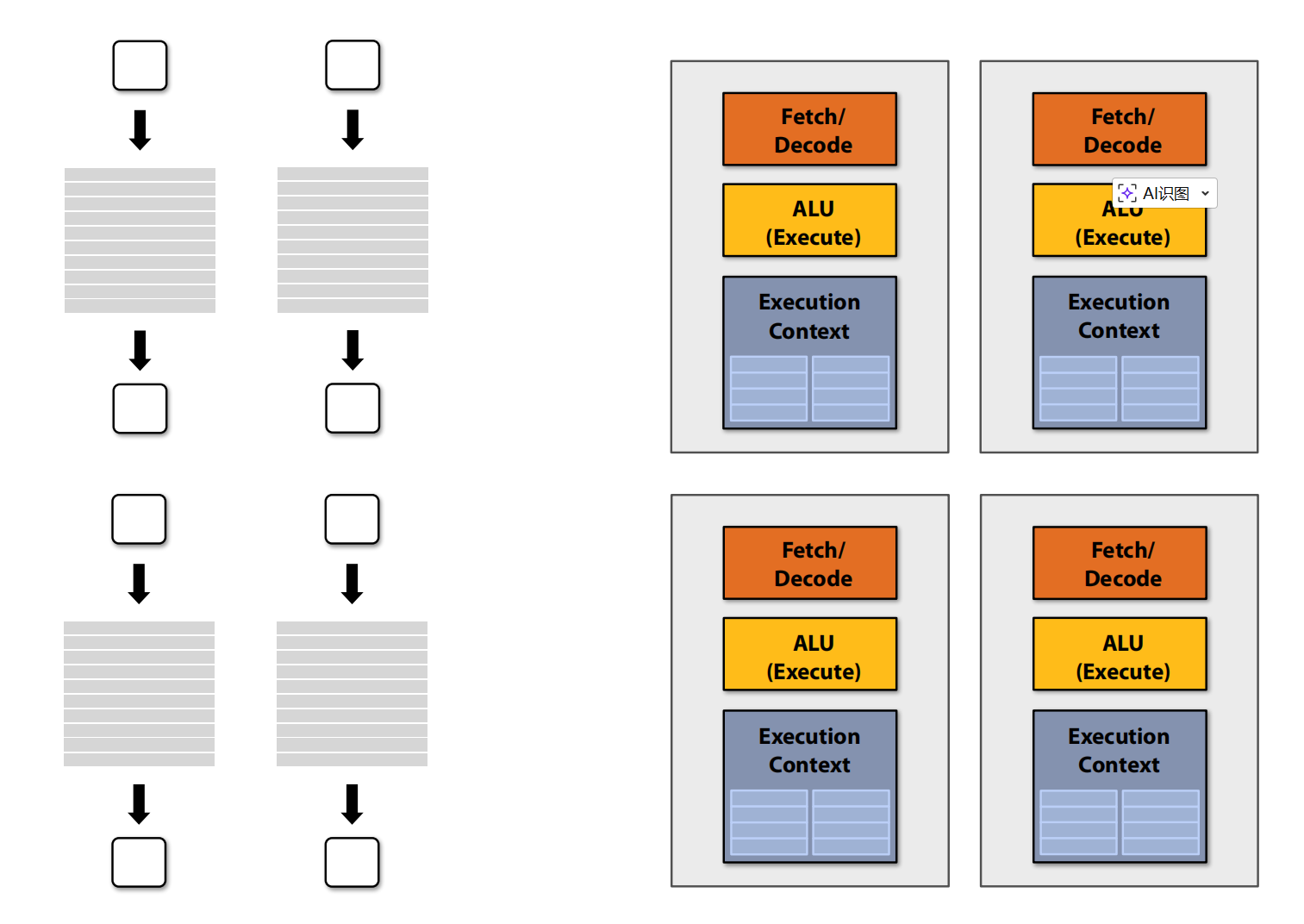
More ALUs
Amortize cost/complexity of managing an instruction stream across many ALUs
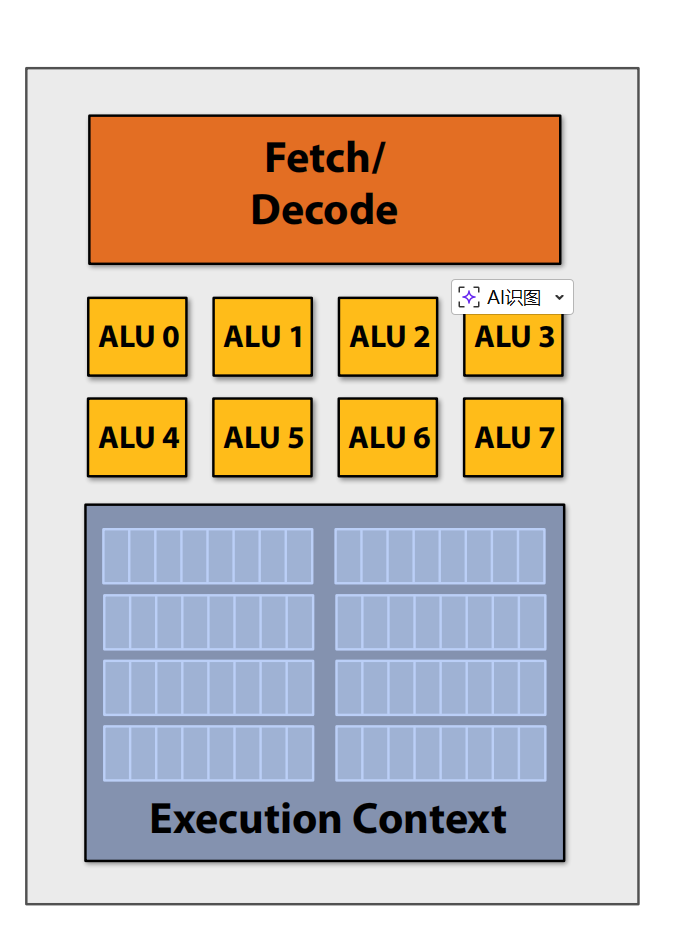
SIMD processing (Single instruction, multiple data): Same instruction broadcast to all ALUs and Executed in parallel on all ALUs
Scalar Program vs. Vector Program: Scalar: one operation per register. Vector: multiple operations per register using SIMD.
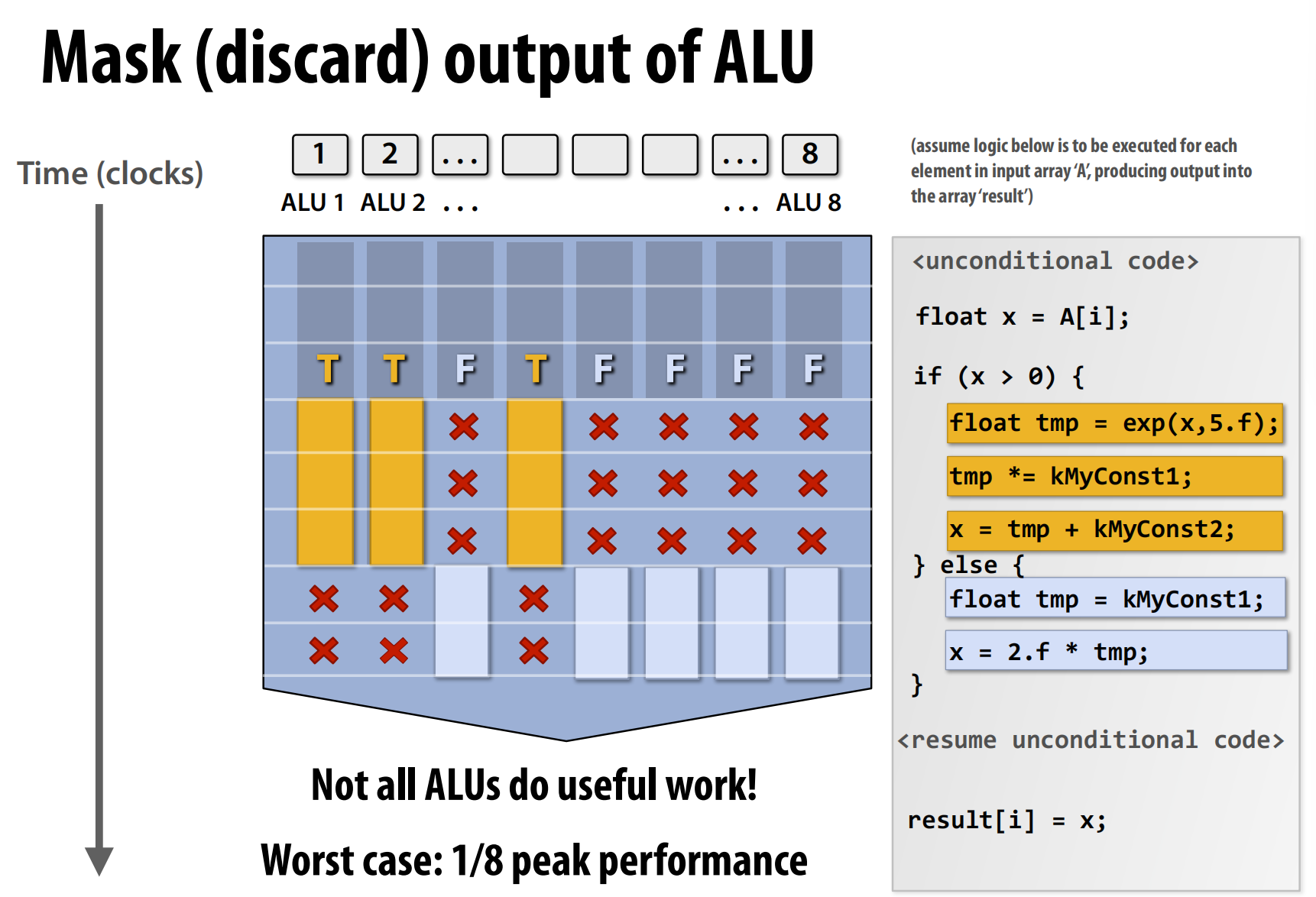
The picture above shows that conditional code(if - else) could recude the efficiency of multi ALUs architecture. Because only one instruction can be executed at a time in the same processor, so there may some ALUs are idle, we use mask to discard the output of some ALUs.
SIMD Terminology
Instruction Stream Coherence vs. Divergent Execution
- Coherent execution: All elements execute the same instruction sequence simultaneously (efficient for SIMD)
- Divergent execution: Different elements need different instruction paths (inefficient for SIMD, e.g., if-else branches)
SSE vs. AVX
- SSE: 128-bit operations (4-wide float vectors)
- AVX: 256-bit operations (8-wide float vectors)
Explicit SIMD vs. Implicit SIMD
- Explicit SIMD: Programmer explicitly writes SIMD code using intrinsics or parallel constructs; vectorization done at compile time
- Implicit SIMD (Auto-vectorization): Compiler automatically detects and converts scalar loops to SIMD instructions
Summary
Multi-core
- What: Multiple cores execute different threads simultaneously
- Control: Programmer creates threads (e.g., pthreads)
- Parallelism: Thread-level parallelism
SIMD
- What: Single instruction operates on multiple data elements
- Control: Compiler (explicit SIMD) or hardware (implicit)
- Parallelism: Data-level parallelism
Superscalar
- What: Multiple instructions from same thread execute in parallel
- Control: Hardware automatically discovers parallelism at runtime
- Parallelism: Instruction-level parallelism (ILP)
- Note: Not covered in this course (belongs to architecture courses like 18-447)
Accessing Memory
Stalls
A processor “stalls” when it cannot run the next instruction in an instruction stream because of a dependency on a previous instruction.

Ways to recude stalls:
Prefetching: All modern CPUs have logic for prefetching data into caches

Multi-Threading: Interleave processing of multiple threads on the same core to hide stalls
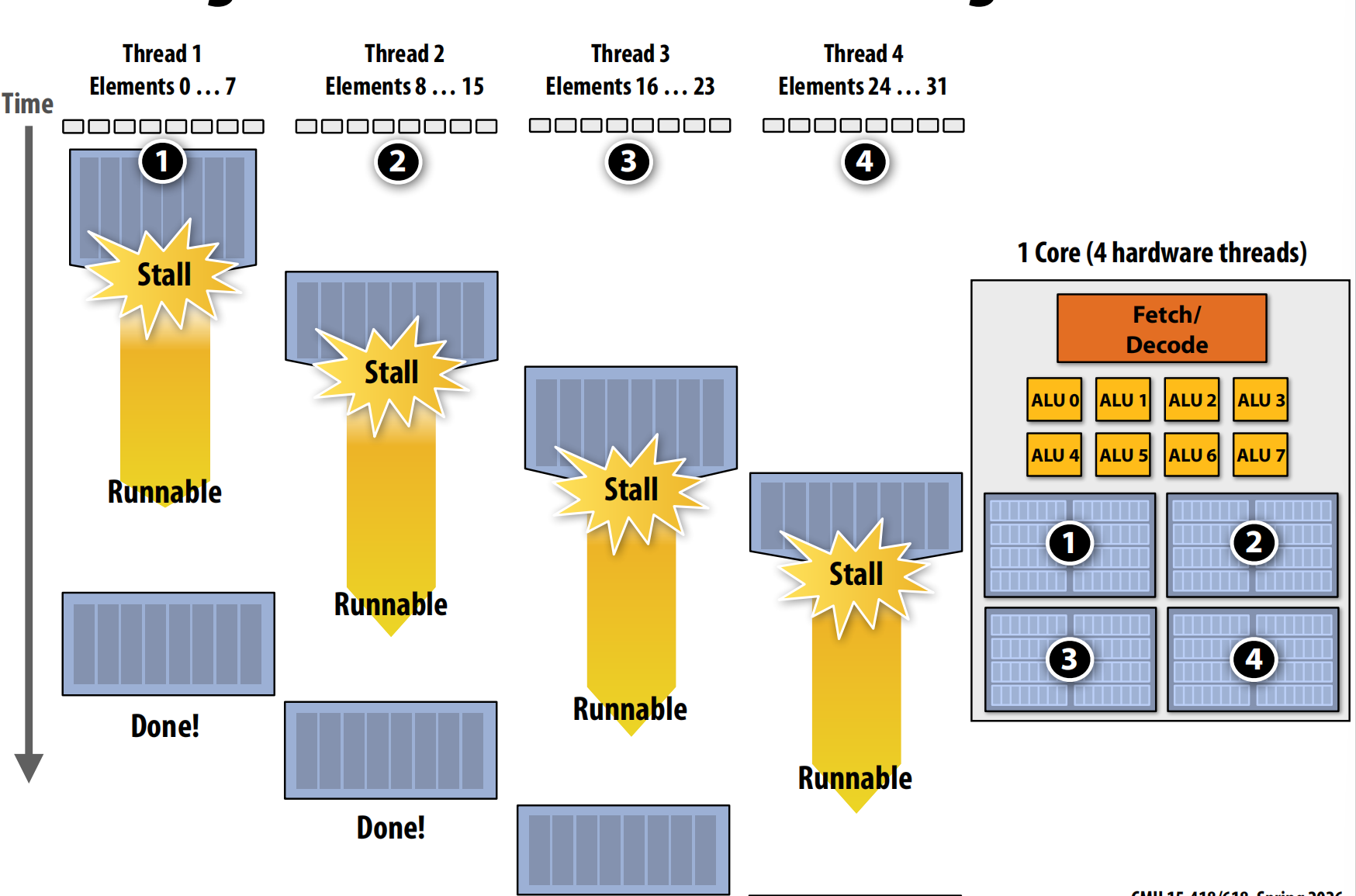
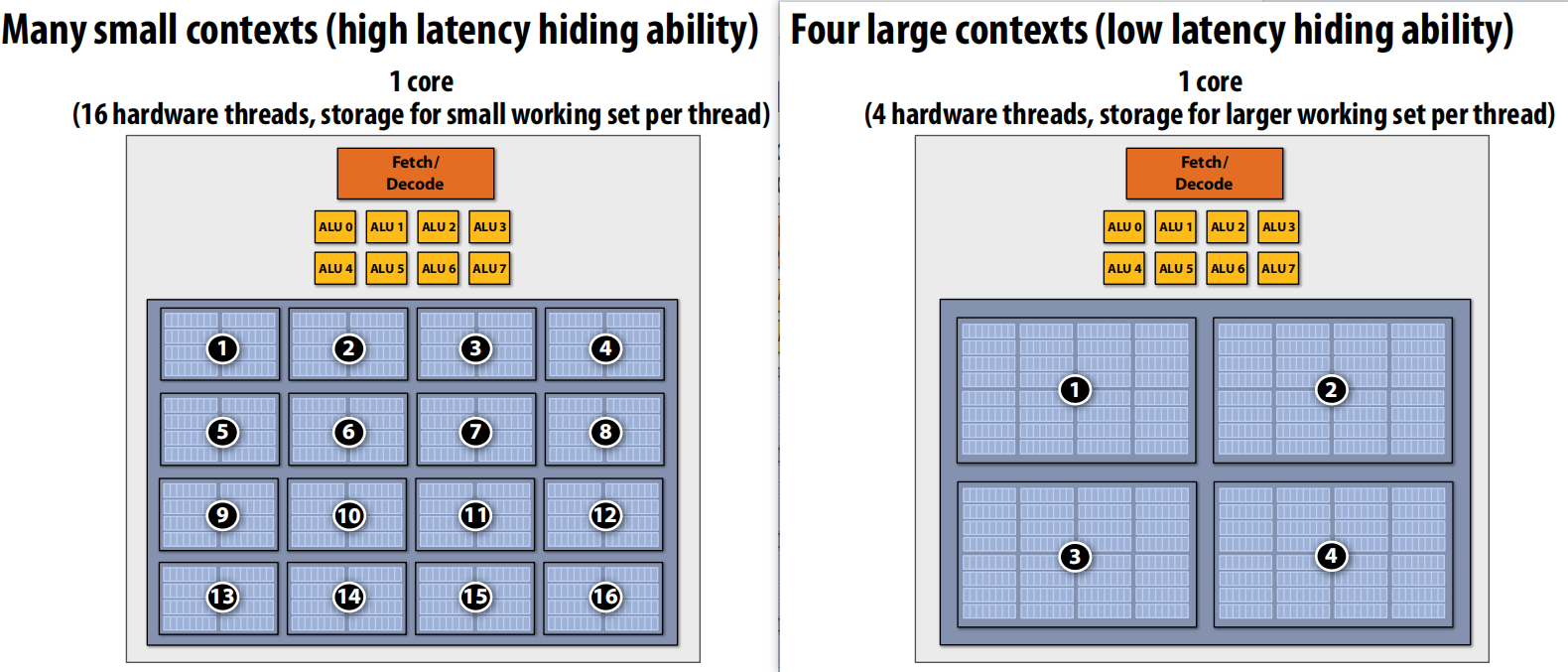
Core needs to manage execution context for multiple threads. And a example of count methods for different concepts.
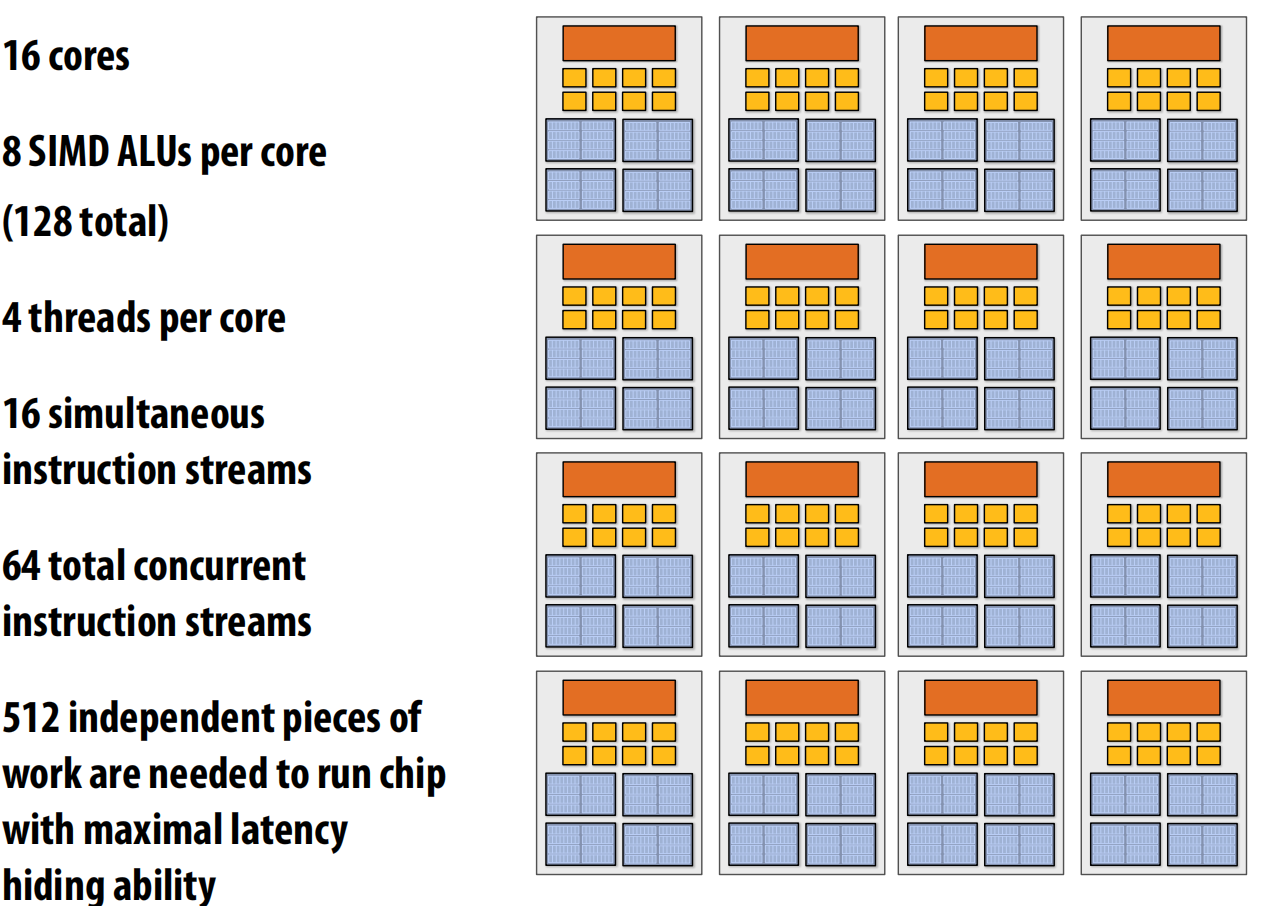
GPU vs. CPU
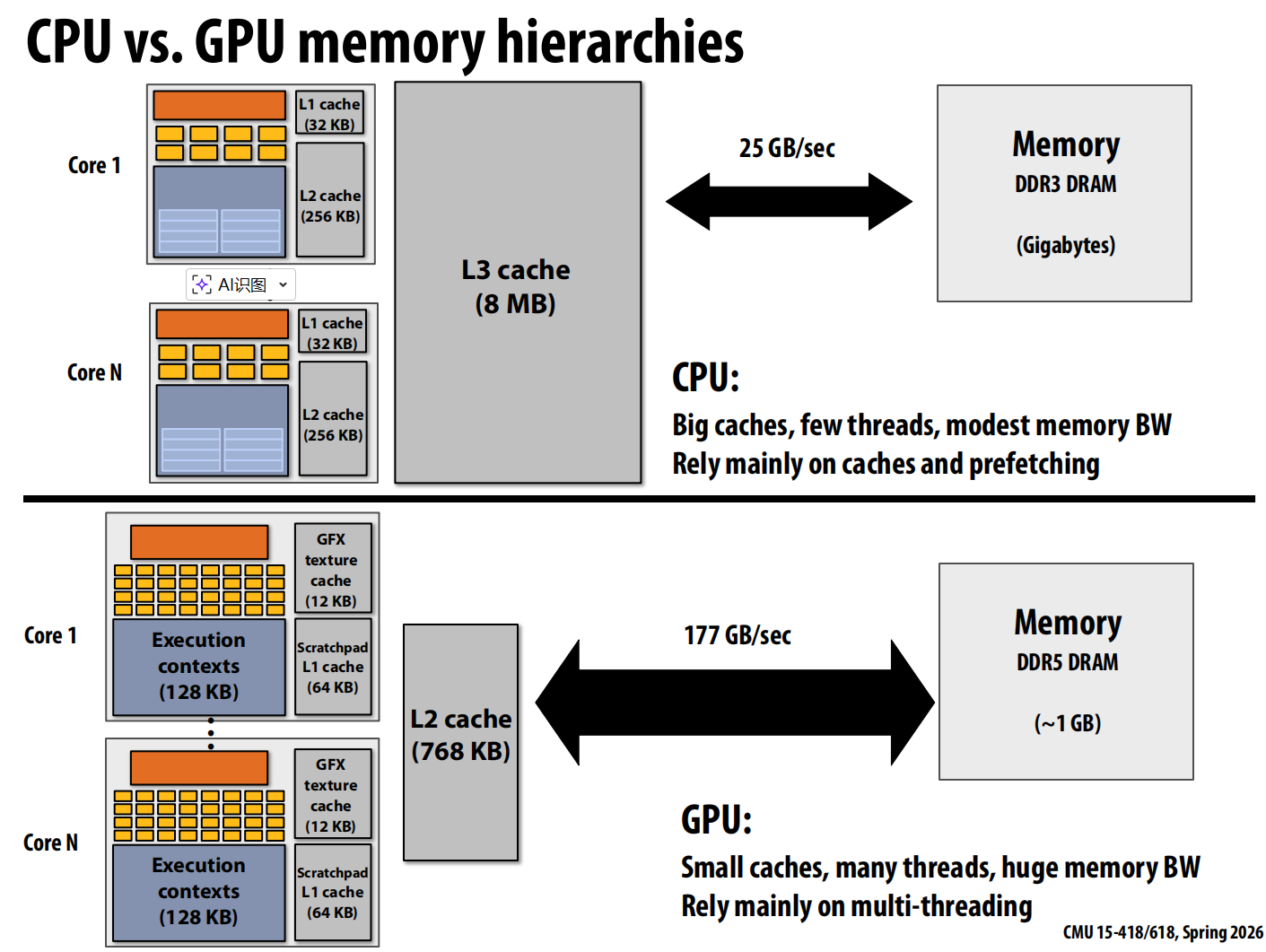
Bandwith Limited
Due to high arithmetic capability on modern chips, many parallel applications (on both CPUs and GPUs) are bandwidth bound.

Lec 3 Parallel Programming Abstractions
Intel SPMD Program Compiler (ISPC)
SPMD refers to single program multiple data, and call to ISPC function spawns “gang” of ISPC “programming instances (SIMD lanes)”. All instances run ISPC code concurrently.
Gang is the vector width level concept
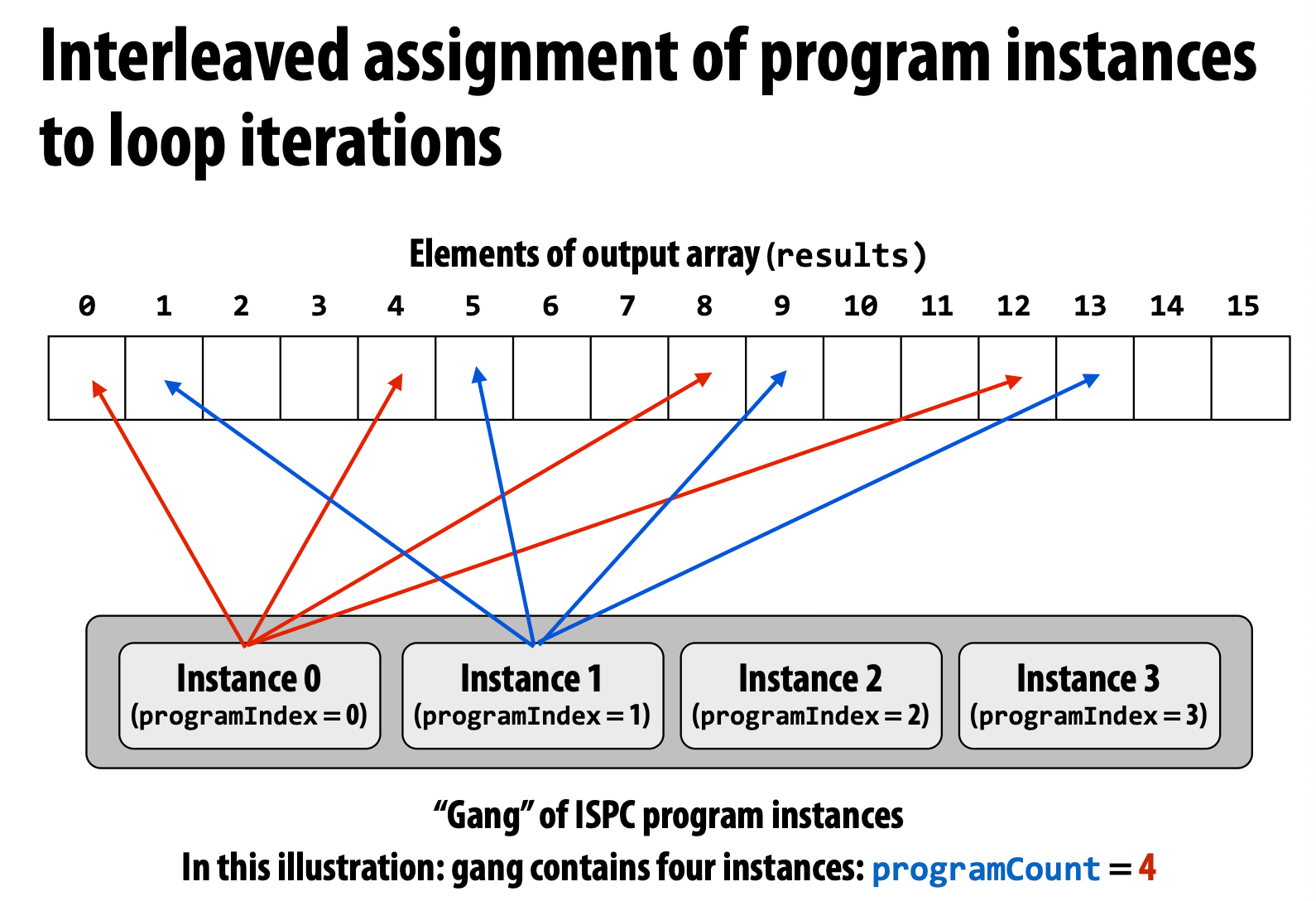
Interleaved Version

Blocked Version

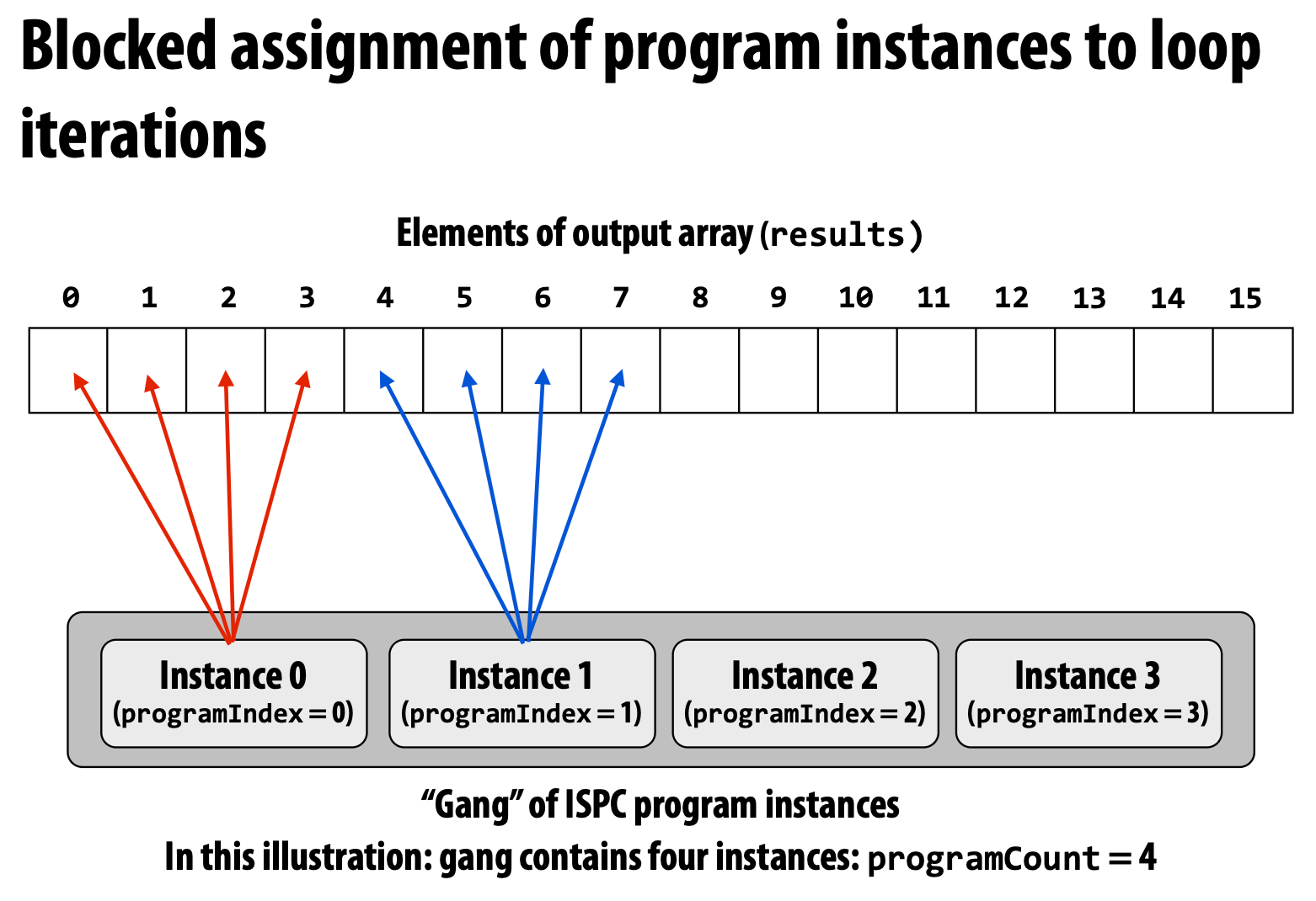
Which is faster? A: The interleaved one is faster.
The interleaved one use **_mm_load_ps1** to load these continuous data, but the blocked one need to use **_mm_i32gather**, which is more complex and slower.
For ISPC, we cannot add a varying number with a uniform number, and it will reject the code during the compile time.
Four models of communication
Shared address space: very little structure
Threads communicate by
- Reading/writing to shared variables.
- Manipulating synchronization primitives
Synchronization primitives are also shared variables. e.g., locks, semaphore
Hardware implementation of a shared address space
Key idea: any processor can directly inference any memory location
Symmetric (shared-memory) multi-processor(SMP) : uniform memory access time
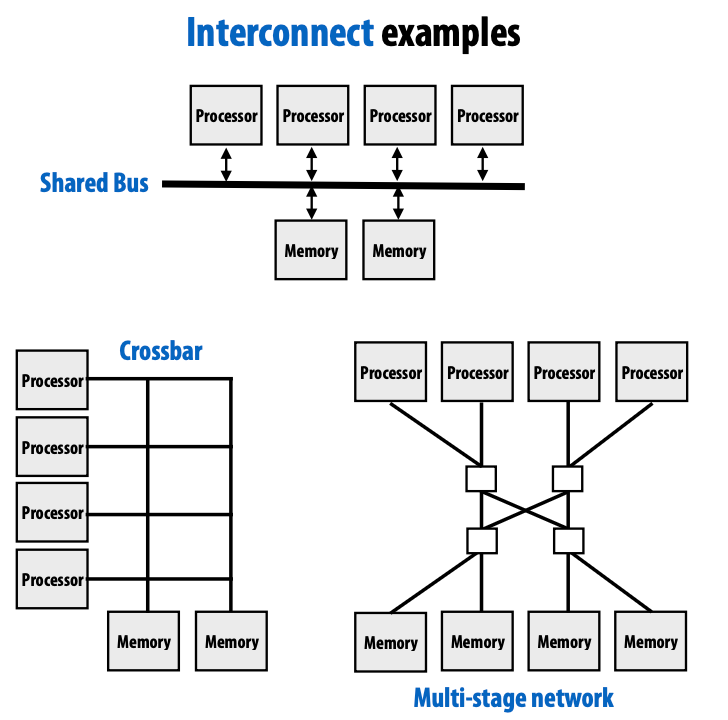
Non-uniform memory access(NUMA): All processors can access any memory location, but the cost of memory access is different for processors.

Uniform: costs are uniform but are uniformly bad
NUMA: more scalable
Message passing: highly structured communication
Threads operate within their own private space, and they communicate by sending/receiving messages
Popular software library: MPI(message passing interface)
Programming models and hardware architectures do not have a one-to-one correspondence: message passing can be implemented on shared-memory hardware, and shared-memory abstractions can be emulated on machines without hardware support, usually with performance trade-offs.
Data parallel: very rigid computation structure
Data-parallel programming maps independent computations over large data collections; by restricting communication and side effects, it enables simple reasoning and high-performance implementations, though irregular access patterns like gather/scatter are costly.

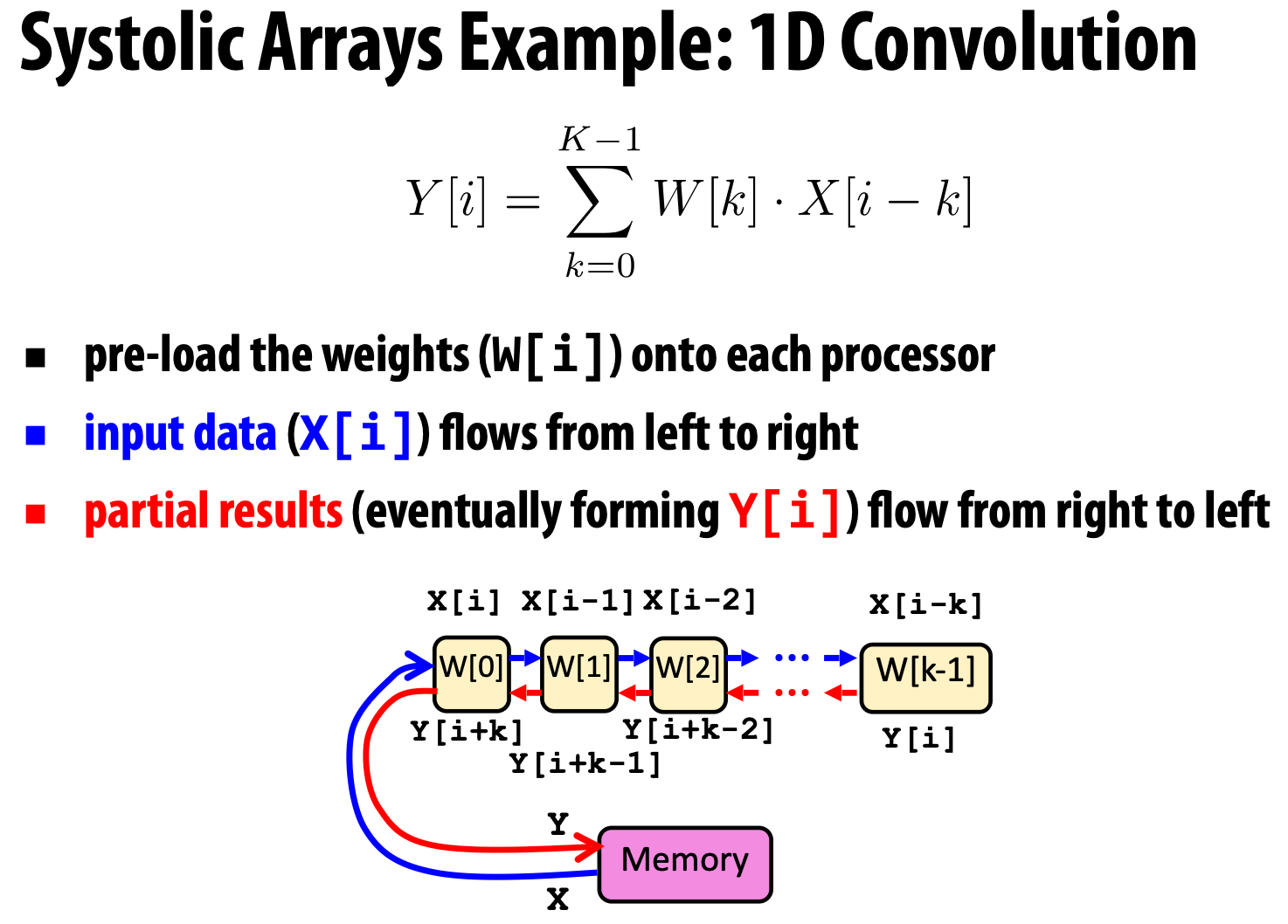
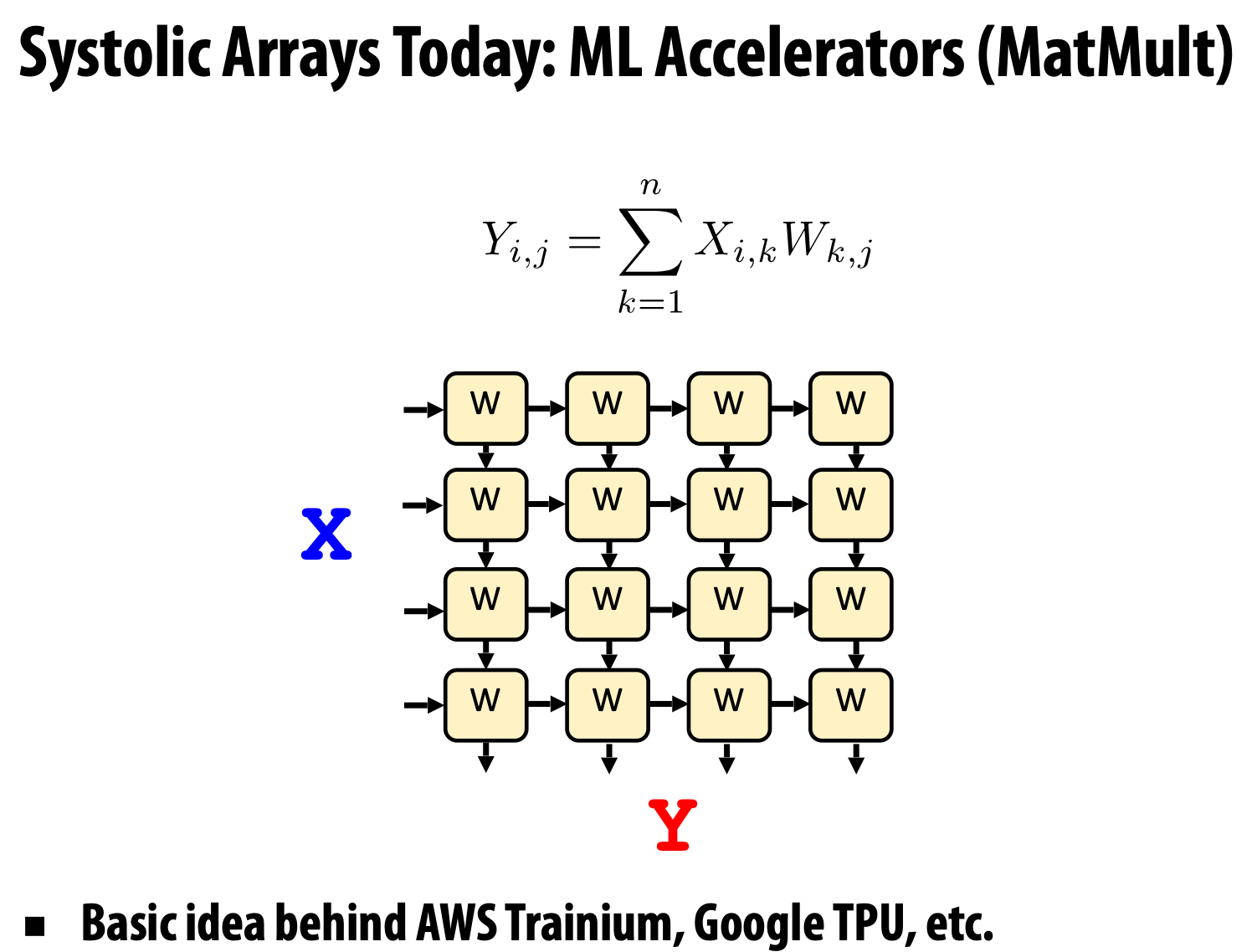
Systolic arrays
Target domain: data-intensive applications where memory bandwidth is the bottleneck.
And because the memory bandwidth is the critical resource, so we really want to avoid accessing memory unnecessarily. So we need to perform all necessary computation on the processor before writing back any results, usually by directly pipelining intermediate results between processors.
Modern practice: mixed programming models
Use shared address space programming within a multi-core node of a cluster, use message passing between nodes.
Lec 4 Parallel Programming Basics
Creating a parallel program
Thought process:
- Identify work that can be performed in parallel
- Partition work (and also data associated with the work)
- Manage data access, communication, and synchronization
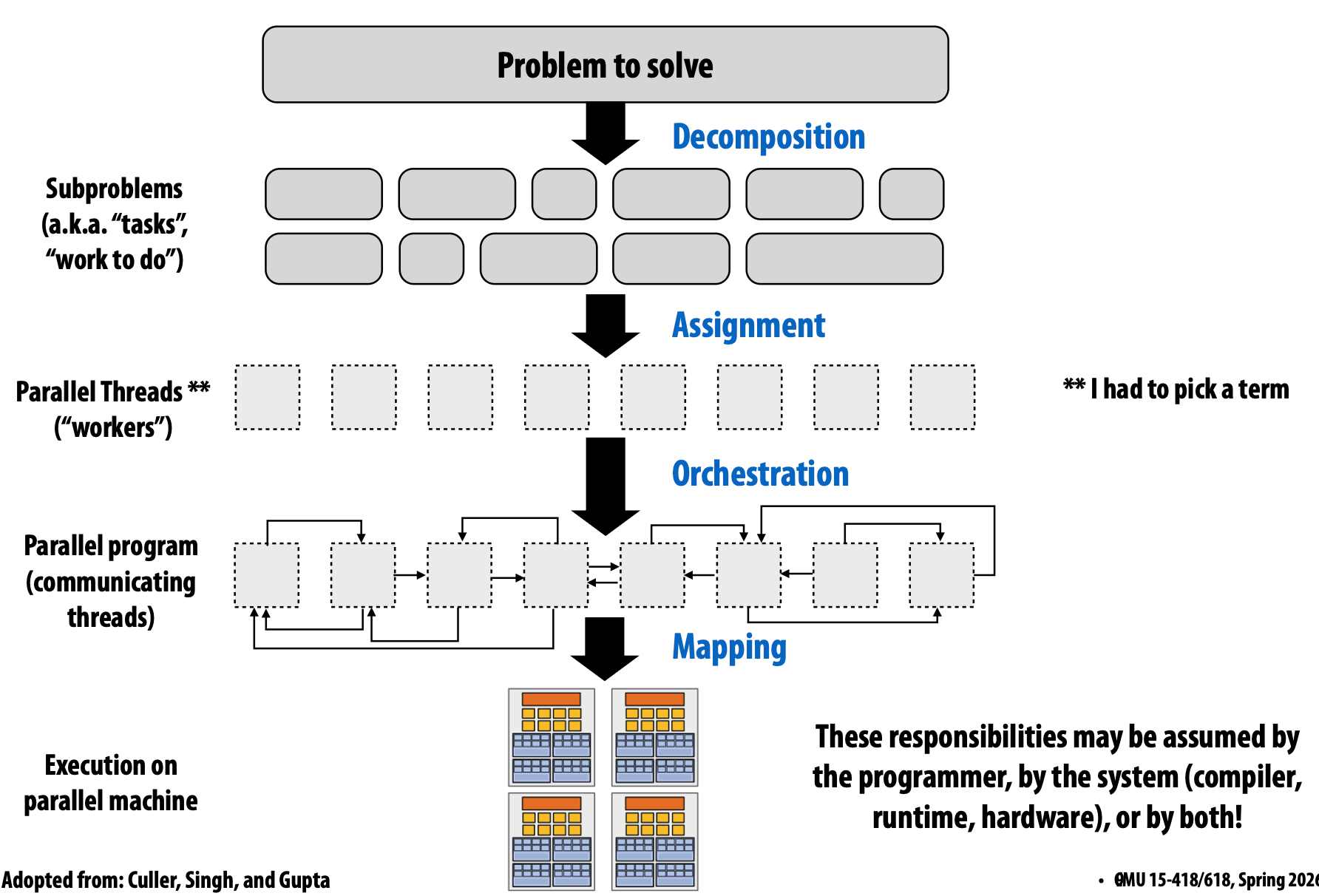
Decomposition
Break up problem into tasks that can be carried out in parallel
Main idea: Create at least enough tasks to keep all execution units on a machine busy.
Amdahl’s law: Dependencies limit maximum speedup due to parallelism. Then the maximum speed up due to parallel execution <= 1 / S. \[ \text{speedup} \leq \frac{1}{s + \frac{1-s}{p}} \]
Assignment
Assigning tasks to threads
Goals: balance workloadm reduce communication costs
Orchestration
- Structuring communication
- Adding synchronization to preserve dependencies if necessary
- Organizing data structures in memory
- Scheduling tasks
Goals: reduce costs of communication/sync, preserve locality of data reference, reduce overhead, etc.
Mapping to hardware
Mapping “threads”(“workerss”) to hardware execution units
- Mapping by the operating system (e.g., map pthread to HW execution contect on a CPU core)
- Mapping by the complier (Map ISPC program instances to vector instruction lanes)
- Mapping by the hardware (Map CUDA thread blocks to GPU cores)



